핵심 요약
바이트댄스(ByteDance)가 공개한 Seedance 2.0은 단순한 텍스트-비디오 변환을 넘어 오디오와 비디오를 동시에 생성하는 통합 멀티모달 확산 시스템이다. 이 모델은 텍스트, 이미지, 비디오, 오디오 등 네 가지 모달리티를 입력으로 받아 정교한 장면 계획과 샷 분할을 통해 영화 같은 결과물을 만들어낸다. 특히 비디오와 오디오 브랜치를 동시에 학습시켜 시각적 사건과 소리의 시간적 정렬을 획기적으로 개선한 것이 특징이다. Sora 2, Veo 3.1 등 경쟁 모델과 비교해 참조 기반 제어 능력이 뛰어나며 가상 프로덕션 시스템으로서의 가능성을 보여준다.
배경
확산 모델(Diffusion Models)의 기본 개념, 멀티모달 학습에 대한 이해, 트랜스포머 아키텍처
대상 독자
AI 영상 제작자, 멀티모달 모델 연구원, 가상 프로덕션 개발자
의미 / 영향
Seedance 2.0은 AI 영상 생성이 단순한 클립 제작 도구를 넘어 통합적인 가상 프로덕션 시스템으로 진화하고 있음을 보여준다. 특히 오디오와 비디오의 동시 생성 기술은 향후 영화 및 광고 제작 공정을 획기적으로 단축시킬 것으로 전망된다.
섹션별 상세
이미지 분석
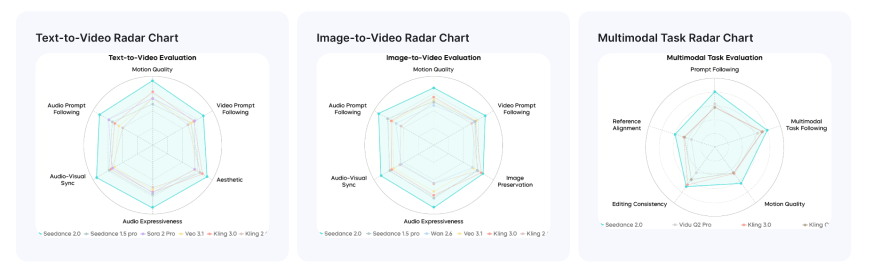
Seedance 2.0이 Sora 2 Pro, Veo 3.1, Kling 3.0 등 경쟁 모델 대비 모션 품질, 미적 요소, 오디오-비디오 동기화 등 여러 지표에서 우수한 성능을 보임을 시각적으로 증명한다. 특히 멀티모달 작업 수행 능력이 타 모델보다 월등히 높게 나타난다.
Seedance 2.0의 성능을 텍스트-비디오, 이미지-비디오, 멀티모달 작업별로 나타낸 레이더 차트.
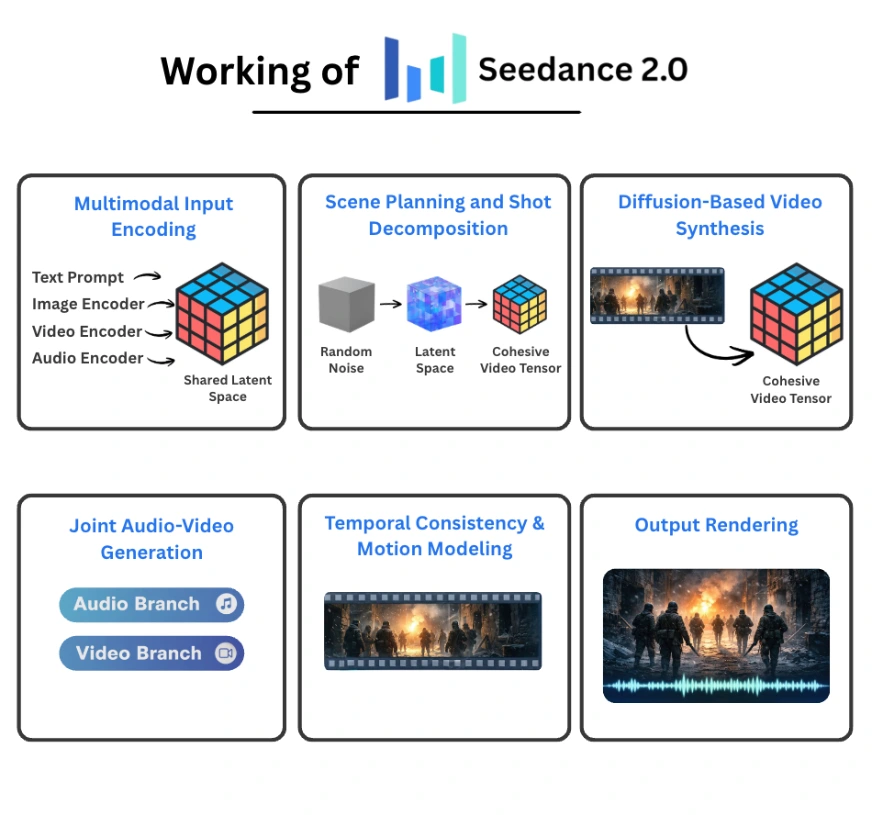
멀티모달 입력이 공유 잠재 공간으로 인코딩되고, 장면 계획을 거쳐 비디오와 오디오가 공동 생성되는 전체 파이프라인 구조를 보여준다. 기사에서 설명하는 기술적 아키텍처를 이해하는 데 핵심적인 역할을 한다.
Seedance 2.0의 작동 원리를 6단계(입력 인코딩, 장면 계획, 확산 합성 등)로 설명하는 다이어그램.
실무 Takeaway
- 비디오와 오디오를 별도로 생성해 결합하는 방식 대신 동시 생성 아키텍처를 채택하여 프레임 단위의 정밀한 오디오-비디오 동기화를 달성했다.
- 단순 프롬프트 입력을 넘어 이미지와 오디오를 참조 데이터로 활용함으로써 창작자가 조명, 스타일, 움직임을 더욱 세밀하게 제어할 수 있다.
- 내부적인 장면 계획 레이어를 통해 컷 전환 시 발생하기 쉬운 캐릭터 정체성 상실 문제를 해결하고 영화적인 연출을 가능하게 했다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료