핵심 요약
2026년 초 오픈 웨이트 LLM 시장은 아키텍처 혁신을 통해 폐쇄형 모델과의 간극을 좁히고 있습니다. 이 분석은 Arcee AI의 Trinity Large부터 Cohere의 Tiny Aya까지 최근 출시된 10개 모델의 기술적 세부 사항을 대조합니다. 특히 Mixture-of-Experts(MoE)의 세분화, Gated DeltaNet 기반의 하이브리드 어텐션 도입, Multi-Token Prediction(MTP)을 통한 효율성 개선이 핵심 트렌드로 확인됩니다. 모델 성능은 아키텍처 설계보다 데이터 품질과 학습 레시피에 크게 의존하는 경향을 보이며, 개발자들은 추론 비용 절감을 위한 다양한 기술적 변주를 시도하고 있습니다.
배경
Transformer 아키텍처, Mixture of Experts(MoE) 원리, Attention 메커니즘(GQA, SWA), LLM 벤치마크 지표 이해
대상 독자
LLM 아키텍처 설계자, AI 연구원 및 고성능 모델 배포를 담당하는 엔지니어
의미 / 영향
오픈 웨이트 모델들이 아키텍처 혁신을 통해 폐쇄형 모델의 성능 임계치에 도달하고 있으며, 특히 하이브리드 어텐션 기술의 발전으로 롱 컨텍스트 처리와 온디바이스 추론 효율성이 비약적으로 향상될 것입니다.
섹션별 상세
이미지 분석
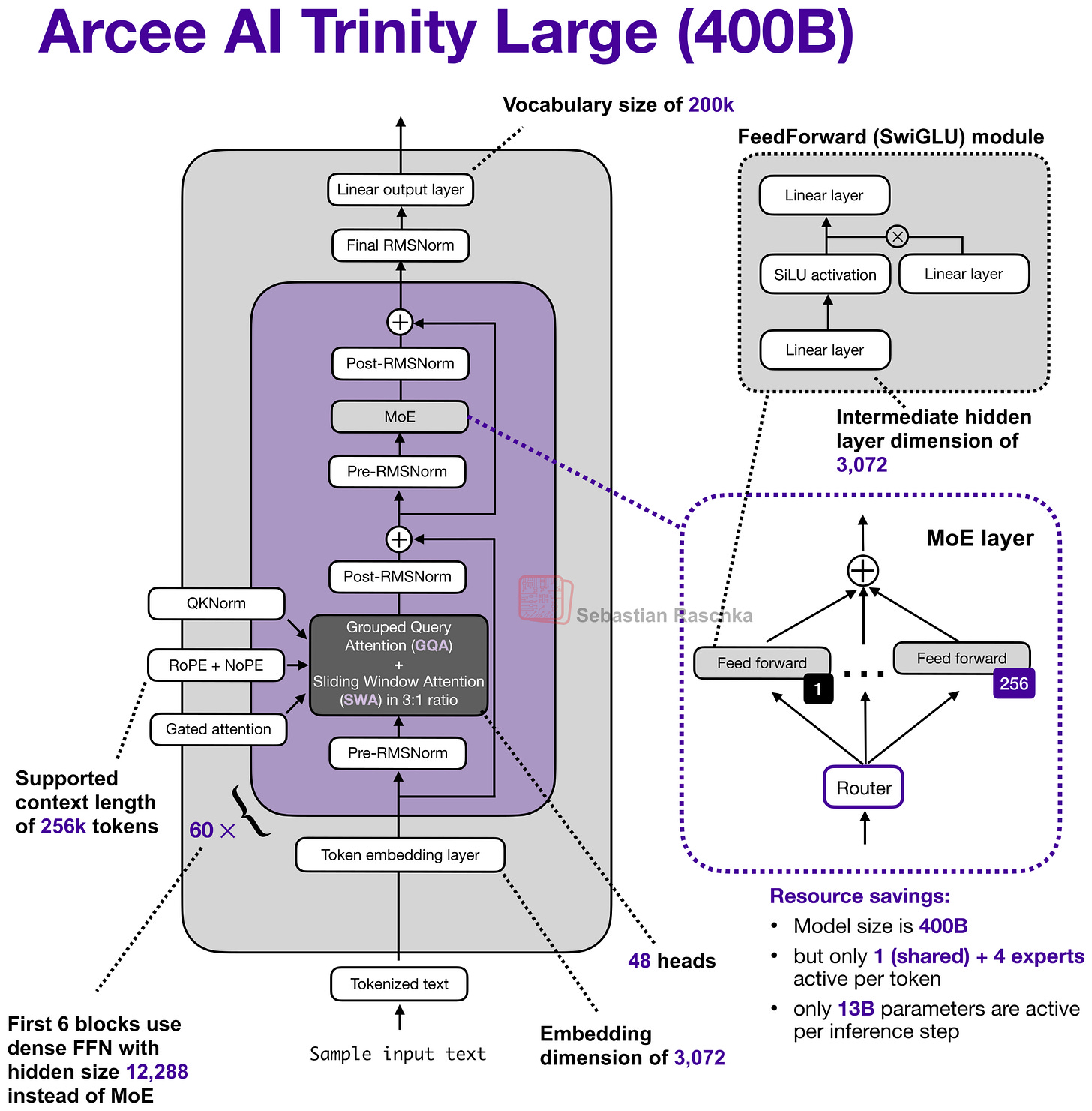
MoE 레이어, GQA 및 SWA가 결합된 구조를 시각화합니다. 임베딩 차원 3072와 256k 컨텍스트 지원 등 구체적인 하이퍼파라미터 정보를 제공합니다.
Trinity Large 모델의 전체 아키텍처 다이어그램
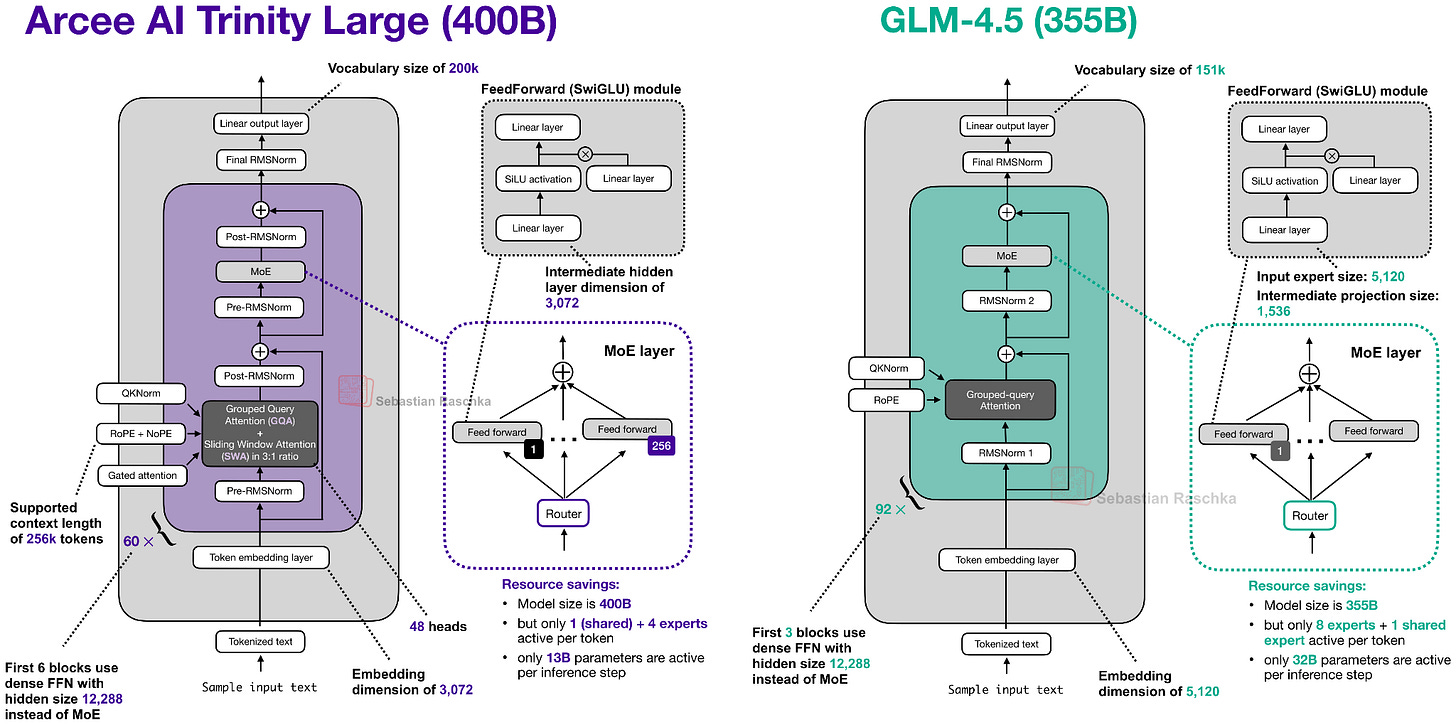
비슷한 규모의 두 모델 간 RMSNorm 배치와 레이어 수 차이를 대조합니다. Trinity가 더 복잡한 어텐션 메커니즘을 사용함을 보여줍니다.
Trinity Large와 GLM-4.5 아키텍처 비교
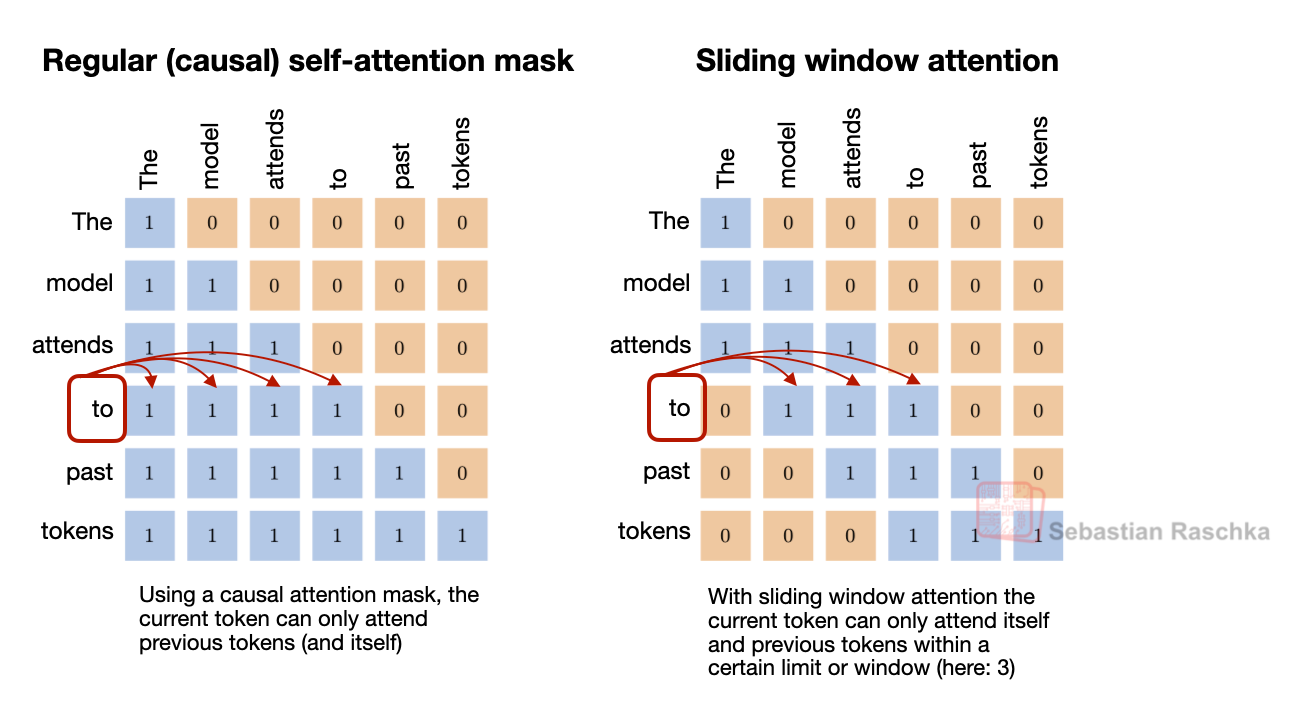
SWA가 특정 윈도우 내의 토큰에만 집중하여 연산 복잡도를 O(n^2)에서 O(n*t)로 줄이는 원리를 행렬 형태로 명확히 설명합니다.
일반 어텐션 마스크와 슬라이딩 윈도우 어텐션 마스크 비교
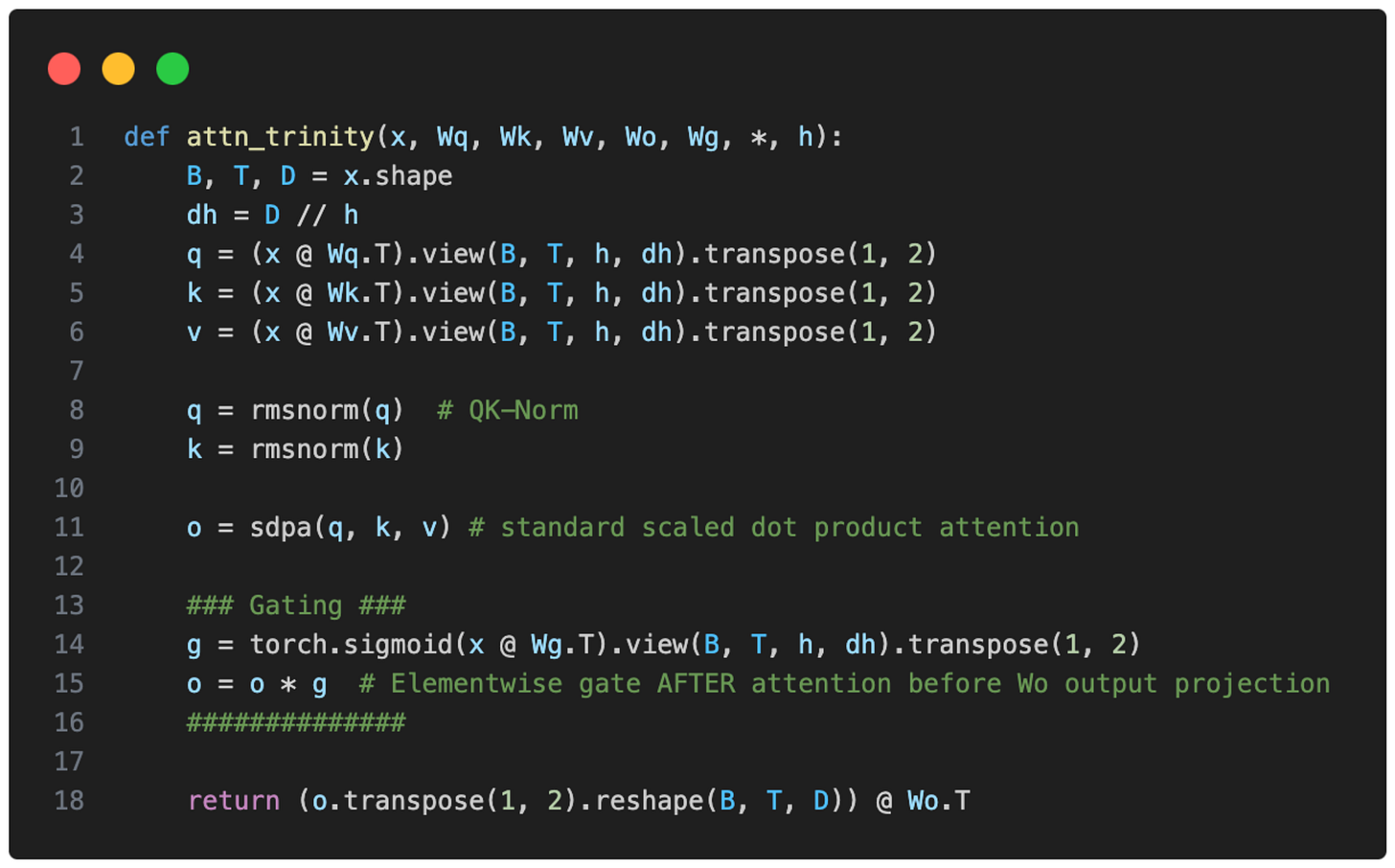
QK-Norm 적용 후 표준 어텐션 결과에 시그모이드 게이팅을 수행하는 과정을 PyTorch 코드로 보여주어 기술적 이해를 돕습니다.
Trinity Large의 Gated Attention 구현 코드 스니펫
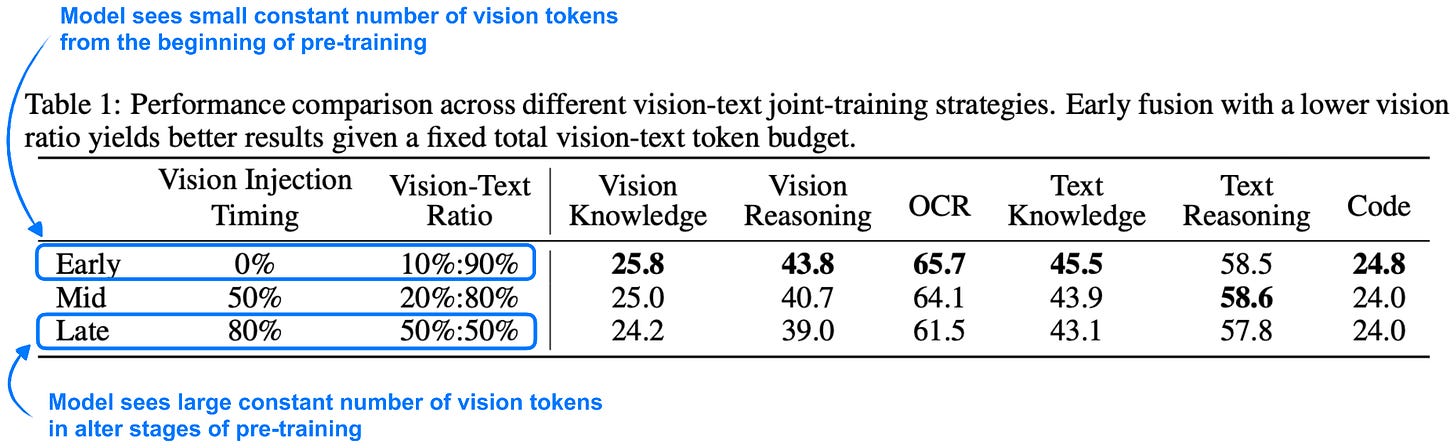
학습 초기(Early)에 적은 비율의 시각 토큰을 노출하는 것이 지식 및 추론 벤치마크에서 가장 좋은 결과를 냄을 수치로 증명합니다.
시각 토큰 주입 시점 및 비율에 따른 성능 비교 표
실무 Takeaway
- 추론 효율성 중심의 설계: MLA, Sparse Attention, Gated DeltaNet 등 선형 시간 복잡도를 지향하는 어텐션 변형 기법들이 대형 모델의 표준으로 자리 잡고 있습니다.
- MoE 구조의 고도화: DeepSeek 스타일의 세분화된 전문가 구조와 공유 전문가(Shared Expert) 활용이 모델 규모와 상관없이 성능 향상의 핵심 요소로 작용합니다.
- 멀티 토큰 예측(MTP)의 실용화: 학습 가속화를 넘어 추론 속도 개선을 위해 MTP를 도입하는 사례가 늘어나며 실시간 서비스 적합성이 높아지고 있습니다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료