핵심 요약
2026년 1월과 2월 사이 오픈 웨이트(Open-weight) LLM 시장은 전례 없는 기술적 진보를 보여주었습니다. 이 글은 Arcee AI의 Trinity Large부터 Cohere의 Tiny Aya까지 10가지 주요 모델의 아키텍처를 심층 비교합니다. 특히 Mixture-of-Experts(MoE), Multi-head Latent Attention(MLA), 그리고 Gated DeltaNet과 같은 하이브리드 어텐션 기법이 주류로 자리 잡으며 추론 효율성과 성능을 동시에 확보하려는 업계의 노력을 조명합니다. 모델 성능은 아키텍처 자체보다 데이터 품질과 학습 레시피에 크게 의존하지만 기술적 최적화는 여전히 핵심적인 차별화 요소입니다.
배경
Transformer Architecture, Mixture-of-Experts (MoE), Attention Mechanisms, LLM Training Basics
대상 독자
LLM 아키텍처 설계자 및 AI 연구원
의미 / 영향
오픈 웨이트 모델들이 폐쇄형 모델의 성능을 빠르게 추격하고 있으며 특히 코딩과 다국어 지원 그리고 추론 효율성 측면에서 독자적인 기술 혁신을 주도하고 있습니다.
섹션별 상세
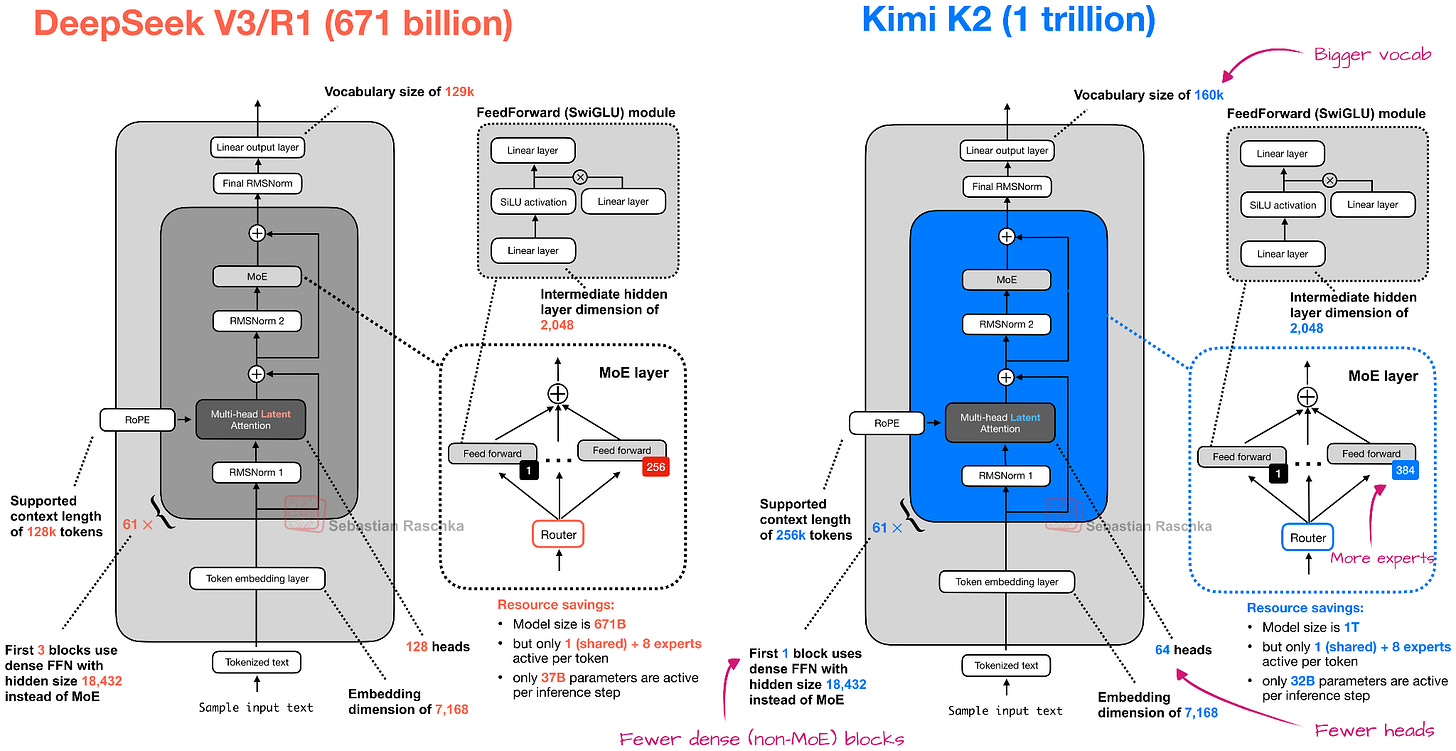
이미지 분석
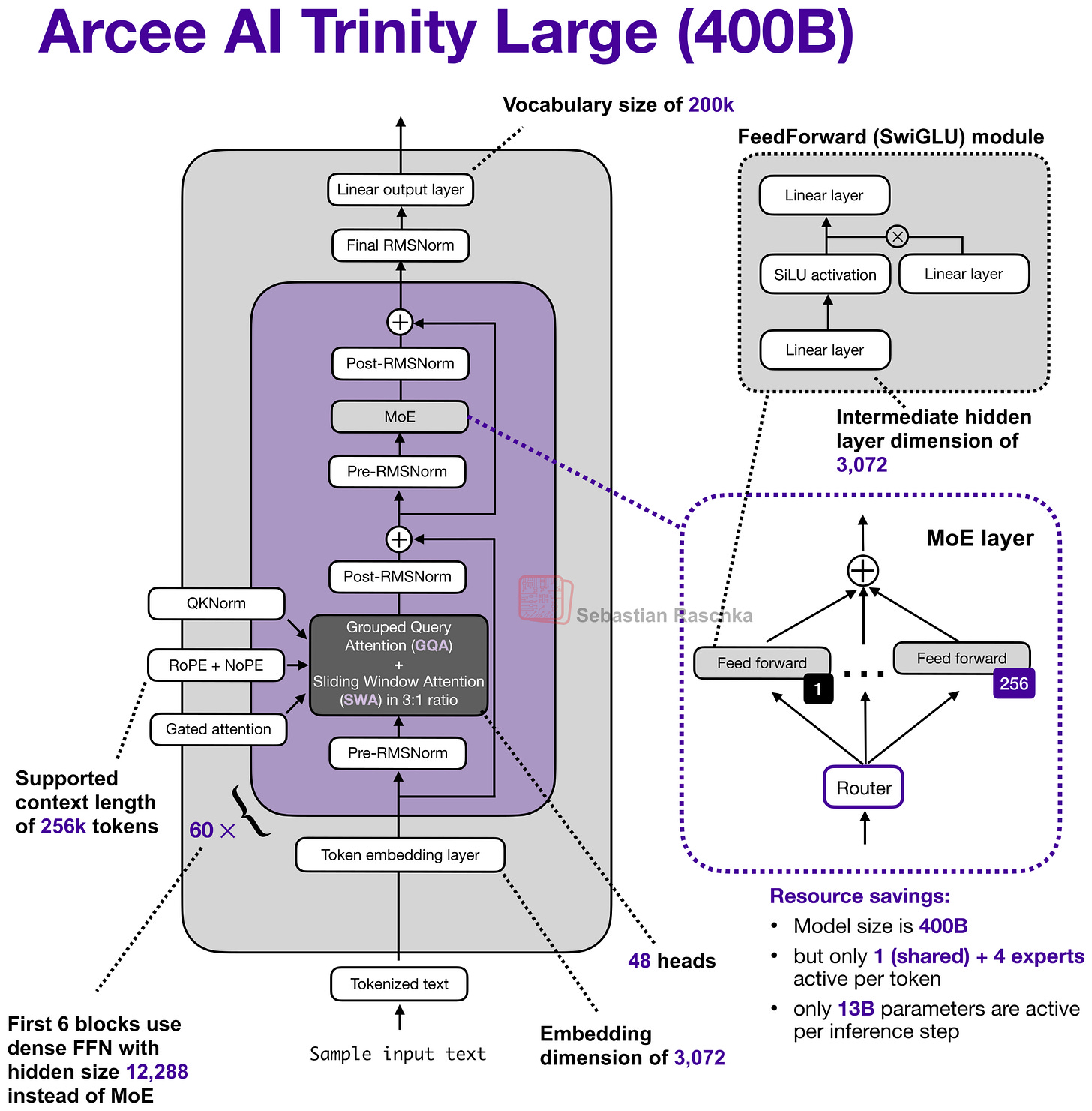
MoE 레이어와 GQA 및 SWA 구조를 상세히 보여주는 아키텍처 설계도입니다. 400B 모델의 전체적인 레이어 구성과 활성 파라미터 계산 방식을 시각적으로 설명합니다.
Arcee AI Trinity Large 아키텍처 다이어그램
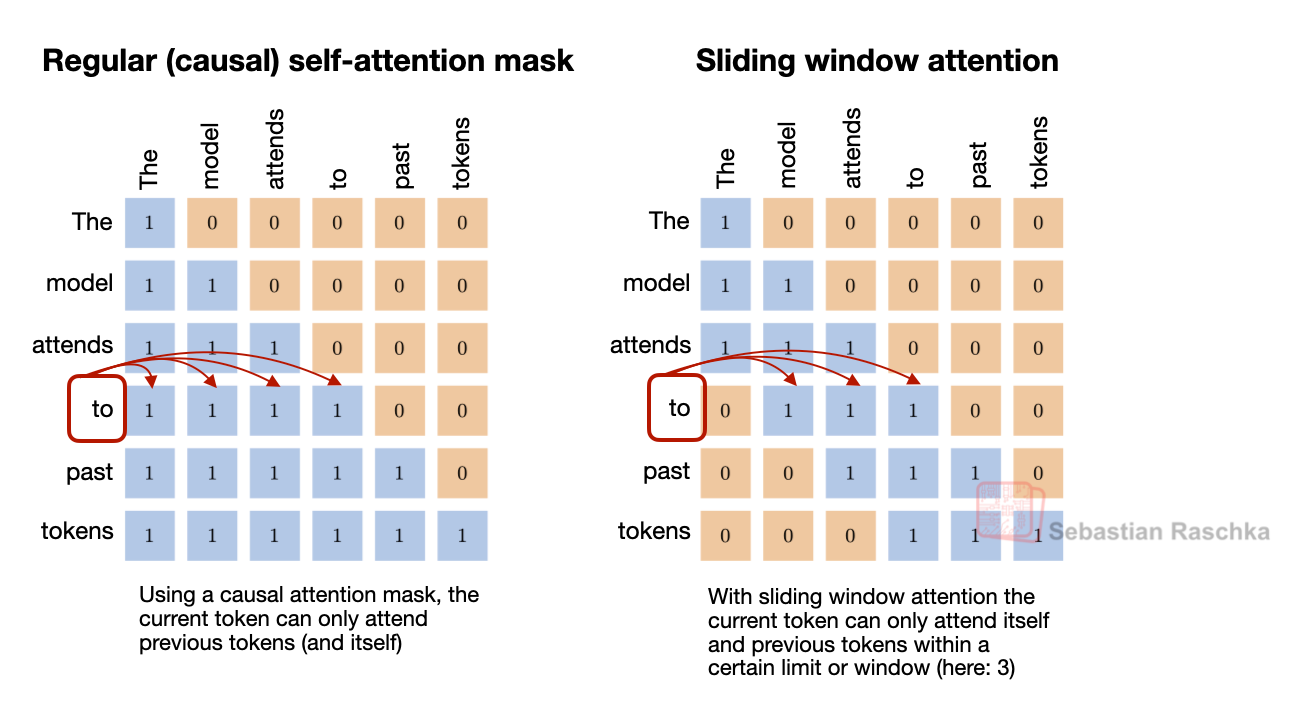
모든 토큰을 참조하는 글로벌 어텐션과 특정 윈도우 내 토큰만 참조하는 로컬 어텐션의 차이를 마스크 행렬로 시각화합니다. SWA가 긴 시퀀스에서 연산량을 어떻게 줄이는지 보여줍니다.
일반 어텐션과 슬라이딩 윈도우 어텐션(SWA) 비교
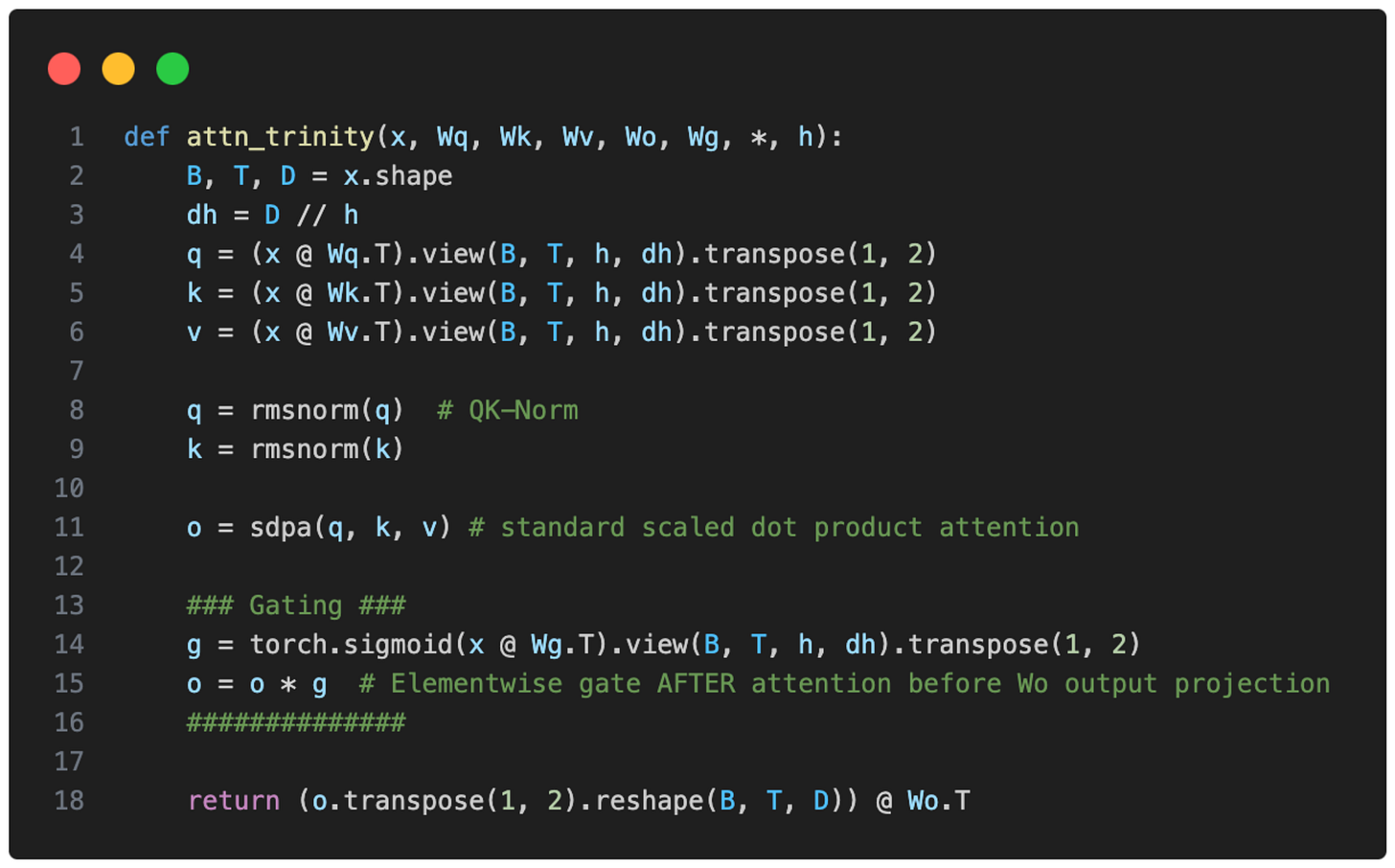
PyTorch 코드로 구현된 어텐션 게이팅 방식을 보여줍니다. 표준 스케일드 닷 프로덕트 어텐션 이후에 시그모이드 게이트를 적용하여 학습 안정성을 높이는 과정을 설명합니다.
Trinity의 Gating 메커니즘 코드 스니펫
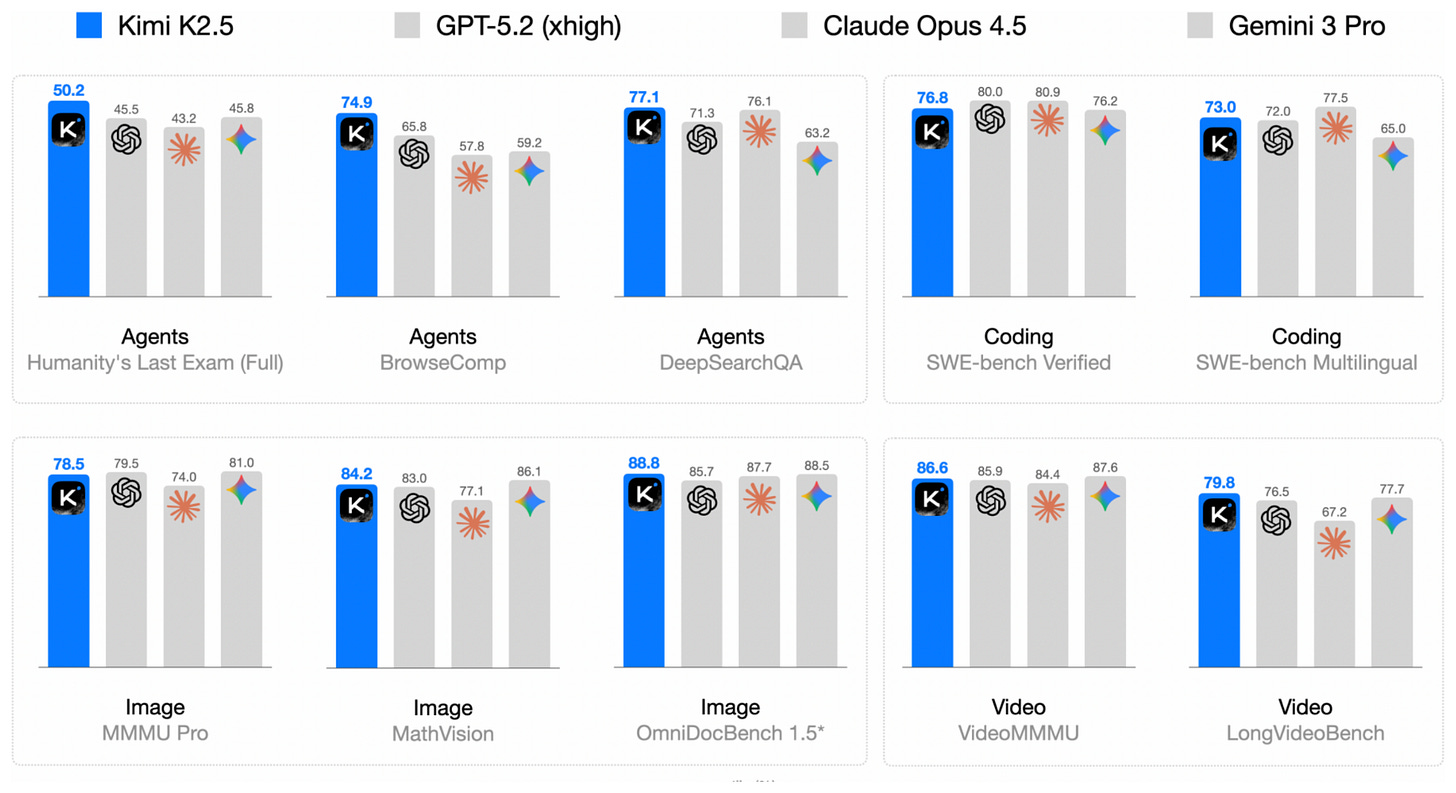
Kimi K2.5 모델이 GPT-5.2나 Claude 4.5 등 주요 상용 모델들과 비교하여 에이전트 및 코딩 작업에서 대등한 성능을 보임을 증명하는 데이터입니다.
Kimi K2.5 벤치마크 결과 차트
다음 토큰 하나가 아닌 여러 개의 미래 토큰을 동시에 예측하는 구조를 설명합니다. 이 방식이 학습 신호를 강화하고 추론 속도를 어떻게 향상시키는지 시각화합니다.
Multi-Token Prediction(MTP) 개념도
실무 Takeaway
- 추론 효율성을 위해 MLA(Multi-head Latent Attention)와 Gated DeltaNet 같은 하이브리드 어텐션 도입이 가속화되고 있습니다.
- Multi-Token Prediction(MTP)은 이제 학습 속도 향상뿐만 아니라 실시간 추론 속도 개선을 위한 핵심 기술로 채택되고 있습니다.
- 소형 모델(3B-4B)에서도 병렬 블록 구조나 가중치 공유 최적화를 통해 온디바이스 성능을 극대화하는 추세입니다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료