핵심 요약
AI 에이전트와 코딩 어시스턴트의 급증으로 저지연 및 긴 컨텍스트 처리 능력이 중요해진 가운데, NVIDIA는 차세대 Blackwell Ultra 플랫폼을 공개했다. GB300 NVL72 시스템은 소프트웨어 최적화와 결합하여 Hopper 플랫폼 대비 메가와트당 처리량을 50배 높였으며, 이는 토큰당 비용 35배 절감으로 이어진다. 특히 긴 컨텍스트(128k 토큰) 작업에서 GB200 대비 1.5배의 경제성을 제공하며, 향후 Rubin 플랫폼을 통해 성능을 더욱 확장할 계획이다.
배경
NVIDIA Blackwell 아키텍처에 대한 기본 이해, LLM 추론 및 토큰 경제학(Tokenomics) 개념, TensorRT-LLM 등 NVIDIA 소프트웨어 스택 지식
대상 독자
AI 인프라 설계자 및 대규모 LLM 서비스를 운영하는 개발자
의미 / 영향
이 기술은 LLM 추론 비용을 획기적으로 낮춰 복잡한 추론 과정을 거치는 에이전트형 AI의 상용화를 가속화할 것이다. 특히 전력 효율이 50배 향상됨에 따라 데이터 센터의 운영 비용 부담이 크게 줄어들 것으로 예상된다.
섹션별 상세
이미지 분석

새로운 칩들이 성능뿐만 아니라 TCO(총 소유 비용) 측면에서도 가장 경제적인 선택임을 강조하며 기사의 핵심 주장을 뒷받침한다.
NVIDIA의 세대 간 성능 향상과 경제성에 대한 SemiAnalysis의 분석 인용구이다.
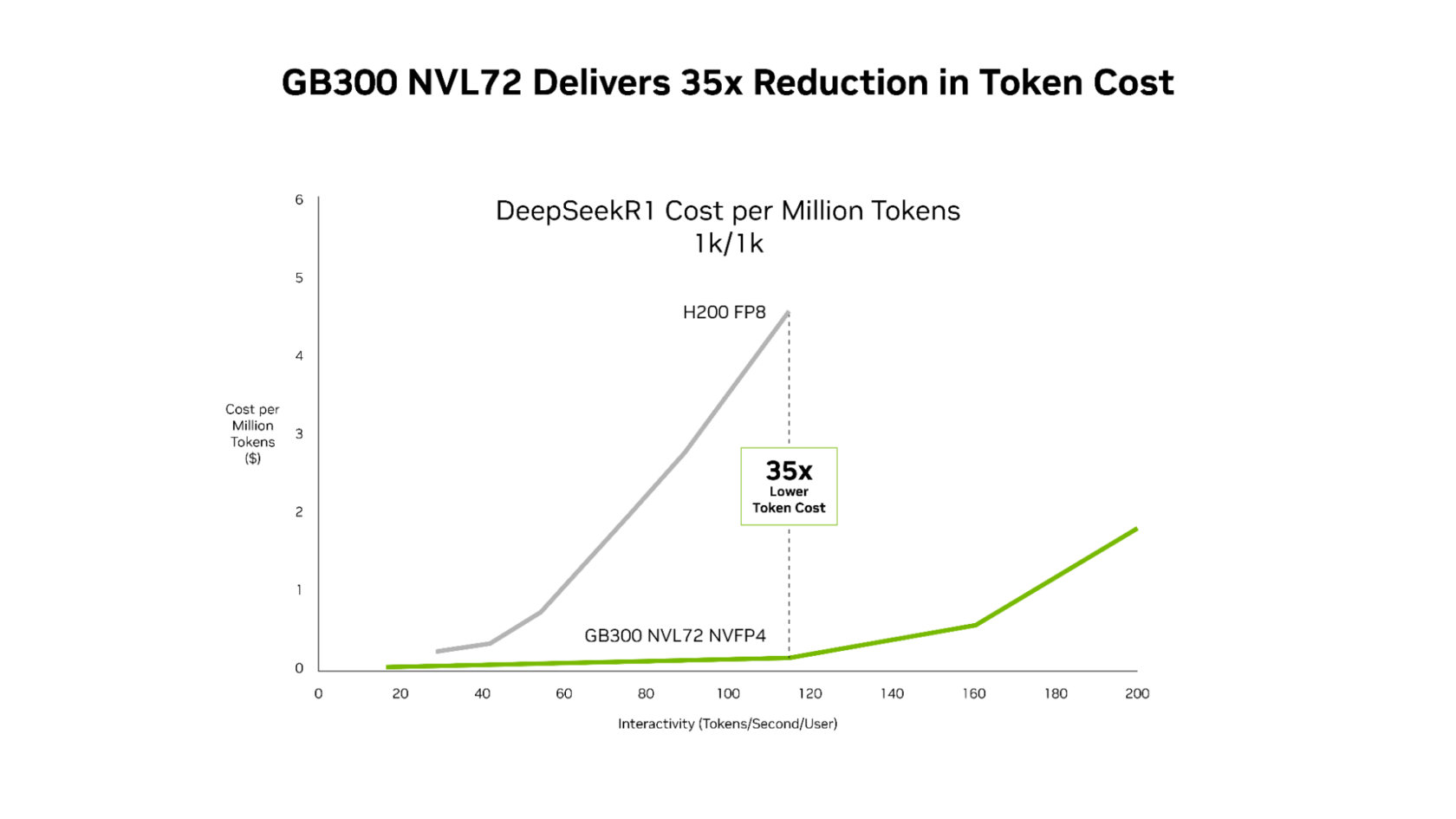
GB300 NVL72가 Hopper(H200) 대비 토큰 비용을 35배 절감함을 시각적으로 보여주며, 특히 인터랙티비티가 높은 구간에서의 우위를 증명한다.
DeepSeek-R1 모델을 기준으로 H200 FP8과 GB300 NVL72 NVFP4의 토큰당 비용을 비교한 차트이다.
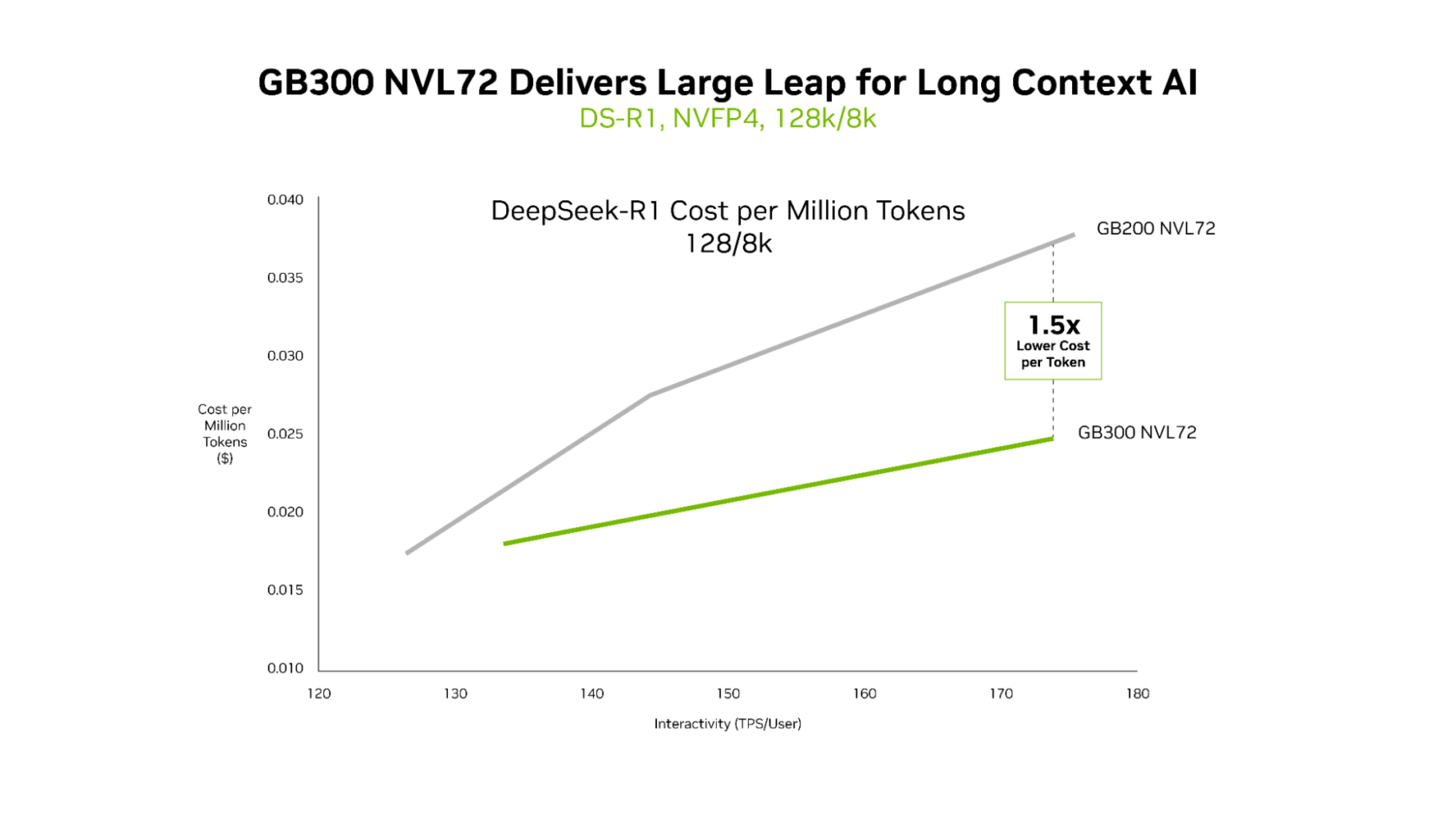
GB300 NVL72가 이전 세대인 GB200보다 1.5배 더 낮은 비용으로 긴 컨텍스트 작업을 처리할 수 있음을 수치로 나타낸다.
128k/8k 롱 컨텍스트 환경에서 GB200과 GB300의 토큰당 비용을 비교한 그래프이다.
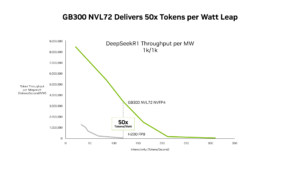
GB300 NVL72가 전력 효율 측면에서 50배의 도약을 이루었음을 보여주며, 데이터 센터 운영 효율성 개선의 근거를 제시한다.
DeepSeek-R1의 와트당 처리량(Throughput per MW)을 H200과 GB300 간에 비교한 차트이다.
실무 Takeaway
- 에이전트형 AI 도입 시 GB300 NVL72를 활용하면 Hopper 대비 토큰 비용을 35배 절감하여 서비스 운영 수익성을 획기적으로 개선할 수 있다.
- 128k 이상의 긴 컨텍스트가 필요한 코딩 에이전트 구축 시 GB200보다 GB300이 1.5배 더 경제적이므로 워크로드 특성에 맞는 하드웨어 선택이 필요하다.
- NVIDIA의 성능 향상은 칩뿐만 아니라 TensorRT-LLM과 같은 소프트웨어 스택의 지속적인 업데이트에 의존하므로 최신 라이브러리 최적화 상태를 유지해야 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료