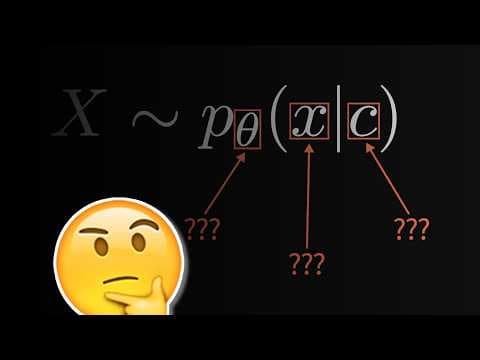TL;DR
LLM은 본질적으로 다음에 올 단어의 확률을 예측하는 확률 모델이다. 특히 자기회귀 방식을 통해 이전 단어들을 조건으로 다음 단어를 순차적으로 생성하며 문맥을 이어간다.
배경
Claude나 ChatGPT 같은 대규모 언어 모델이 어떻게 자연스러운 문장을 생성하는지에 대한 근본적인 원리를 설명한다.
대상 독자
AI 모델의 내부 작동 원리를 수학적/논리적으로 이해하고 싶은 개발자 및 학생
의미 / 영향
이 영상은 LLM을 단순한 블랙박스가 아닌 확률 통계적 시스템으로 바라보게 함으로써 모델의 한계와 가능성을 논리적으로 파악하게 돕는다. 개발자는 이를 통해 프롬프트 엔지니어링이나 파인튜닝 시 모델이 어떤 조건부 확률에 의존하는지 분석할 수 있는 기초 체력을 기를 수 있다.
챕터별 상세
확률 모델의 기본 개념과 가위바위보 예시
결합 확률과 조건부 확률의 차이를 이해하면 모델 설계의 의도를 파악하기 쉽다.
p(x) = p(x1, x2, ..., xn)확률 모델의 가장 기본적인 결합 확률 분포 수식
p(xi | xi-1; theta)학습 가능한 파라미터 세타를 포함한 조건부 확률 모델 수식
딥러닝 모델과 파라미터 세타의 역할
세타는 신경망 내부의 가중치들을 통칭하는 기호로 사용됐다.
언어 모델의 정의와 토큰화 단위
서브워드 토큰화는 OOV(Out-of-Vocabulary) 문제를 해결하기 위한 현대 NLP의 표준 방식이다.
p(xi | x<i; theta)이전의 모든 단어들을 조건으로 다음 단어를 예측하는 자기회귀 모델의 수식
자기회귀(Autoregressive) 방식의 문장 생성 원리
자기회귀 모델은 문맥 유지 능력이 뛰어나지만 생성 속도가 순차적이라는 제약이 있다.
새로운 대안: 디퓨전 언어 모델
디퓨전 모델은 이미지 생성에서 주로 쓰였으나 최근 텍스트 생성 분야로 확장이 시도되고 있다.
용어 해설
- Probabilistic Model
- — 자연계의 복잡한 현상을 확률 변수와 분포를 이용해 수학적으로 모형화한 시스템이다. 데이터 간의 상관관계나 발생 가능성을 수치화하여 미래의 상태를 예측하거나 패턴을 분석하는 데 필수적인 기초 프레임워크이다.
- Autoregressive Model
- — 과거의 자신의 출력이 현재의 입력에 영향을 주는 구조를 가진 모델이다. 시계열 데이터나 문장 생성 시 이전 단계까지 생성된 요소들을 바탕으로 다음 요소를 순차적으로 예측하는 메커니즘을 가진다.
- Subword
- — 단어를 더 작은 의미 단위나 문자 조합으로 쪼갠 토큰화 단위이다. 희귀 단어나 신조어 처리에 유연하며, 모델이 어휘 사전에 없는 단어를 만났을 때도 의미를 유추하거나 생성할 수 있게 돕는다.
- Diffusion Language Model
- — 데이터에 노이즈를 점진적으로 추가했다가 이를 다시 제거하는 과정을 학습하여 데이터를 생성하는 기법을 텍스트에 적용한 모델이다. 순차적으로 생성하는 자기회귀 방식과 달리 전체 문장의 구조를 동시에 고려하며 생성할 수 있는 대안적 접근법이다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.