TL;DR
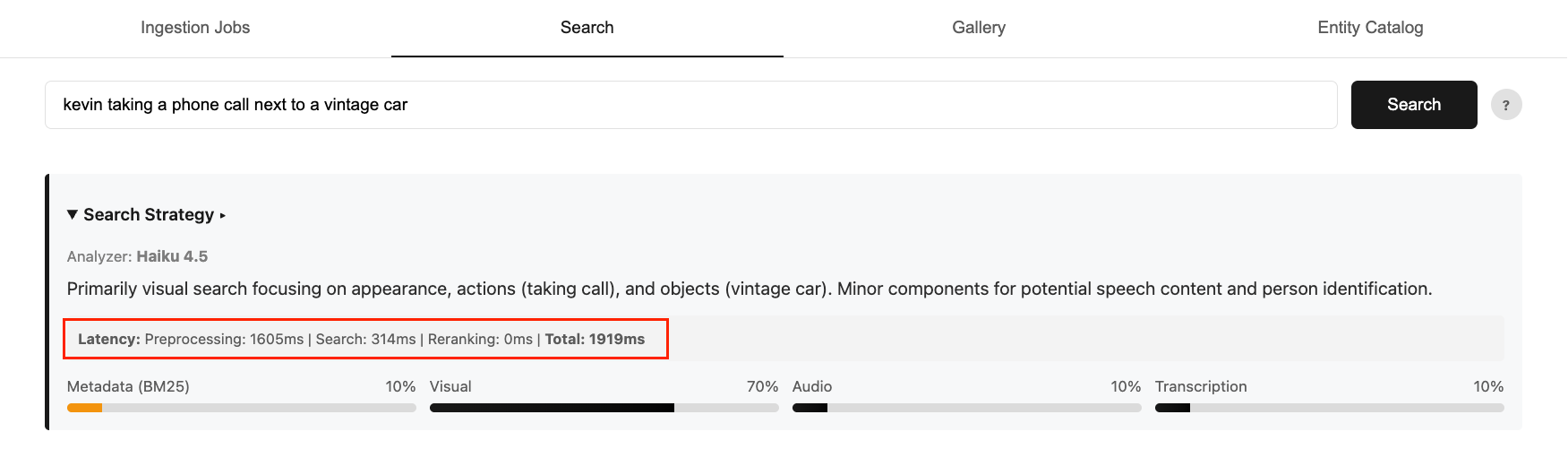
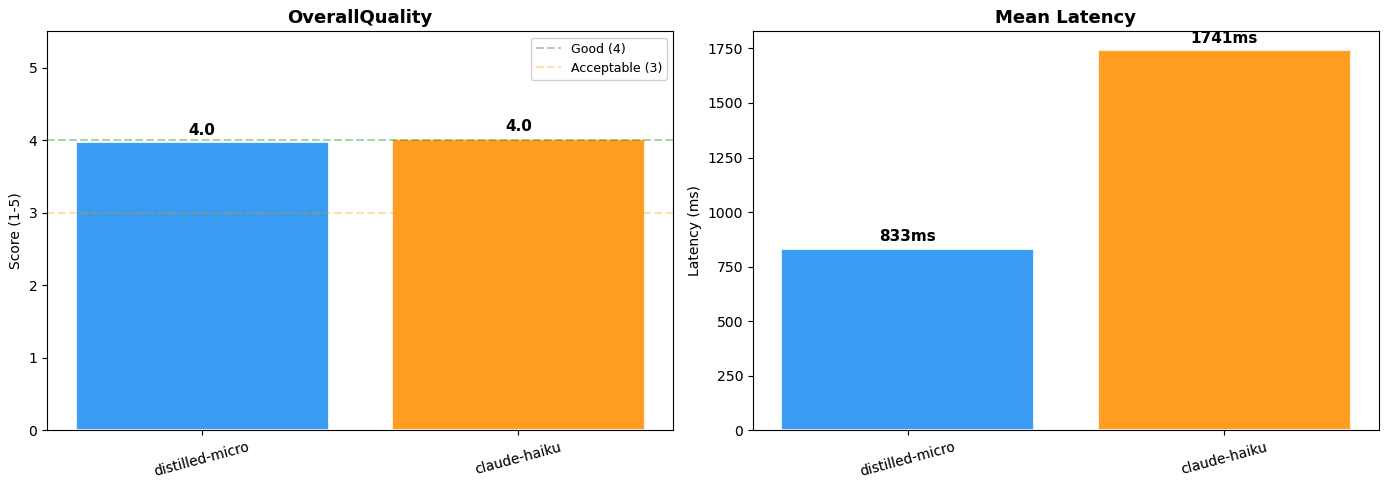
비디오 시맨틱 검색 시스템에서 검색 의도를 파악하는 라우팅 레이어는 정확도가 중요하지만, 대형 모델 사용 시 높은 지연 시간과 비용이 발생한다. 본 아티클은 Amazon Bedrock의 모델 증류 기법을 사용하여 Amazon Nova Premier(교사)의 지능을 훨씬 작고 빠른 Nova Micro(학생)로 전이하는 방법을 제시한다. 10,000개의 합성 데이터를 활용해 학습한 결과, 기존 Claude Haiku 기반 시스템 대비 비용은 95% 이상 절감되었고 지연 시간은 약 50% 단축되었다. 이를 통해 대규모 비디오 검색 서비스에서 성능 저하 없이 운영 효율성을 극대화할 수 있음을 입증했다.
배경
Amazon Bedrock 기본 사용법, Python 및 Boto3 SDK 활용 능력, 시맨틱 검색 및 모달리티 가중치에 대한 기본 개념
대상 독자
대규모 비디오 검색 시스템을 구축하거나 LLM 추론 비용 및 지연 시간 최적화가 필요한 AI 엔지니어
의미 / 영향
이 사례는 특정 도메인 작업에서 거대 모델의 성능을 소형 모델로 성공적으로 전이할 수 있음을 보여주며, 이는 기업들이 고성능 AI 서비스를 훨씬 낮은 비용 구조로 운영할 수 있게 하는 중요한 전환점이 될 것이다.
섹션별 상세
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=distillation_role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={"s3Uri": training_s3_uri},
outputDataConfig={"s3Uri": output_s3_uri},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": 1000
}
}
}
)Amazon Bedrock에서 교사 모델(Nova Premier)과 학생 모델(Nova Micro)을 지정하여 모델 증류 학습 작업을 생성하는 코드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.