TL;DR
비디오 데이터는 시각적 장면, 오디오, 대화 등 복잡한 비정형 신호가 혼합되어 있어 단순 텍스트 변환만으로는 검색 정확도에 한계가 있습니다. Amazon Nova 멀티모달 임베딩은 텍스트, 이미지, 비디오, 오디오를 하나의 시맨틱 벡터 공간으로 매핑하여 이러한 정보 손실 문제를 해결합니다. 본 아키텍처는 비디오를 장면 단위로 분할하고 시각·청각·텍스트 임베딩을 개별 생성한 뒤, LLM 기반의 의도 분석을 통해 각 신호에 가중치를 부여합니다. 내부 벤치마크 결과, 이 최적화된 하이브리드 방식은 기본 모델 대비 Recall@10 지표에서 약 31%p 향상된 95%의 성능을 기록했습니다.
배경
AWS Lambda 및 Step Functions 워크플로우 이해, 벡터 임베딩 및 코사인 유사도 개념, FFmpeg를 이용한 기본적인 비디오 처리 지식
대상 독자
미디어 자산 관리 시스템을 구축하거나 대규모 비디오 라이브러리에서 정밀 검색 기능을 구현하려는 AI 엔지니어 및 아키텍트
의미 / 영향
이 기술은 방송, 스포츠, 뉴스 등 방대한 영상 아카이브를 보유한 기업이 특정 순간을 초 단위로 정확하게 찾아내어 콘텐츠 수익화를 가속화할 수 있게 합니다. 특히 멀티모달 임베딩을 개별적으로 처리하고 의도에 따라 라우팅하는 방식은 검색 정확도와 인프라 비용 효율성을 동시에 잡을 수 있는 실무적인 표준을 제시합니다.
섹션별 상세
def _detect_scenes(video_path):
result = subprocess.run(
['ffprobe', '-v', 'quiet', '-show_entries', 'frame=pts_time', '-of', 'csv=p=0', '-f', 'lavfi', f"movie={video_path},select='gt(scene\\,{SCENE_THRESHOLD})'"],
capture_output=True, text=True
)FFmpeg의 ffprobe를 사용하여 비디오 내에서 장면 전환이 발생하는 타임스탬프를 추출하는 코드
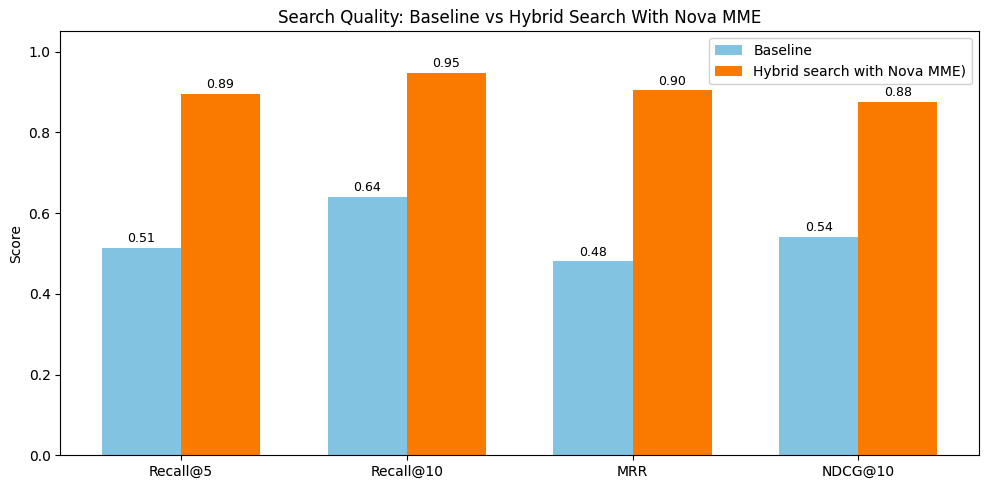
- 최적화된 하이브리드 검색 방식은 Recall@10 지표에서 95%를 기록하며 기본 모델(64%) 대비 크게 향상된 성능을 보였다. — Performance results 섹션의 Figure 7 차트 및 성능 비교 표
이미지 분석
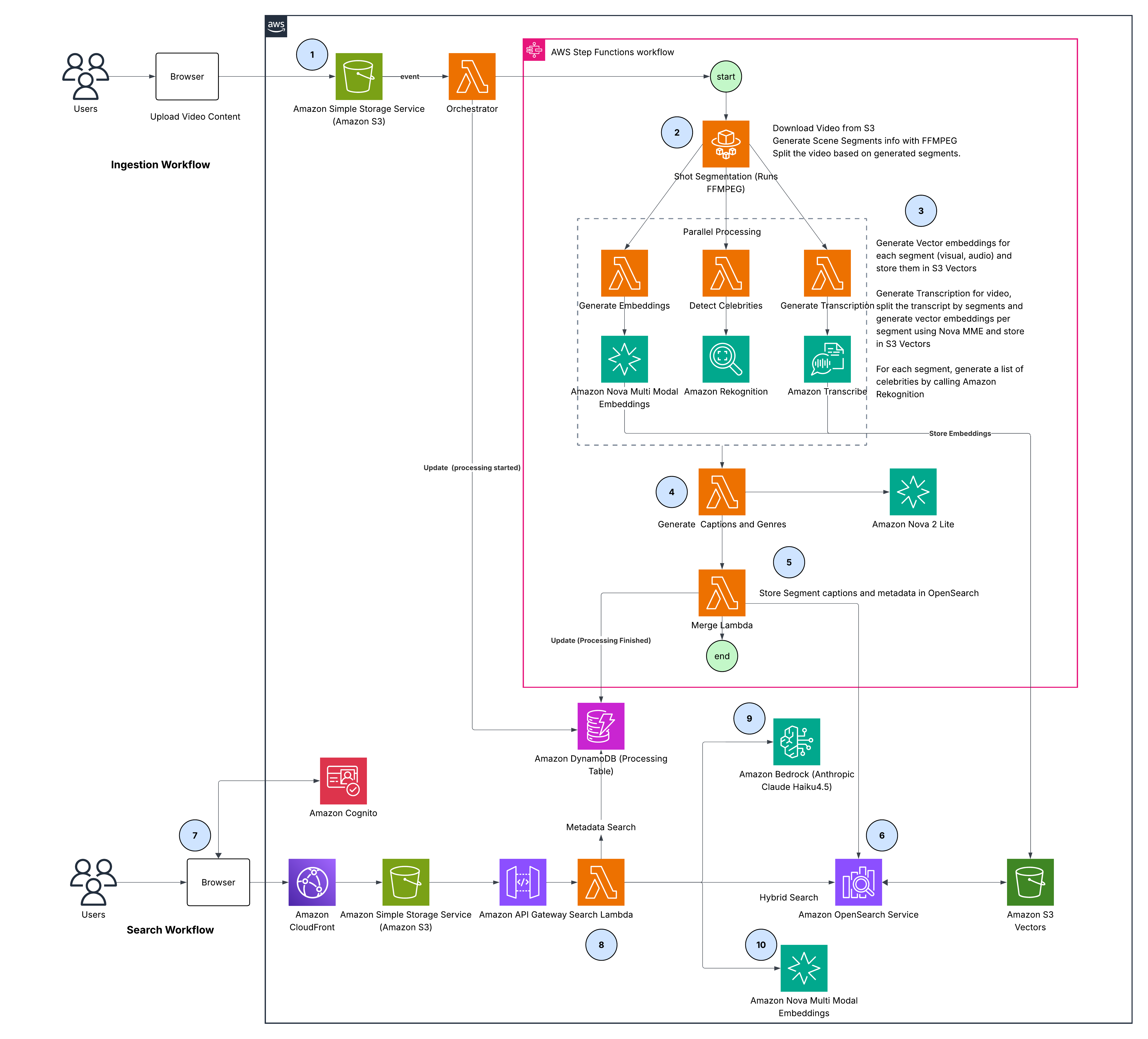
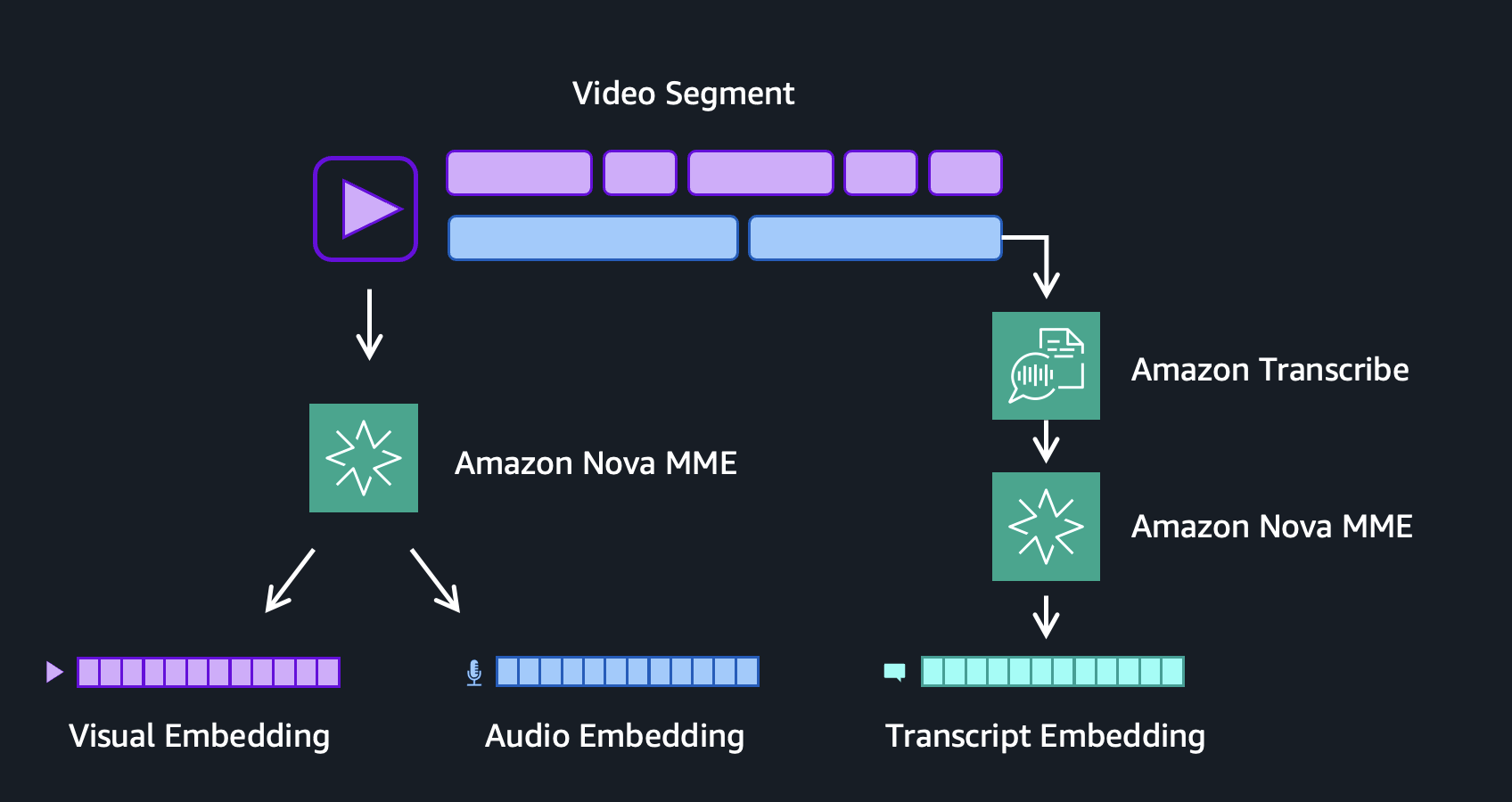
S3 업로드로 시작되는 인덱싱 파이프라인(Step Functions)과 API Gateway를 통한 검색 파이프라인의 전체 흐름을 보여줍니다. 특히 병렬 처리 단계에서 임베딩 생성, 전사, 유명인 감지가 동시에 일어나는 구조를 확인할 수 있습니다.
비디오 업로드부터 인덱싱, 검색까지 이어지는 엔드투엔드 솔루션 아키텍처 다이어그램
용어 해설
- Multimodal Embeddings
- — 텍스트, 이미지, 오디오, 비디오 등 서로 다른 형태의 데이터를 동일한 벡터 공간에 수치로 표현하는 기술입니다. 이를 통해 '사이렌 소리가 나는 추격전'과 같이 시각과 청각 정보가 혼합된 검색 쿼리를 효율적으로 처리할 수 있습니다.
- Hybrid Search
- — 의미적 유사성을 찾는 시맨틱 검색과 정확한 키워드를 찾는 어휘 검색(Lexical Search)을 결합한 방식입니다. 고유 명사나 특정 날짜 같은 정밀한 정보와 추상적인 문맥 정보를 동시에 활용하여 검색 정확도를 높입니다.
- Shot Segmentation
- — 비디오를 고정된 시간 단위가 아닌, 장면 전환(Scene Change)이 일어나는 지점을 기준으로 나누는 기법입니다. 문맥의 단절을 방지하여 검색의 최소 단위인 세그먼트의 의미적 일관성을 유지하는 데 중요합니다.
- Intent-aware Routing
- — 사용자의 검색 쿼리를 분석하여 시각, 오디오, 텍스트 중 어떤 요소가 중요한지 판단하고 가중치를 할당하는 기술입니다. 불필요한 모달리티의 검색을 건너뜀으로써 지연 시간을 줄이고 정확도를 최적화합니다.
근거 모음
- Amazon S3 Vectors를 사용하면 전문 솔루션 대비 벡터 저장 및 쿼리 비용을 최대 90%까지 절감할 수 있다. — Choose the right storage strategy 섹션의 S3 Vectors 설명 부분
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.