핵심 요약
탠덤 질량 분석(MS/MS) 데이터는 분자를 고유하게 결정하지 못하는 근본적인 모호함을 지니고 있어, 데이터 규모만으로는 해결이 어렵습니다. 본 프로젝트는 이를 극복하기 위해 580GB 규모의 데이터를 처리하는 엔드투엔드 머신러닝 스택을 직접 구축했습니다. 모델은 RDKit 기반의 모건 핑거프린트를 활용한 구조 정렬 경로를 포함하는 인코더 전용 트랜스포머로 구성되었습니다. 3단계에 걸친 사전 학습 결과, 모델은 의미 있는 화학적 표현을 학습했으나, 후보군 내에서 정확한 분자를 식별하는 순위 결정 능력은 여전히 약한 것으로 나타났습니다. 이는 데이터의 본질적인 모호함으로 인한 표현-결정 간의 간극을 시사하며, 시스템의 관측 가능성과 신뢰성 있는 평가 체계 구축이 모델 성능보다 중요함을 입증했습니다.
의미 / 영향
과학적 머신러닝 프로젝트에서 모델 아키텍처 자체보다 데이터 파이프라인의 결정론적 설계와 평가 시스템의 신뢰성이 모델의 실무적 가치를 결정함을 보여줍니다. MS/MS와 같은 모호한 데이터 도메인에서는 모델을 만능 해결사로 보기보다, 후보군을 좁히고 증거를 집계하는 보조 시스템으로 접근하는 것이 현실적인 분석 워크플로입니다.
빠른 이해
요약 브리프
MS/MS 데이터의 모호함을 해결하기 위해 580GB 규모의 데이터를 활용한 엔드투엔드 트랜스포머 시스템을 구축했습니다. 학습 결과 구조적 특징은 학습 가능하나 순위 결정은 여전히 어렵다는 한계를 확인했으며, 모델 성능보다 시스템의 관측 가능성과 재현 가능한 파이프라인이 중요함을 입증했습니다.
새로운 점
단순 모델 성능 향상이 아닌, MS/MS 도메인에서 데이터 파이프라인부터 추론까지 전체 스택을 독립적으로 구축하고 시스템적 한계를 명확히 규명한 엔지니어링 프로젝트입니다.
핵심 메커니즘
입력(MS/MS 스펙트럼) → 인코더 트랜스포머(표현 학습) + RDKit 기반 구조 정렬 헤드 → 출력(분자 임베딩 및 후보군 순위)
핵심 수치
- 데이터셋 규모: 580GB (약 2억 100만 스펙트럼)- 338개의 파켓 샤드로 구성
- 후보군 식별 성공률: 55% (11/20)- 검증 예시 기준
섹션별 상세
프로젝트 동기와 시스템 접근 방식
데이터 설계 및 학습 아키텍처
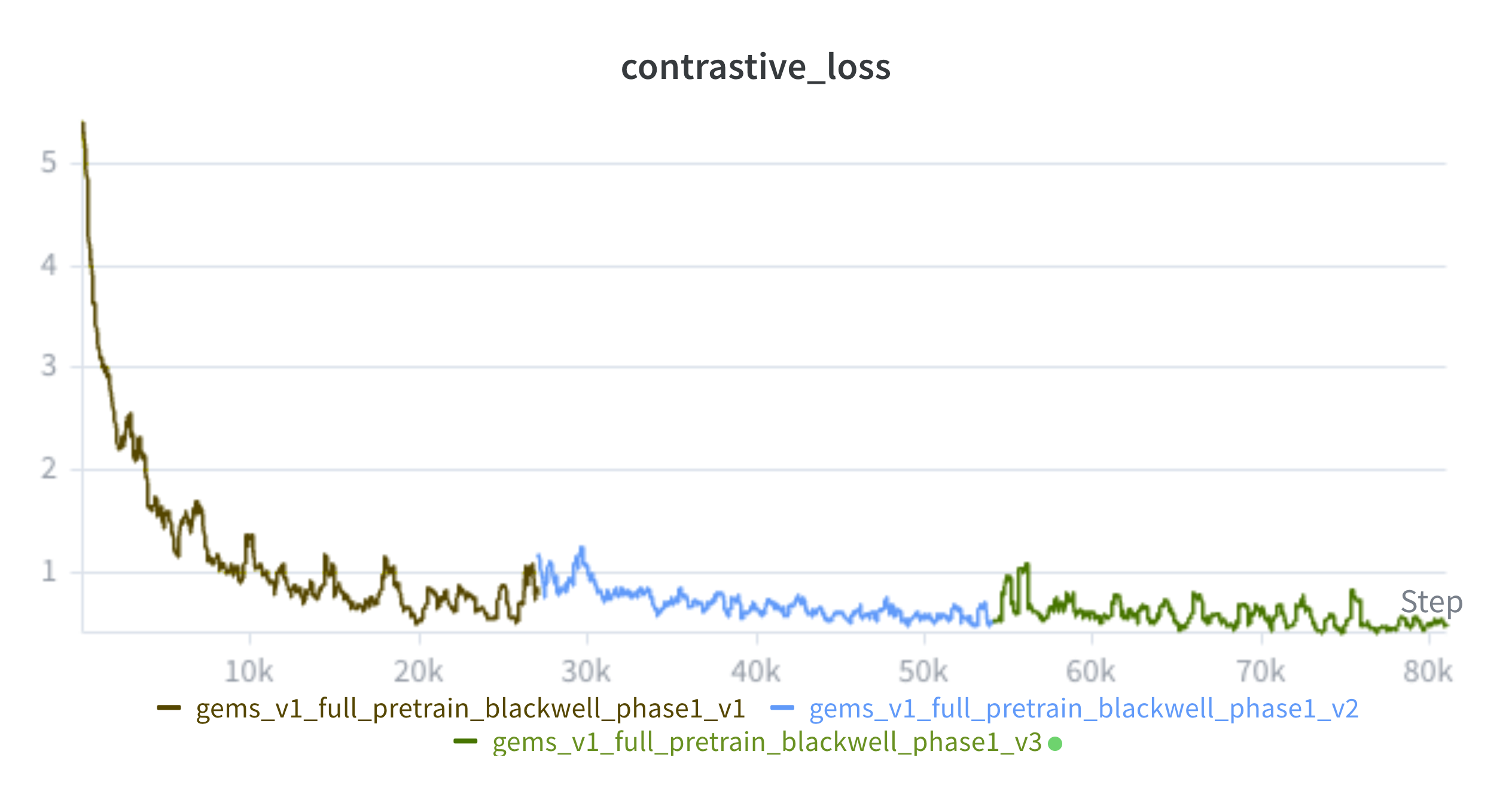
시스템 안정성과 관측 가능성
결과 분석 및 실무적 통찰
실무 Takeaway
- MS/MS 데이터는 중복성과 가변성을 동시에 지니므로, 결정론적 샤드 분할을 통해 데이터 누수를 방지하고 일반화 성능을 엄격히 테스트해야 한다.
- 모델 성능보다 시스템의 관측 가능성이 중요하며, 데이터 파이프라인과 평가 계약이 명확해야 모델의 출력을 신뢰하고 해석할 수 있다.
- MS/MS 스펙트럼에서 화학 구조 학습은 가능하나, 데이터의 본질적 모호함으로 인해 robust한 순위 결정은 어렵기에 후보군 축소 도구로 활용하는 것이 실무적으로 타당하다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.