핵심 요약
대형 언어 모델의 도메인 특화 성능을 높이기 위해 기존에는 수천 개의 정답 데이터가 필요했으나, Amazon Nova의 강화 파인튜닝(RFT)은 평가 기반의 학습 방식을 통해 이를 해결한다. RFT는 모델이 생성한 여러 답변을 보상 함수로 평가하고, 높은 점수를 받은 경로를 강화하는 방식으로 작동한다. 사용자는 Amazon Bedrock의 완전 관리형 서비스부터 SageMaker HyperPod의 대규모 인프라까지 필요에 맞는 구현 계층을 선택할 수 있다. 특히 코드 생성, 수학적 추론, 금융 분석 등 정답 확인이 가능한 영역에서 데이터 구축 비용을 획기적으로 줄이면서 성능을 개선할 수 있다.
배경
LLM 파인튜닝 기본 개념, AWS SageMaker 또는 Bedrock 사용 경험, Python 및 JSONL 데이터 처리 능력
대상 독자
도메인 특화 LLM을 구축하려는 ML 엔지니어 및 데이터 과학자
의미 / 영향
RFT는 고품질 라벨링 데이터 확보가 어려운 전문 영역에서 LLM 커스터마이징의 진입 장벽을 낮춘다. 특히 추론 과정을 최적화하여 운영 비용(토큰 사용량)을 절감할 수 있다는 점에서 기업용 AI 도입의 경제성을 높이는 데 기여할 것이다.
섹션별 상세


{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Context: ....
Question: ....
Provide your answer in the following format:
ANSWER: [your answer here]"
}
]
}
],
"reference_answer": {
"answer": "65.3%"
},
"data_source": "finqa"
}RFT 학습을 위한 JSONL 데이터 형식 예시
def rft_launcher(train_S3_uri, reward_lambda_arn):
instance_type = "ml.p5.48xlarge"
instance_count = 4
recipe = "fine-tuning/nova/nova_2_0/nova_lite/RFT/nova_lite_2_0_p5_gpu_lora_rft"
// ...(중략)
recipe_overrides = {
"run": {
"reward_lambda_arn": reward_lambda_arn,
},
"training_config": {
"rollout": {
"rewards": {
"api_endpoint": {
"lambda_arn": reward_lambda_arn
}
}
}
}
}
estimator = PyTorch(
instance_count=instance_count,
instance_type=instance_type,
recipe_overrides=recipe_overrides,
training_recipe=recipe,
image_uri=image_uri
)
estimator.fit(inputs={"train": train_input}, wait=False)
return estimator.latest_training_job.nameSageMaker Training Jobs를 사용한 RFT 학습 실행 코드

실무 Takeaway
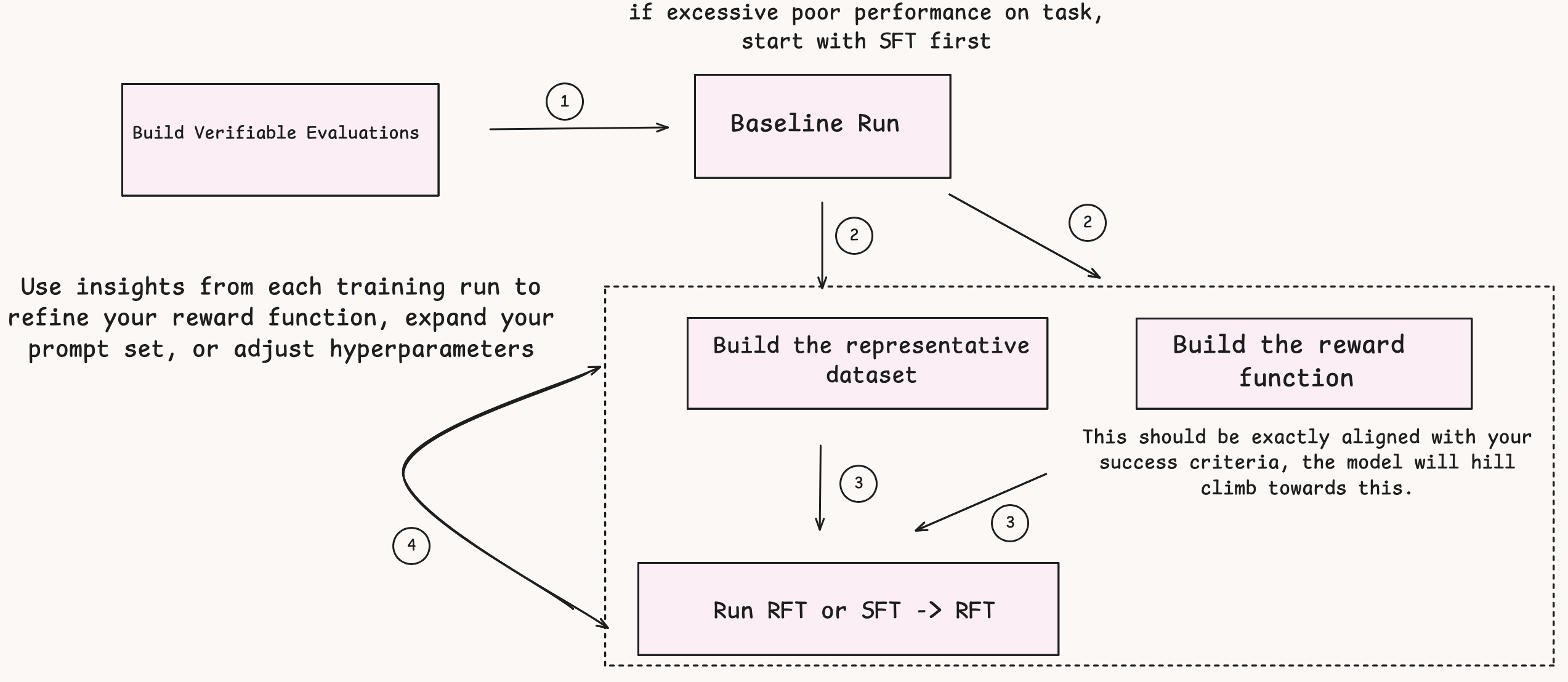
- 정답 경로가 명확한 코드 생성이나 수학 문제의 경우, AWS Lambda를 활용한 규칙 기반 보상 함수(RLVR)를 설계하여 데이터 라벨링 비용 없이 모델 성능을 개선할 수 있다.
- 모델이 초기 학습 단계에서 정답을 전혀 내놓지 못한다면 RFT가 작동하지 않으므로, SFT를 통해 베이스라인 성능을 확보한 뒤 RFT로 고도화해야 한다.
- LoRA 방식을 사용하면 Amazon Bedrock에서 온디맨드 추론이 가능하므로, 초기 실험 단계에서는 LoRA로 시작하여 검증 후 Full Rank 학습으로 전환하는 것이 비용 효율적이다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.