핵심 요약
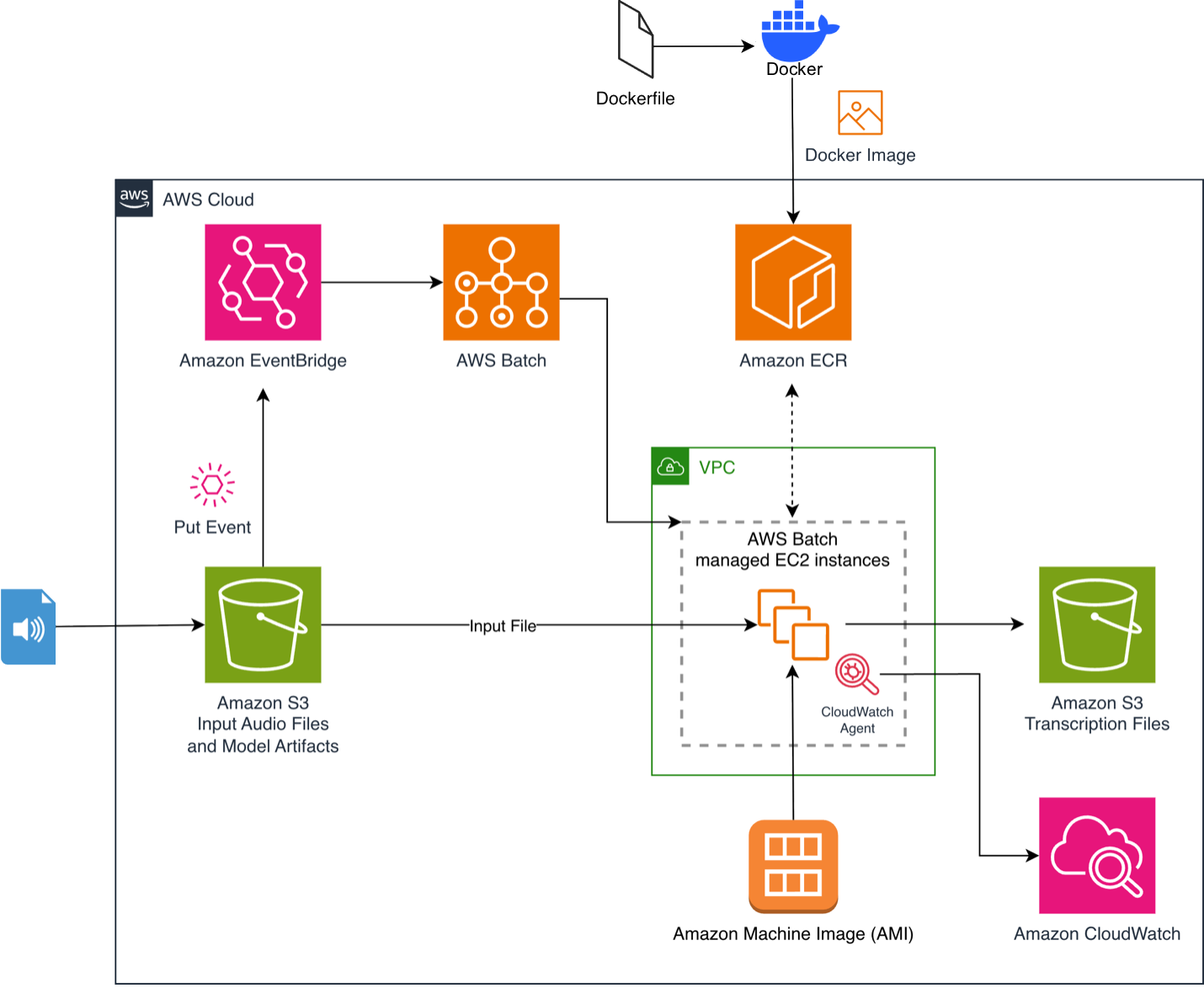
대규모 미디어 라이브러리나 고객 센터 녹취록을 처리할 때 발생하는 높은 전사 비용 문제를 해결하기 위해 NVIDIA의 Parakeet-TDT-0.6B-v3 모델을 AWS Batch에 배포하는 아키텍처를 제안한다. Parakeet-TDT는 텍스트 토큰과 지속 시간을 동시에 예측하여 무음 구간 처리를 최적화함으로써 실시간보다 수백 배 빠른 추론 속도를 제공한다. AWS S3에 오디오 업로드 시 EventBridge가 Batch 작업을 트리거하고, GPU 가속 스팟 인스턴스에서 컨테이너화된 모델이 실행되는 이벤트 기반 구조를 갖춘다. 벤치마크 결과 g6.xlarge 인스턴스에서 오디오 1분당 약 0.49초의 처리 속도를 기록했으며, 스팟 인스턴스 활용 시 오디오 1분당 비용을 약 $0.00005까지 낮출 수 있음이 확인됐다.
배경
AWS 계정 및 관리자 권한, AWS CLI 및 Docker 설치, Python 및 PyTorch 기본 지식
대상 독자
대규모 미디어 데이터를 처리해야 하는 데이터 엔지니어 및 AI 인프라 운영자
의미 / 영향
이 솔루션은 고가의 관리형 ASR 서비스 대신 오픈소스 모델과 클라우드 배치 컴퓨팅을 결합하여 비용 효율적인 대안을 제시합니다. 특히 다국어 지원과 스트리밍 추론 기법을 통해 기업들이 하드웨어 제약 없이 대규모 아카이브 데이터를 경제적으로 디지털화할 수 있게 돕습니다.
섹션별 상세
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
WORKDIR /app
RUN dnf update -y && dnf install -y gcc-c++ python3.12-devel tar xz && \
ln -sf /usr/bin/python3.12 /usr/local/bin/python3 && \
python3 -m ensurepip && python3 -m pip install --no-cache-dir --upgrade pip
COPY ./requirements.txt requirements.txt
RUN pip install -U --no-cache-dir -r requirements.txt && \
python3 -m compileall -q /usr/local/lib/python3.12/site-packages
COPY ./parakeet_transcribe.py parakeet_transcribe.py
RUN python3 -c "from nemo.collections.asr.models import ASRModel; \
ASRModel.from_pretrained('nvidia/parakeet-tdt-0.6b-v3')"
CMD ["python3", "parakeet_transcribe.py"]런타임 지연을 줄이기 위해 빌드 단계에서 Parakeet-TDT 모델을 미리 캐싱하는 Dockerfile 예시
asr_model.change_attention_model("rel_pos_local_attn", [128, 128])
asr_model.change_subsampling_conv_chunking_factor(1)
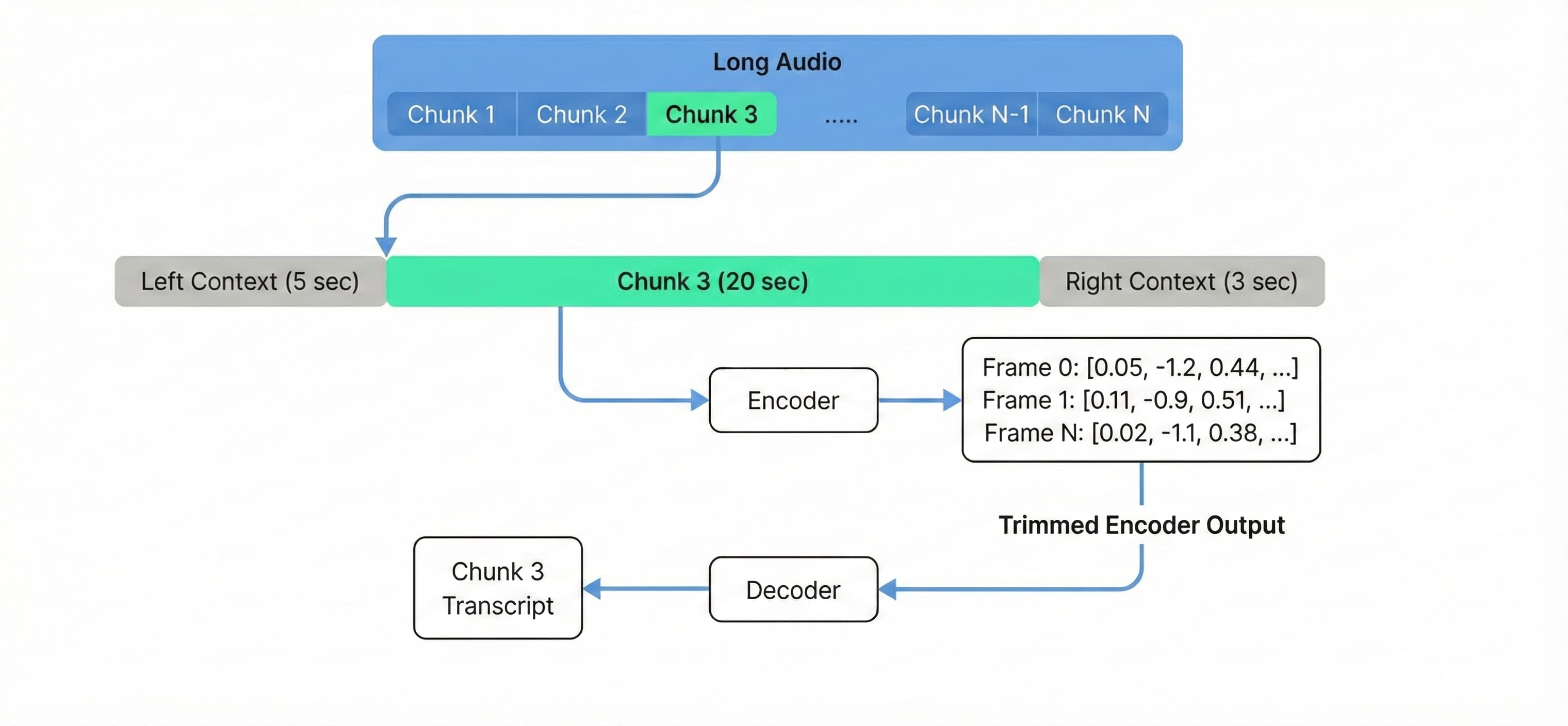
asr_model.transcribe(["input_audio.wav"])최대 3시간의 긴 오디오 처리를 위해 로컬 어텐션 모드를 활성화하는 코드
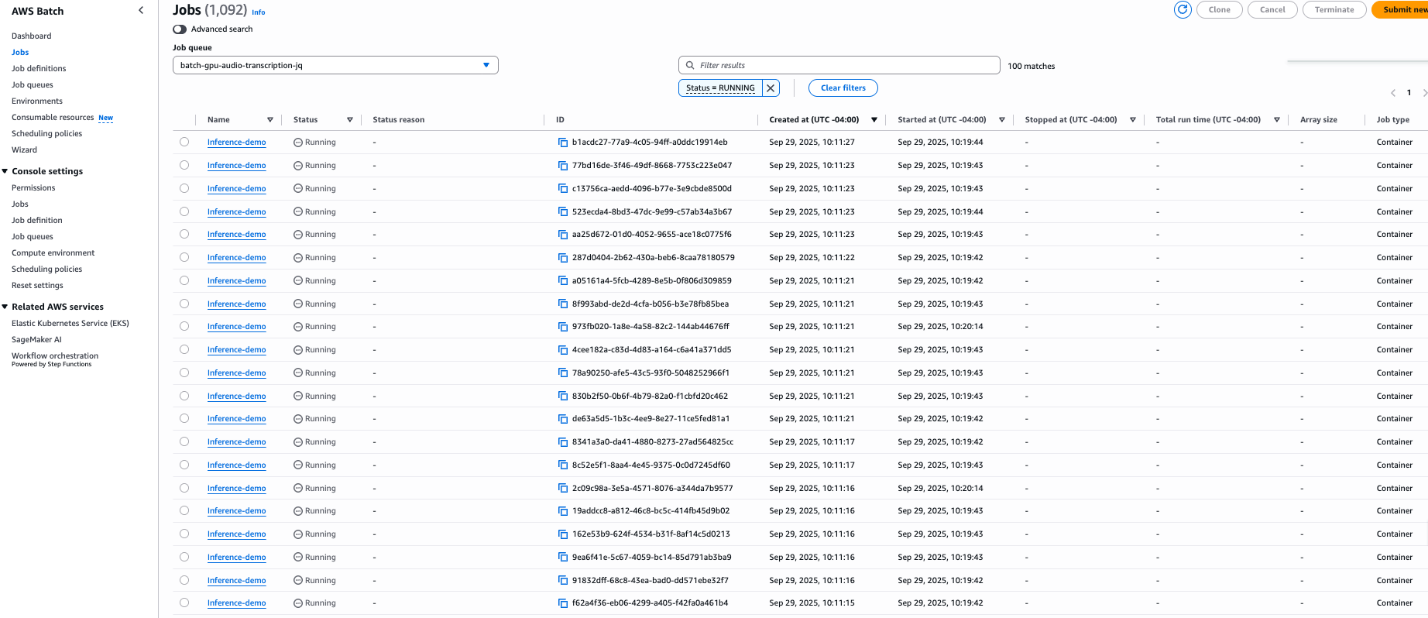
실무 Takeaway
- NVIDIA Parakeet-TDT 모델을 AWS Batch GPU 스팟 인스턴스에 배포하면 관리형 API 대비 전사 비용을 획기적으로 낮출 수 있다.
- VRAM 제약을 극복하기 위해 20초 단위의 버퍼링 스트리밍 추론을 적용하면 저사양 GPU에서도 10시간 이상의 긴 오디오를 처리 가능하다.
- AWS Batch의 자동 스케일링 기능을 활용하여 작업이 있을 때만 컴퓨팅 비용을 지불하고 유휴 시에는 비용을 0으로 유지할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.