TL;DR
IBM Research는 연구 커뮤니티 전반에 최신 LLM에 대한 민주화된 접근을 제공하기 위해 Research Inference & Tuning Service(RITS) 플랫폼을 도입했다. RITS는 vLLM을 핵심 추론 엔진으로 채택하여 100개 이상의 실험적 모델을 효율적으로 서빙하며, PagedAttention과 Continuous Batching 기능을 통해 GPU 활용도를 극대화한다. 특히 vLLM이 제공하는 대기 요청 수(Requests Waiting)와 같은 커스텀 메트릭을 활용해 서버리스 기반의 하이브리드 오토스케일링 아키텍처를 구현했다. 이를 통해 IBM은 예측 불가능한 연구 워크로드 환경에서도 비용 효율적이고 안정적인 모델 서빙 환경을 확보했다.
배경
Kubernetes 및 OpenShift 기본 지식, LLM 추론 메커니즘(Batching, KV Cache)에 대한 이해, Prometheus 기반 모니터링 개념
대상 독자
기업 내 공유 AI 인프라를 구축하려는 MLOps 엔지니어 및 플랫폼 아키텍트
의미 / 영향
이 사례는 vLLM이 단순한 추론 엔진을 넘어 엔터프라이즈급 공유 플랫폼의 핵심 구성 요소로 자리 잡았음을 보여줍니다. 특히 커스텀 메트릭 기반의 하이브리드 스케일링 모델은 고비용 GPU 자원을 효율적으로 관리하려는 기업들에게 실질적인 아키텍처 가이드를 제공합니다.
섹션별 상세
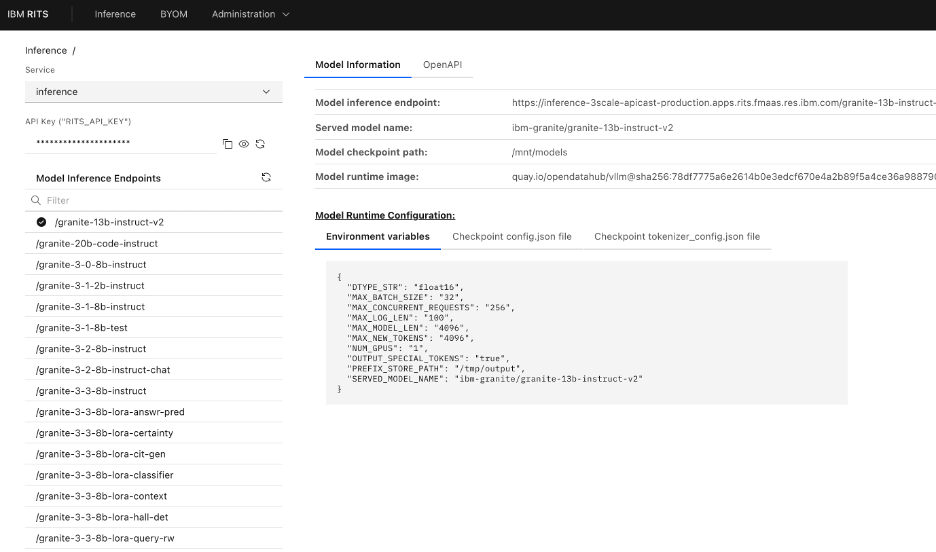
- RITS 플랫폼은 1,300명 이상의 활성 사용자를 보유하고 있으며 100개 이상의 모델을 호스팅한다. — Introduction 섹션

- vLLM의 PagedAttention과 Continuous Batching이 RITS의 성능 요구사항을 충족시킨다. — Solving AI Challenges with vLLM 섹션
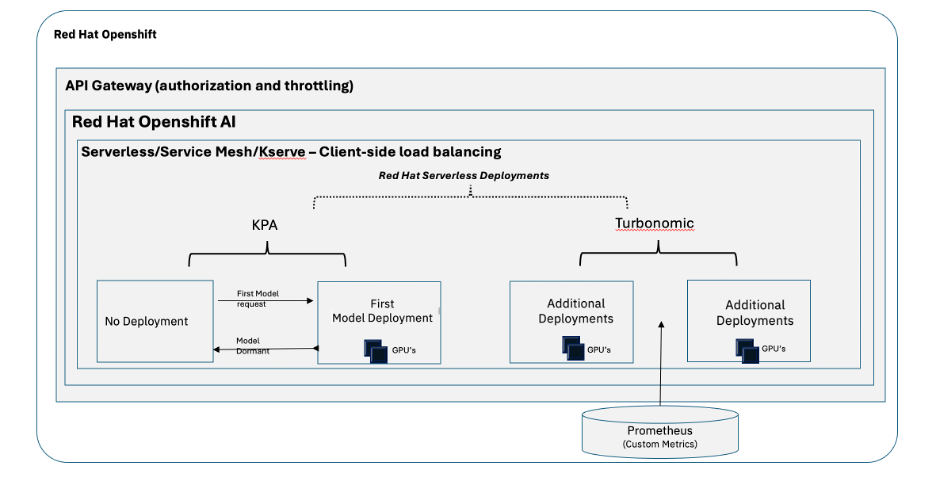
- RITS는 서버리스 기술과 Turbonomic을 결합한 하이브리드 오토스케일링 모델을 사용한다. — Figure 3 및 관련 본문 설명
기술
- vLLM
- Red Hat OpenShift AI
- KServe
- Prometheus
- IBM Turbonomic
- OpenAI API
활용 사례
- 중앙 집중형 모델 서빙 플랫폼
- 연구용 실험 모델 배포
- 비용 최적화된 하이브리드 오토스케일링
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.