핵심 요약
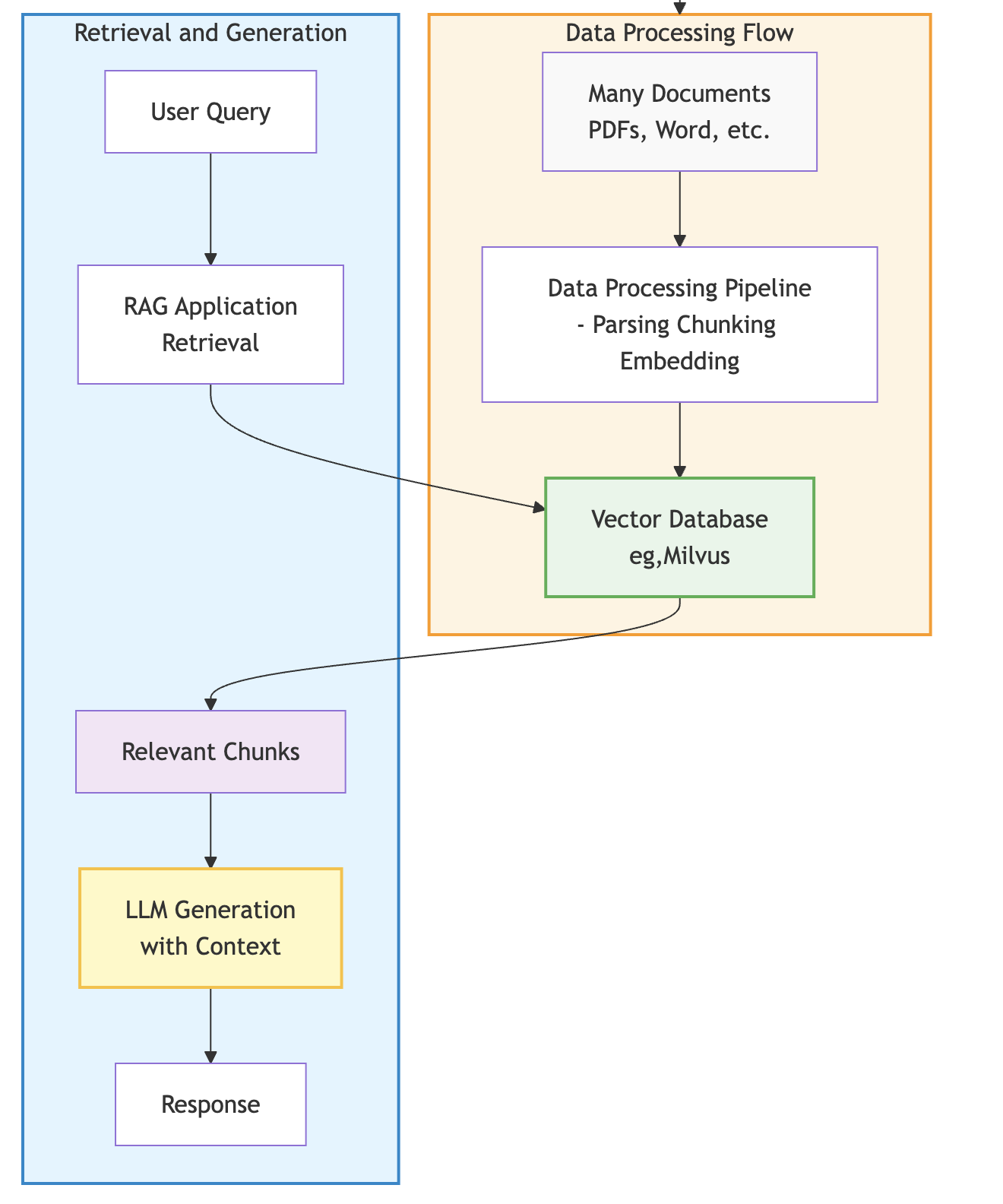
엔터프라이즈 RAG 시스템 구축의 가장 큰 장애물은 수만 개의 복잡한 문서를 효율적으로 처리하지 못하는 데이터 병목 현상이다. 이를 해결하기 위해 분산 처리 라이브러리인 Ray Data와 고성능 문서 파싱 도구인 Docling을 결합한 통합 인프라를 활용한다. 이 아키텍처는 CPU 기반의 문서 파싱과 GPU 기반의 임베딩 생성을 단일 파이프라인에서 병렬로 실행하여 전처리 시간을 획기적으로 단축한다. Red Hat OpenShift AI나 Anyscale 플랫폼에서 확장 가능한 데이터 파이프라인을 운영함으로써 신뢰할 수 있는 AI 에이전트 서비스의 기반을 마련한다.
배경
RAG(Retrieval-Augmented Generation) 기본 개념, Ray 분산 컴퓨팅 프레임워크에 대한 이해, Kubernetes 및 컨테이너 오케스트레이션 기초, Python 프로그래밍
대상 독자
프로덕션 환경에서 대규모 문서 기반 RAG 시스템을 구축하고 확장해야 하는 AI 엔지니어 및 인프라 아키텍트
의미 / 영향
이 기술 조합은 데이터 전처리 시간을 일 단위에서 시간 단위로 단축시켜 기업의 AI 도입 속도를 가속화한다. 특히 오픈소스 기반의 통합 플랫폼을 통해 데이터 보안을 유지하면서도 고성능 AI 에이전트를 구축할 수 있는 표준 아키텍처를 제공한다.
섹션별 상세


실무 Takeaway
- 대규모 RAG 시스템 구축 시 Ray Data의 스트리밍 엔진을 도입하여 CPU 파싱과 GPU 임베딩 작업을 병렬화함으로써 전처리 속도를 획기적으로 높여야 한다.
- Docling을 활용해 PDF의 표와 구조적 맥락을 정확히 추출함으로써 검색 품질의 핵심인 데이터 무결성을 확보하는 것이 중요하다.
- KubeRay를 통해 데이터 전처리와 모델 서빙을 동일한 Kubernetes 플랫폼에서 운영하여 인프라 복잡성을 줄이고 운영 효율성을 개선할 수 있다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.