핵심 요약
AMD ROCm 환경에서 LLM 추론 성능을 최적화하기 위해 vLLM이 도입한 7가지 어텐션 백엔드와 그 기술적 세부사항을 다룬다. 단순 포팅 단계를 넘어 AMD CDNA 3 아키텍처에 최적화된 AITER 프리미티브를 활용하며, 특히 MHA를 위한 3경로 라우팅(ROCM_AITER_FA)과 DeepSeek의 MLA 구조를 위한 전용 백엔드를 통해 성능을 극대화한다. 벤치마크 결과 MHA 모델에서 최대 4.4배, MLA 모델에서 최대 1.5배의 처리량 향상을 확인했으며, 이는 소프트웨어 오케스트레이션과 하드웨어 최적화의 결합이 필수적임을 보여준다.
배경
vLLM 추론 엔진 기본 지식, AMD ROCm 소프트웨어 스택 이해, MHA 및 MLA 어텐션 메커니즘 개념
대상 독자
AMD GPU 기반 인프라에서 LLM 추론 서비스를 운영하거나 최적화하는 MLOps 엔지니어 및 백엔드 개발자
의미 / 영향
AMD 하드웨어에 최적화된 전용 커널과 오케스트레이션 레이어의 도입은 NVIDIA 중심의 LLM 추론 시장에서 AMD Instinct GPU의 경쟁력을 실질적으로 확보하는 계기가 된다. 특히 DeepSeek와 같은 최신 모델 구조에 대한 즉각적인 최적화 지원은 기업용 AI 인프라 선택의 폭을 넓힌다.
섹션별 상세
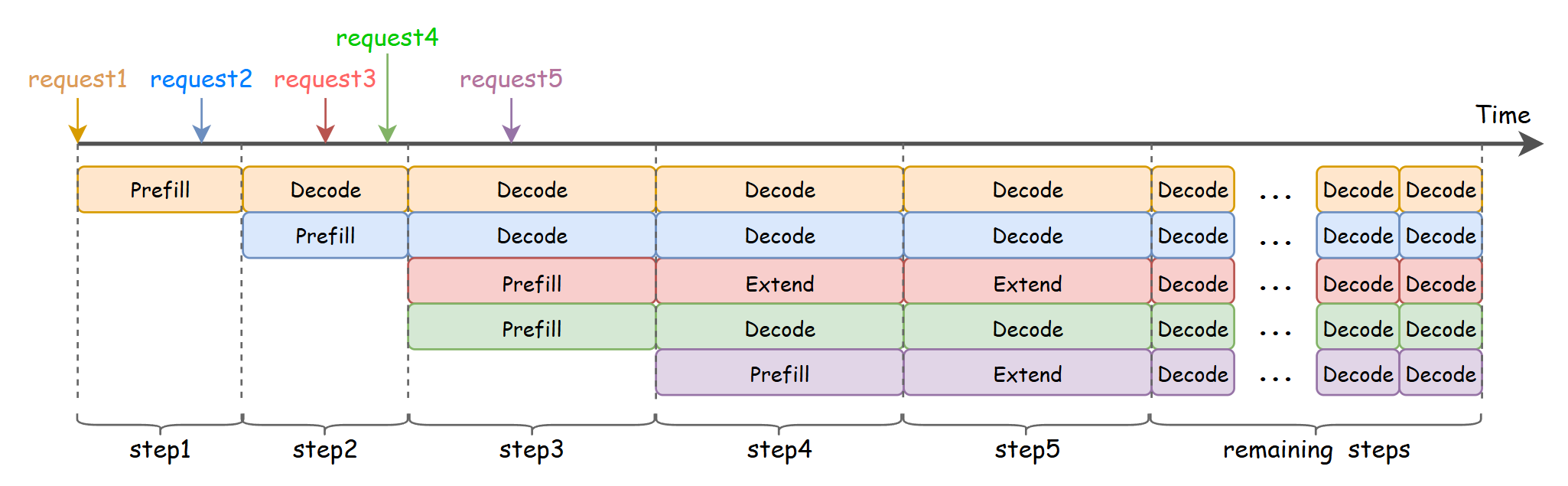
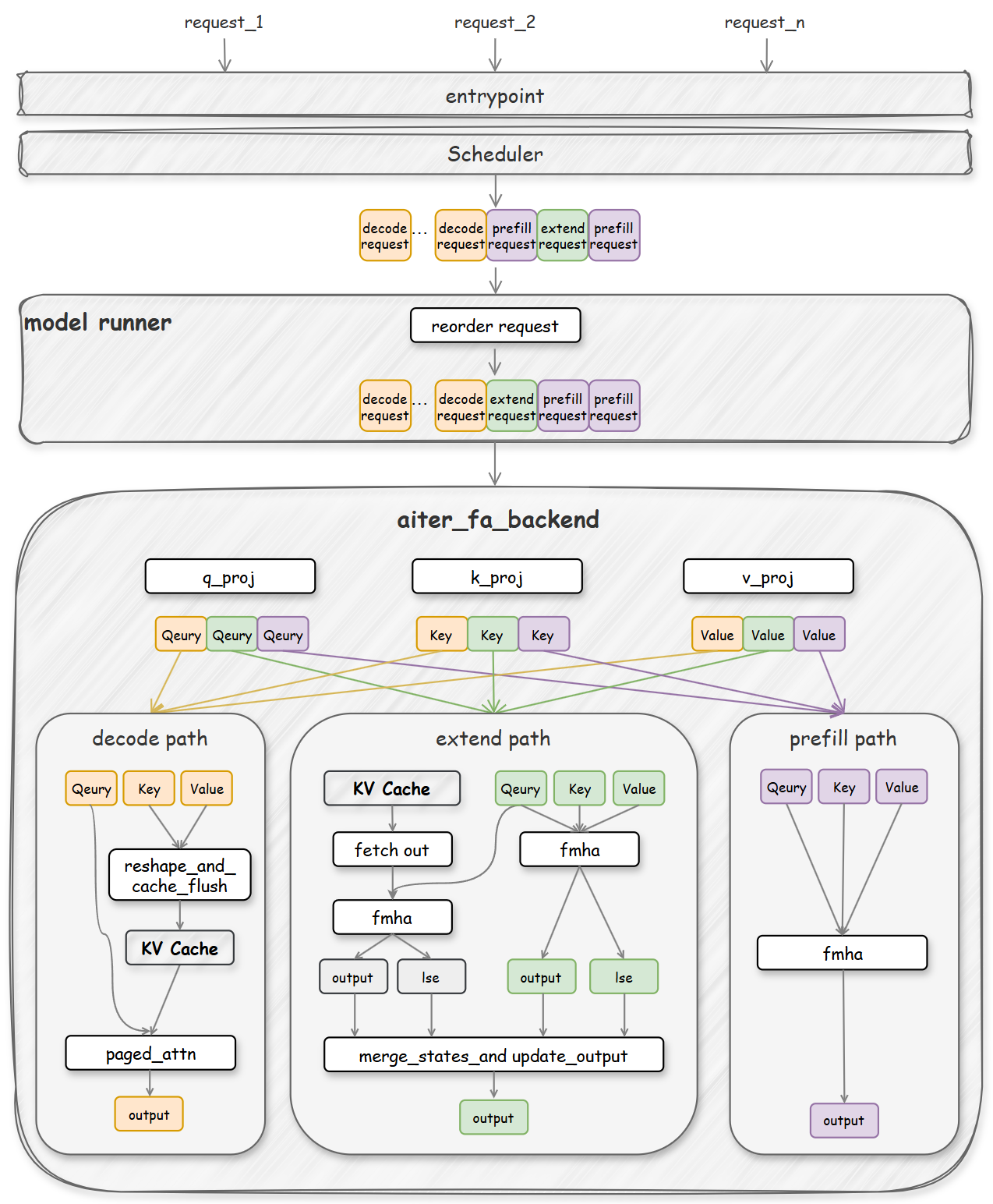
혼합 워크로드 처리를 위한 3경로 라우팅(ROCM_AITER_FA)은 Prefill, Extend, Decode 요청을 각각 최적화된 전용 커널로 라우팅한다. Prefill은 연산 중심, Decode는 메모리 대역폭 중심의 특성을 가지므로 이를 분리하여 하드웨어 자원 활용도를 극대화한다.
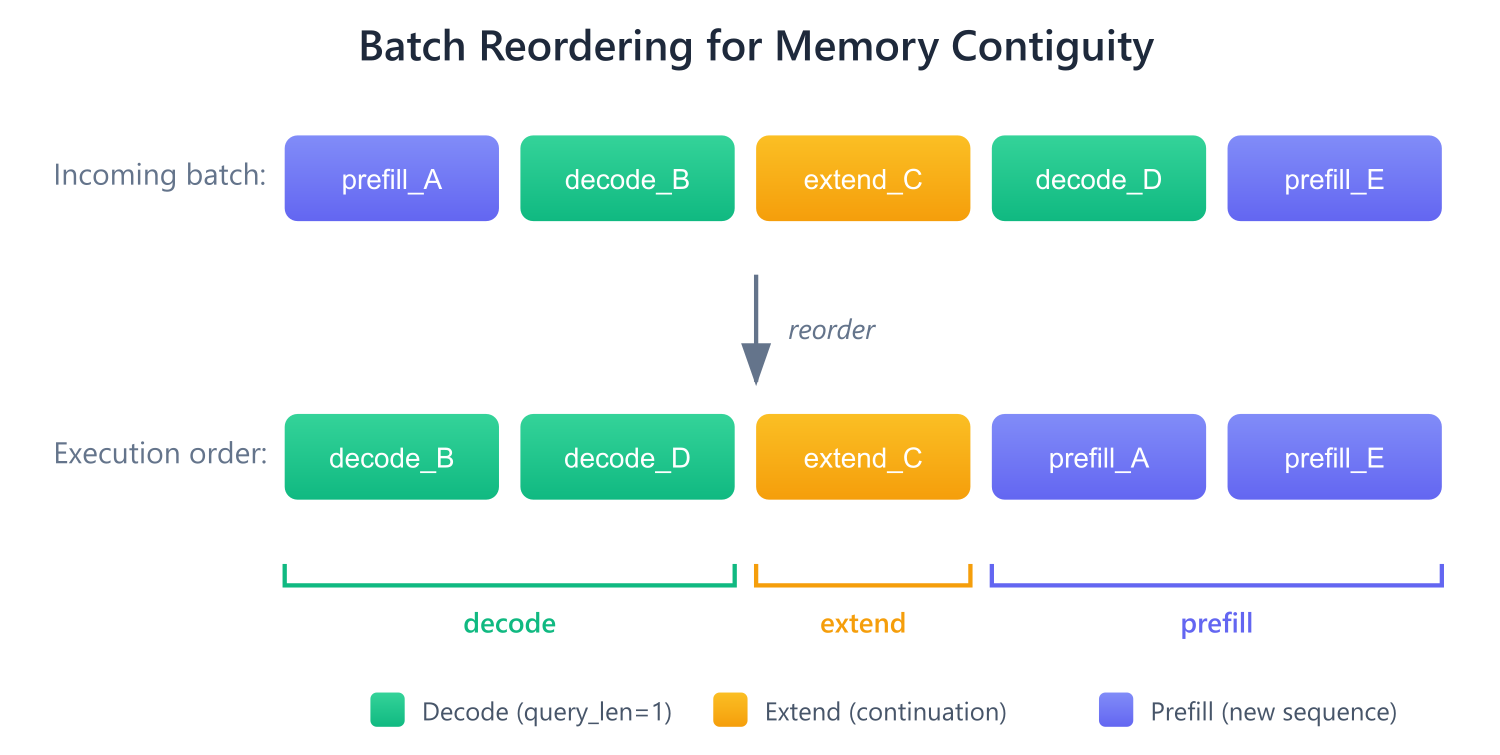
vLLM의 모델 러너는 메모리 연속성을 확보하기 위해 배치를 [decode:extend:prefill] 순서로 재정렬한다. 이 과정을 통해 중복된 KV 캐시 페치를 제거하고 각 커널 경로가 연속된 토큰 데이터에서 작동하도록 보장한다.
AMD AITER 커널 팀이 설계한 사전 셔플링(Preshuffled) KV 캐시 레이아웃을 도입했다. 이 레이아웃은 CDNA 아키텍처의 메모리 접근 패턴과 일치하여 레이아웃 변환 오버헤드 없이 고성능 어셈블리 커널을 직접 호출할 수 있게 하며 Decode 성능을 15-20% 향상시킨다.
긴 컨텍스트 처리를 위해 100K 이상의 토큰을 약 32K 크기의 청크로 나누어 처리하는 청크형 컨텍스트 프로세싱을 적용했다. LSE(Log-Sum-Exp) 기반의 병합 방식을 통해 수치적 안정성을 유지하면서 대규모 컨텍스트를 효율적으로 관리한다.
DeepSeek의 MLA 아키텍처를 위해 전용 백엔드(ROCM_AITER_MLA)를 제공한다. 특히 Decode 단계에서 수작업으로 튜닝된 어셈블리 커널을 사용하여 메모리 대역폭을 최대한 활용하며, 기존 Triton 백엔드 대비 1.2-1.6배의 속도 향상을 기록했다.
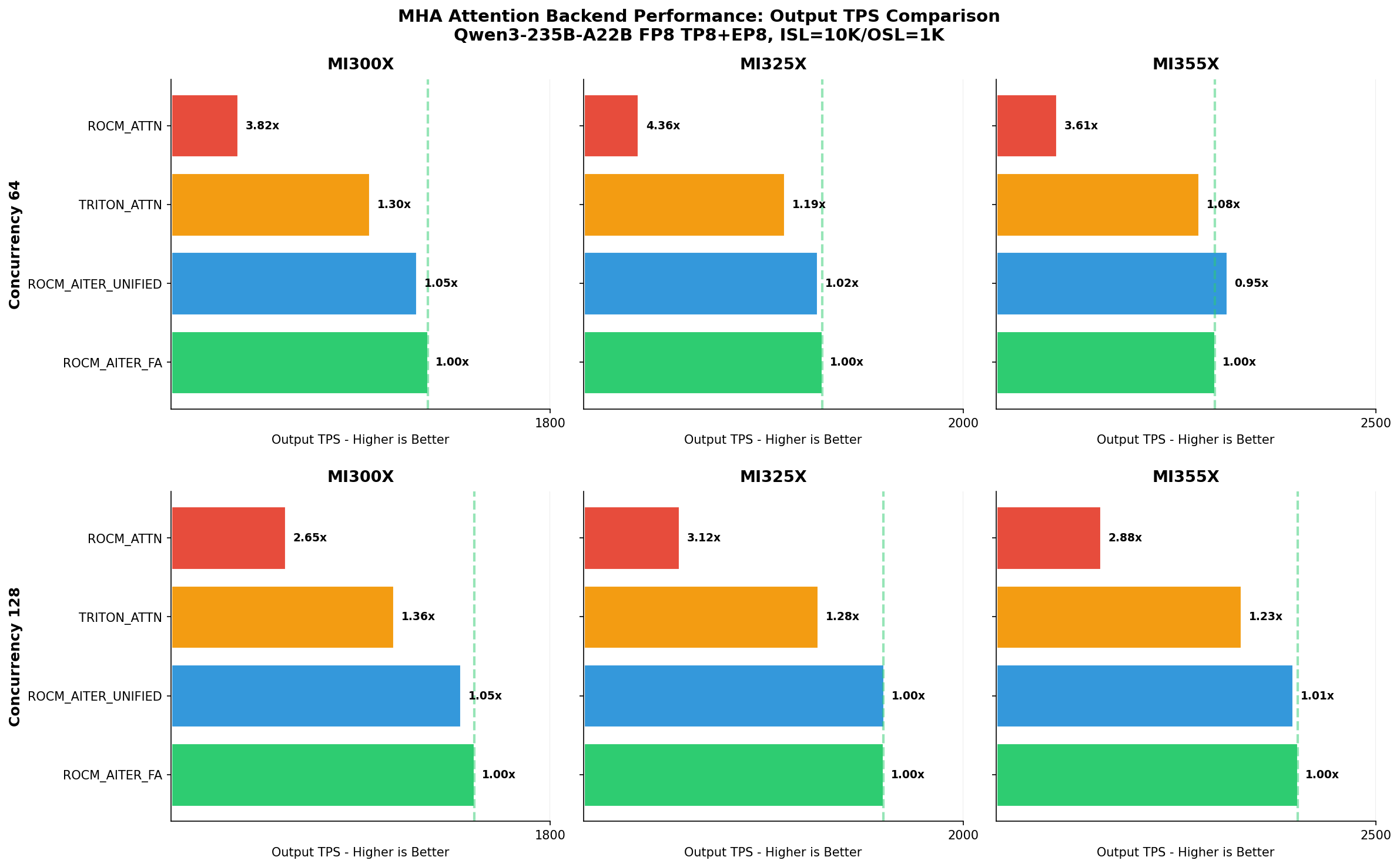
MI300X, MI325X, MI355X GPU에서 Qwen3-235B(MHA) 모델 테스트 결과 ROCM_AITER_FA 백엔드는 레거시 백엔드 대비 최대 4.4배 높은 처리량(TPS)을 달성했다. 이는 하드웨어 프리미티브와 소프트웨어 오케스트레이션의 결합이 성능 최적화의 핵심임을 증명한다.
이미지 분석
실무 Takeaway
- AMD Instinct GPU 환경에서 vLLM 사용 시 VLLM_ROCM_USE_AITER=1 설정을 통해 최적화된 백엔드를 자동 선택하도록 권장한다.
- MHA 모델의 경우 3경로 라우팅과 배치 재정렬을 지원하는 ROCM_AITER_FA 백엔드가 가장 높은 효율을 제공한다.
- DeepSeek-R1과 같은 MLA 모델은 전용 어셈블리 Decode 커널을 통해 메모리 바운드 병목 현상을 해결하고 처리량을 50% 이상 개선할 수 있다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료