핵심 요약
여러 커스텀 AI 모델을 운영할 때 발생하는 GPU 자원 낭비를 해결하기 위해 vLLM과 AWS가 협력하여 MoE 모델용 Multi-LoRA 추론 솔루션을 개발했다. 기존 vLLM은 MoE 레이어에 대한 LoRA 커널이 부족하고 복합적인 희소성 처리 문제가 있었으나, 새로운 fused_moe_lora 커널을 통해 이를 해결했다. Triton 컴파일러 힌트, Split-K 전략, CTA 스위즐링 등 커널 레벨의 최적화를 적용한 결과, GPT-OSS 20B 모델 기준 출력 토큰 속도(OTPS)가 초기 대비 454% 향상되고 첫 토큰 생성 시간(TTFT)은 87% 단축되었다. 이 기술은 Amazon SageMaker AI 및 Bedrock에 적용되어 추가적인 성능 이점을 제공한다.
배경
GPU 아키텍처 기초, CUDA/Triton 프로그래밍 이해, MoE 및 LoRA 개념, vLLM 사용 경험
대상 독자
LLM 추론 엔진 개발자 및 MLOps 엔지니어
의미 / 영향
이번 최적화는 MoE 기반 오픈소스 모델의 상용 서비스 비용을 획기적으로 낮추고, 다중 어댑터 환경에서 vLLM의 경쟁력을 강화한다.
섹션별 상세
이미지 분석
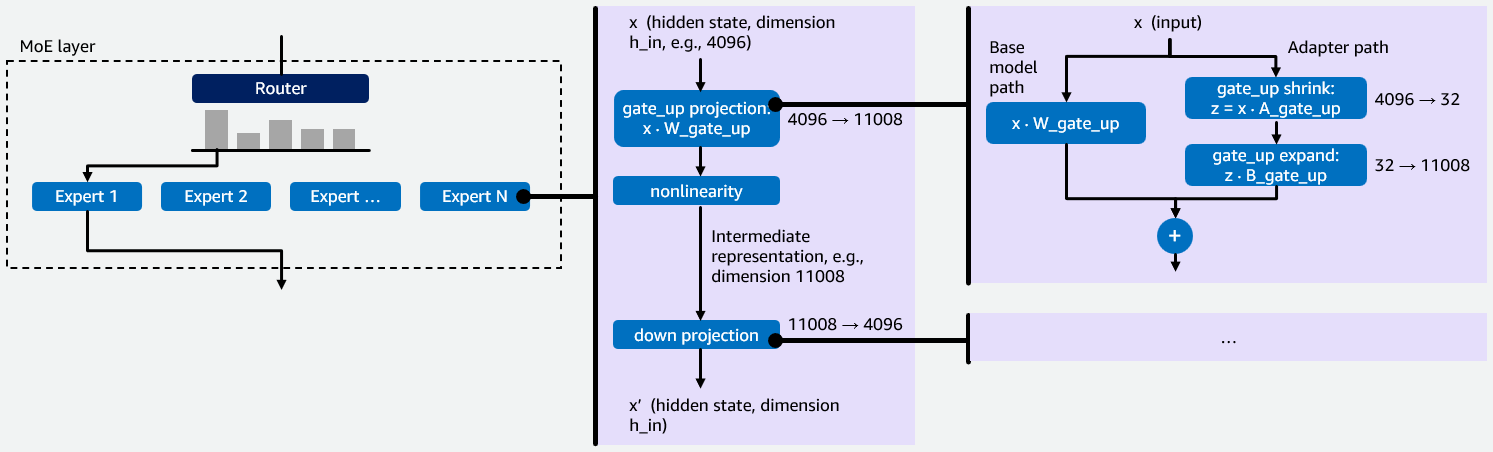
MoE 레이어의 전문가 라우팅과 LoRA 어댑터의 shrink/expand 연산 과정을 시각화하여 복합적인 연산 구조를 보여준다. 각 전문가가 gate_up과 down 프로젝션 시 LoRA 연산을 어떻게 통합하는지 명확히 설명한다.
MoE-LoRA 아키텍처 다이어그램
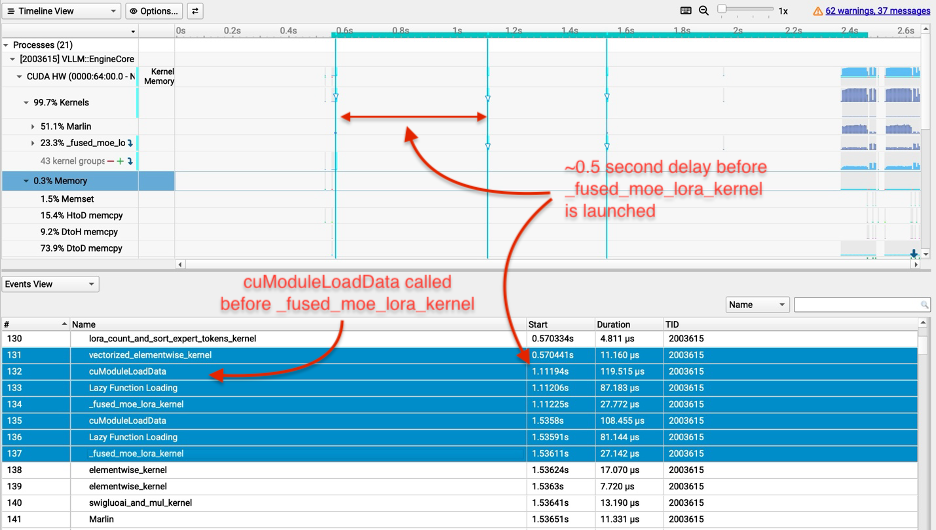
커널 실행 전 cuModuleLoadData 호출로 인해 발생하는 약 0.5초의 지연 시간을 보여준다. 이는 Triton 컴파일러의 재컴파일 오버헤드를 시각적으로 증명하며 최적화의 필요성을 뒷받침한다.
NVIDIA Nsight Systems 프로파일링 결과
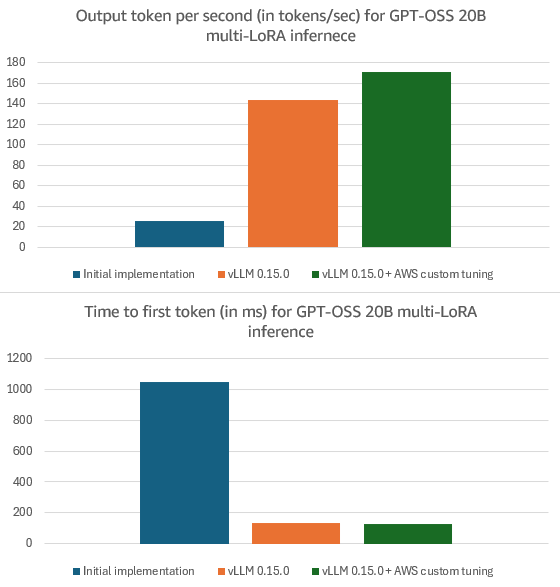
초기 구현, vLLM 0.15.0, AWS 커스텀 튜닝 버전 간의 OTPS 및 TTFT 성능 차이를 수치로 제시한다. 최종 최적화 버전이 초기 대비 압도적인 성능 향상을 달성했음을 입증한다.
버전 및 튜닝별 성능 비교 차트
실무 Takeaway
- MoE 모델에서 Multi-LoRA를 사용하면 GPU 활용도를 극대화하여 유휴 자원 비용을 획기적으로 절감할 수 있다.
- Triton 커널 작성 시 do_not_specialize 힌트를 활용하여 가변 입력 길이에 따른 불필요한 재컴파일 오버헤드를 제거해야 한다.
- LoRA와 같이 한쪽 차원이 매우 작은 행렬 연산에서는 Split-K와 CTA 스위즐링 기법이 성능 향상의 핵심적인 역할을 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료