핵심 요약
AI 모델 평가가 과거의 저렴한 비용 단계를 지나 이제는 수만 달러의 예산이 필요한 연산 병목 구간에 진입했다. Holistic Agent Leaderboard(HAL)의 분석에 따르면 9개 모델을 9개 벤치마크로 평가하는 데 약 40,000달러가 소요되며, 특히 에이전트 기반 평가와 과학적 학습 평가(The Well 등)는 압축이 어려워 비용이 기하급수적으로 늘어난다. 이러한 고비용 구조는 자본력이 부족한 학계나 중소 연구소의 독립적 검증을 가로막는 장벽이 되고 있다. 따라서 평가 로그를 표준화된 형식으로 공유하여 중복 비용을 줄이는 'Every Eval Ever' 프로젝트와 같은 공동체적 노력이 필수적이다.
배경
LLM 벤치마크(MMLU, HELM 등)에 대한 기본 지식, AI 에이전트 및 스캐폴딩 개념, GPU 연산 비용 및 API 과금 구조에 대한 이해
대상 독자
AI 모델 평가 연구자, LLM 서비스 아키텍트, AI 정책 및 거버넌스 담당자
의미 / 영향
AI 평가 비용이 급증함에 따라 모델 개발 능력보다 평가 능력이 생태계의 새로운 진입 장벽이 될 것입니다. 이는 평가 데이터의 공개와 표준화된 벤치마킹 프로토콜 공유가 기술 발전만큼이나 중요해졌음을 의미하며, 비용을 고려하지 않은 성능 경쟁은 지속 가능하지 않다는 경고를 던집니다.
섹션별 상세
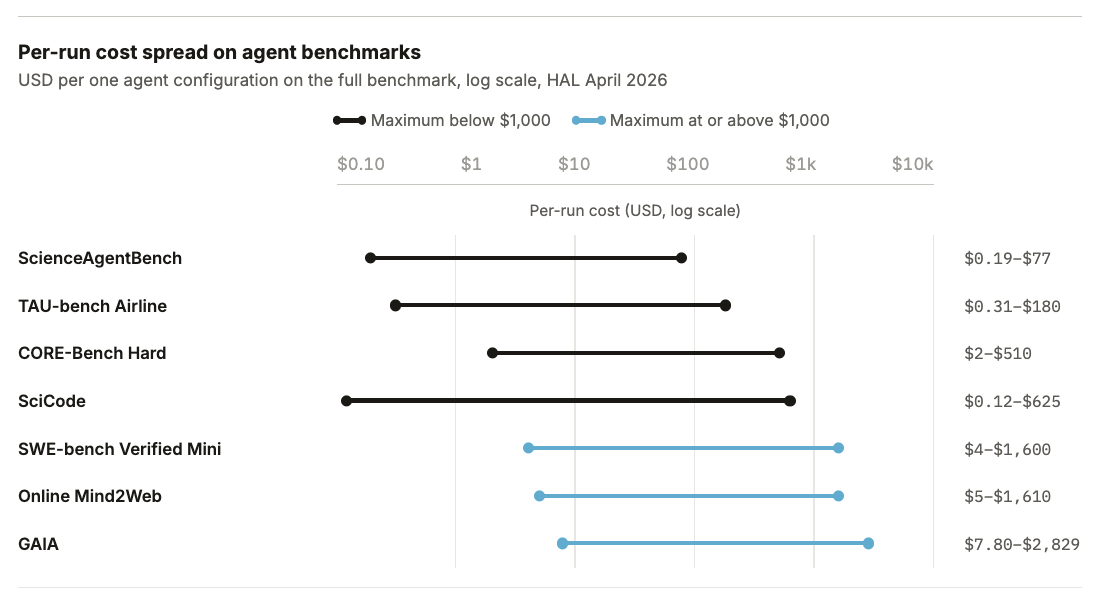
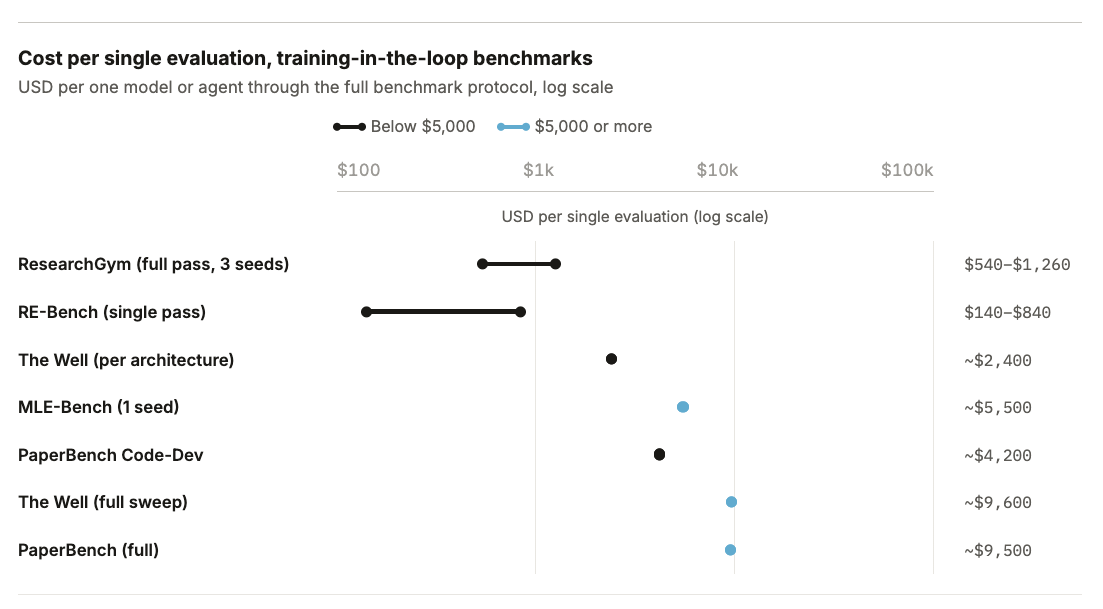
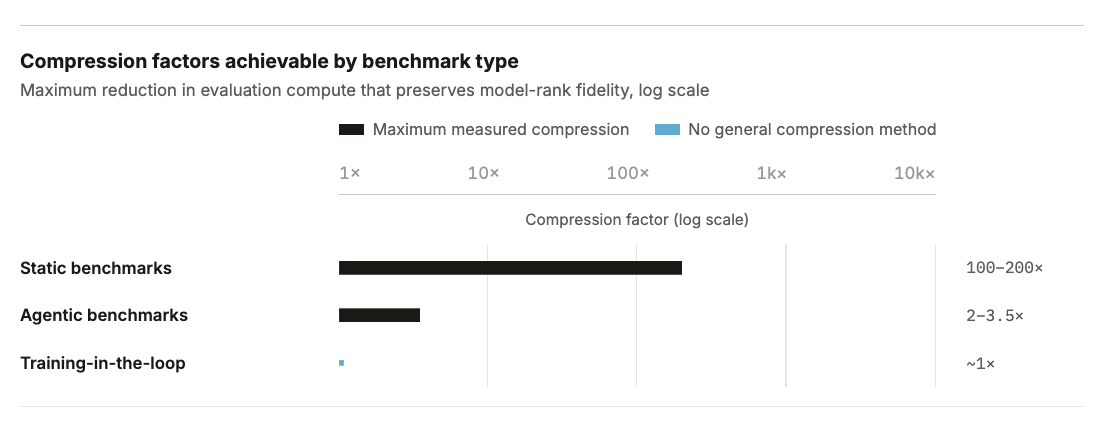
실무 Takeaway
- 에이전트 시스템 구축 시 성능 대비 비용 효율성을 따지는 Pareto-efficient 구성을 선택하여 불필요한 토큰 낭비를 막아야 한다.
- 평가 비용 절감을 위해 EvalEval Coalition의 'Every Eval Ever'와 같은 표준화된 로그 공유 형식을 채택하여 중복 평가를 방지해야 한다.
- 리더보드 확인 시 단순 정확도뿐만 아니라 투입된 비용(Cost-aware) 지표를 함께 검토하여 실제 운영 환경에서의 경제성을 판단해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.