이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
AI 산업이 대규모 학습 시대를 지나 실제 서비스와 자율적 에이전트가 구동되는 '추론의 변곡점'에 도달했습니다. 엔비디아의 젠슨 황과 오픈AI의 샘 알트먼 등 업계 리더들은 추론 연산이 전략적 자산이 되었음을 강조하며, 특히 에이전트의 복잡한 워크로드를 처리하기 위한 CPU의 역할이 재조명되고 있습니다. 하드웨어 측면에서는 GPU와 CPU의 비율이 1:1에 가까워지는 아키텍처 변화가 나타나고 있으며, 소프트웨어적으로는 프롬프트 캐싱과 에이전트 하네스 엔지니어링을 통한 효율화가 핵심 과제로 부상했습니다. 이러한 변화는 모델의 지능뿐만 아니라 시스템 전체의 추론 처리량과 비용 최적화가 경쟁의 중심이 되었음을 시사합니다.
배경
LLM 추론 메커니즘(Prefill/Decode)에 대한 이해, GPU 및 CPU 하드웨어 아키텍처 기초 지식, 에이전트 워크플로 및 오케스트레이션 개념
대상 독자
AI 인프라 엔지니어, LLM 애플리케이션 개발자, AI 전략 기획자
의미 / 영향
AI 산업의 핵심 지표가 '학습 효율'에서 '추론 경제성 및 에이전트 실행 속도'로 완전히 이동했습니다. 이는 하드웨어 시장에서 CPU의 재부상과 소프트웨어 시장에서 에이전트 운영 플랫폼(AgentOps)의 중요성을 동시에 강화할 것입니다.
섹션별 상세
AI 모델이 단순 생성을 넘어 추론과 행동을 수행하면서 연산 수요가 지난 2년간 약 100만 배 증가했습니다. 젠슨 황은 AI가 생각하고, 행동하고, 읽고, 추론하는 모든 과정이 추론(Inference)에 해당하며, 이제는 학습보다 추론이 산업의 중심이라고 선언했습니다.
에이전트 중심의 워크로드가 증가하면서 과거 GPU에 집중되었던 예산이 다시 CPU로 이동하는 추세가 관찰됩니다. 인텔 CEO 립부 탄은 에이전트가 소프트웨어를 시뮬레이션하고 오케스트레이션을 수행하는 과정에서 CPU가 핵심 제어 평면(Control Plane) 역할을 하며 수요를 견인하고 있다고 분석했습니다.
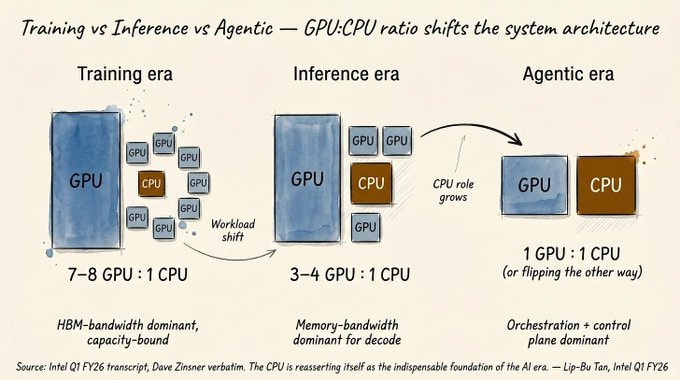

추론 효율을 극대화하기 위해 Prefill과 Decode 과정을 분리하는 하드웨어 및 소프트웨어 디스어그리게이션(Disaggregation)이 표준으로 자리 잡고 있습니다. 엔비디아, 인텔, 아마존 등 주요 기업들은 Groq나 Cerebras와 같은 특화된 아키텍처를 도입하거나 관련 기업을 인수하며 추론 전용 인프라 구축에 박차를 가하고 있습니다.
코딩 에이전트 분야에서는 모델 자체의 성능보다 에이전트 루프의 시스템 엔지니어링과 하네스(Harness) 품질이 성능을 결정짓는 핵심 요소로 부상했습니다. OpenAI의 Codex나 Cursor SDK는 영구적인 컨텍스트 유지와 도구 오케스트레이션을 통해 에이전트 워크플로 속도를 최대 40%까지 향상시키는 인프라적 접근을 보여주고 있습니다.
오픈 소스 모델 진영의 가격 경쟁과 효율화가 가속화되면서 기업용 시장의 파레토 효율 곡선이 변화하고 있습니다. Mistral Medium 3.5와 IBM Granite 4.1 등은 단순 벤치마크 점수보다 토큰 효율성과 엔터프라이즈 신뢰성에 집중하며 엣지 및 온프레미스 배포 환경을 공략하고 있습니다.
실무 Takeaway
- 프로덕션 환경의 AI 에이전트 성능을 높이려면 모델 파라미터 증대보다 에이전트 하네스(Harness)와 도구 오케스트레이션 레이어의 최적화에 집중해야 합니다.
- 반복적인 컨텍스트가 발생하는 RAG나 에이전트 시스템에서는 프롬프트 캐싱과 WebSocket 기반의 상태 유지 API를 활용하여 지연 시간을 최대 40%까지 단축할 수 있습니다.
- 하드웨어 전략 수립 시 GPU 단독 성능뿐만 아니라 에이전트 제어와 시뮬레이션을 위한 CPU 대역폭 및 메모리 성능의 균형을 고려한 1:1 비율의 아키텍처 검토가 필요합니다.
언급된 리소스
API DocsCursor SDK
GitHubvLLM Project
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 04. 30.수집 2026. 04. 30.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.