핵심 요약
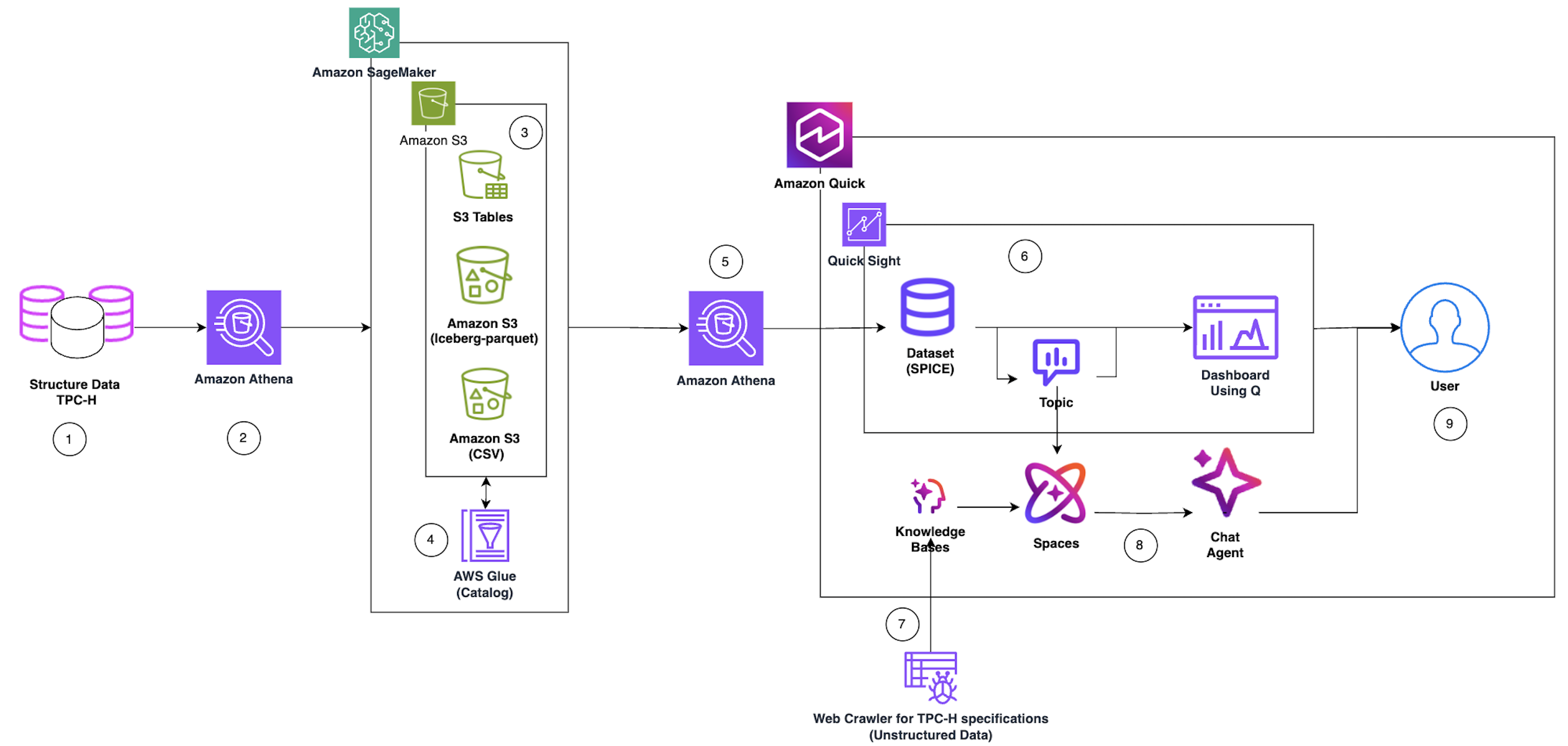
현대 기업이 직면한 방대한 데이터 레이크 분석의 기술적 장벽을 해결하기 위해 Amazon Quick의 에이전틱 AI를 활용한 셀프 서비스 분석 아키텍처를 제안합니다. 이 시스템은 Amazon S3, Athena, AWS Glue를 기반으로 구축된 레이크하우스에서 구조화된 데이터와 비구조화된 지식 베이스를 통합하여 관리합니다. 사용자는 SQL 지식 없이도 자연어 인터페이스를 통해 복잡한 데이터셋을 쿼리하고 비즈니스 인사이트를 즉시 도출할 수 있습니다. TPC-H 벤치마크 데이터셋을 활용한 실습을 통해 데이터 준비부터 AI 에이전트 배포까지의 전 과정을 구체적인 단계로 입증합니다.
배경
AWS 계정 및 Amazon Quick 계정, S3, Athena, AWS Glue에 대한 기본 지식, IAM 및 Lake Formation 권한 관리 이해
대상 독자
데이터 엔지니어, BI 분석가, 클라우드 아키텍트
의미 / 영향
이 아키텍처는 데이터 분석의 진입 장벽을 낮추어 현업 담당자가 데이터 팀의 도움 없이 직접 인사이트를 얻게 합니다. 특히 구조화된 수치 데이터와 비구조화된 문서를 통합 분석함으로써 데이터의 의미까지 파악하는 고도화된 AI 분석 환경을 제공합니다.
섹션별 상세
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.customer_csv (
C_CUSTKEY INT,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INT,
C_PHONE STRING,
C_ACCTBAL DOUBLE,
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/customer/'
TBLPROPERTIES ('classification' = 'csv');S3에 저장된 CSV 데이터를 Athena에서 쿼리하기 위해 외부 테이블을 생성하는 예시
CREATE TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg
WITH (
table_type = 'ICEBERG',
format = 'PARQUET',
is_external = false,
partitioning = ARRAY['o_orderdate'],
location = 's3://amzn-s3-demo-bucket/tpch_iceberg/orders/')
AS SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv
WHERE O_ORDERDATE BETWEEN '1998-06-01' AND '1998-12-31';기존 CSV 데이터를 Apache Iceberg 포맷의 테이블로 변환하여 저장하는 CTAS 쿼리
실무 Takeaway
- 반복적인 데이터 요청 업무를 줄이려면 Amazon Quick Topic을 설정하여 기술적 컬럼명을 비즈니스 용어로 매핑하는 시맨틱 레이어를 구축해야 한다.
- 대규모 데이터셋의 조인 성능을 최적화하려면 Quick 내부 조인 대신 Athena에서 Custom SQL을 사용해 데이터를 미리 조인한 후 SPICE에 로드하는 방식을 권장한다.
- AI 에이전트의 답변 정확도를 높이려면 데이터 사전(Data Dictionary)과 같은 비구조화된 문서를 지식 베이스로 연결하여 수치 데이터에 대한 문맥적 근거를 제공해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.