핵심 요약
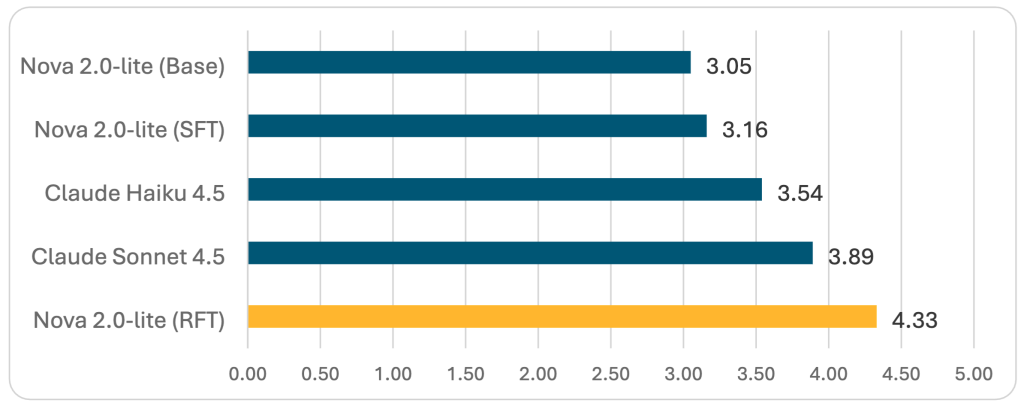
본 아티클은 수동 레이블링 비용을 줄이면서 모델의 출력 품질을 정렬할 수 있는 강화 파인튜닝(RFT) 기법을 다룬다. 특히 별도의 LLM이 응답을 평가하는 LLM-as-a-judge(RLAIF) 방식의 작동 원리와 Amazon Nova 모델에 적용하는 6단계 구현 공정을 상세히 설명한다. 법률 계약서 검토 사례 연구를 통해 RFT를 적용한 Nova 2 Lite 모델이 Claude 4.5 시리즈보다 높은 4.33점의 종합 점수를 기록했음을 입증한다. 결과적으로 RFT는 SFT에서 발생하는 반복 생성 등의 아티팩트를 제거하고 복잡한 도메인에서 높은 일반화 성능을 제공한다.
배경
Reinforcement Learning (RL) 기본 개념, Amazon Bedrock 및 AWS Lambda 사용 경험, SFT(Supervised Fine-Tuning)와 RFT의 차이점에 대한 이해
대상 독자
도메인 특화 LLM을 구축하거나 프로덕션 환경에서 모델 정렬 품질을 높이려는 AI 엔지니어 및 MLOps 전문가
의미 / 영향
이 기술은 고가의 수동 데이터 제작 없이도 소형 모델(Nova 2 Lite 등)이 특정 도메인에서 대형 범용 모델을 능가할 수 있음을 보여줍니다. 특히 법률, 의료, 금융과 같이 정교한 규칙과 근거가 중요한 분야에서 LLM-as-a-judge 기반의 RFT는 필수적인 고도화 전략이 될 것입니다.
섹션별 상세
실무 Takeaway
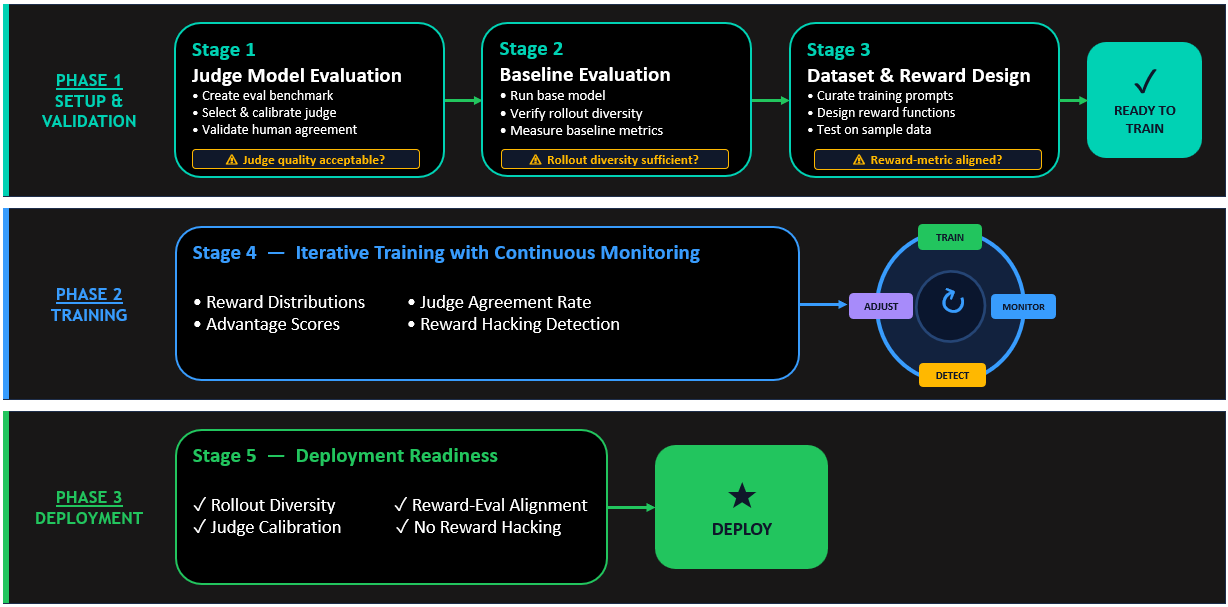
- 복잡한 도메인 정렬 시 SFT보다 RFT를 우선 고려하면 반복 생성과 같은 학습 아티팩트를 효과적으로 제거하고 모델의 견고함을 높일 수 있다.
- LLM-as-a-judge 설계 시 1-10점 척도보다 불리언(Pass/Fail) 방식의 루브릭을 사용하면 평가의 일관성을 높이고 모델의 변동성을 줄일 수 있다.
- 비용 최적화를 위해 모든 응답을 LLM으로 평가하지 말고, 형식 검증이나 안전 필터 같은 결정론적 규칙을 Lambda 함수 앞단에 배치하여 필터링해야 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.