핵심 요약
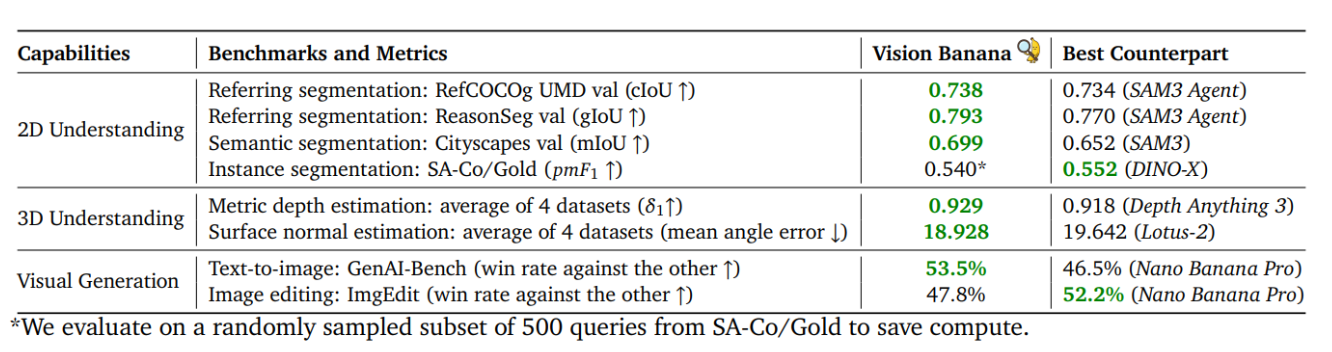
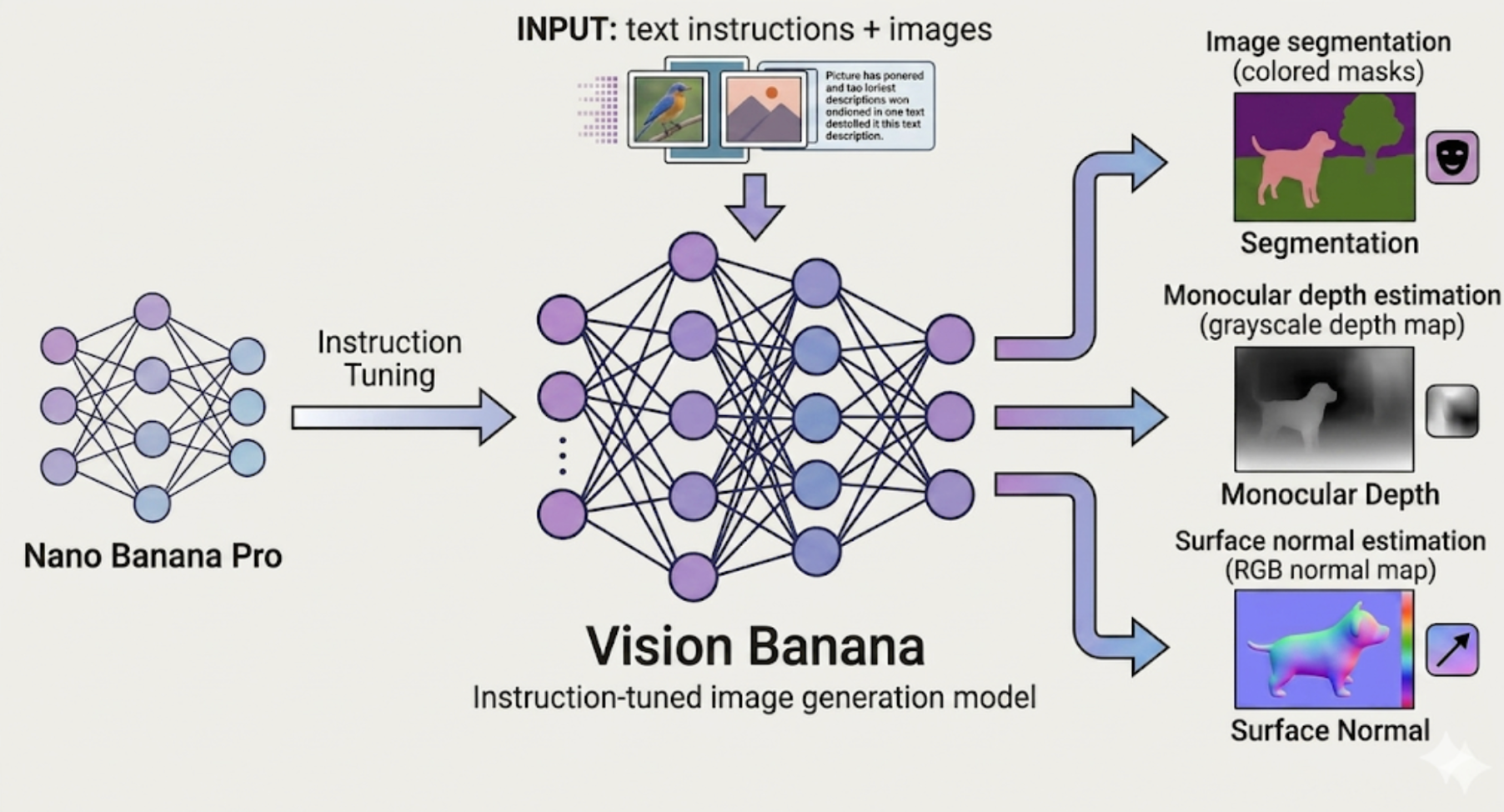
Google DeepMind는 이미지 생성 모델이 단순한 픽셀 생성을 넘어 시각적 이해 능력을 갖출 수 있음을 증명하는 Vision Banana를 발표했다. 이 모델은 Nano Banana Pro를 기반으로 가벼운 인스트럭션 튜닝을 거쳐 세그멘테이션, 깊이 추정, 표면 법선 추정 등 다양한 비전 작업을 수행하는 범용 모델로 변모했다. 모든 출력 공간을 RGB 이미지로 파라미터화하여 별도의 태스크 전용 헤드 없이 텍스트 프롬프트만으로 작업을 제어하는 것이 특징이다. 벤치마크 결과 SAM 3나 Depth Anything 3와 같은 기존 전문 모델들을 능가하는 성능을 보여주며, 이미지 생성 사전 학습이 비전 분야의 새로운 파운데이션 모델 표준이 될 가능성을 제시했다.
배경
컴퓨터 비전 기본 개념 (Segmentation, Depth Estimation), LLM 인스트럭션 튜닝(Instruction-tuning)에 대한 이해, 제로샷 학습(Zero-shot learning) 개념
대상 독자
컴퓨터 비전 엔지니어, 로보틱스 및 자율주행 시스템 개발자, AI 연구원
의미 / 영향
이 연구는 이미지 생성 모델이 비전 이해 작업에서도 전문 모델을 압도할 수 있음을 보여줌으로써, 비전 AI의 패러다임이 '태스크별 전문 모델'에서 '범용 생성형 파운데이션 모델'로 전환될 것임을 시사합니다. 특히 클라우드 기반 비전 파이프라인에서 모델 통합을 통한 운영 효율화에 큰 영향을 미칠 것입니다.
섹션별 상세
실무 Takeaway
- 이미지 생성 사전 학습은 LLM의 텍스트 사전 학습과 유사하게 비전 분야에서 강력한 범용 파운데이션 모델을 구축하는 핵심 기법으로 자리 잡을 것이다.
- 복잡한 비전 파이프라인을 운영하는 개발자는 여러 전문 모델을 체이닝하는 대신 Vision Banana와 같은 단일 범용 모델을 사용하여 인프라 비용과 엔지니어링 공수를 절감할 수 있다.
- 모든 비전 출력을 RGB 이미지로 인코딩하는 방식은 새로운 태스크 추가 시 아키텍처 변경 없이 데이터와 프롬프트만으로 확장 가능한 유연성을 제공한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.