핵심 요약
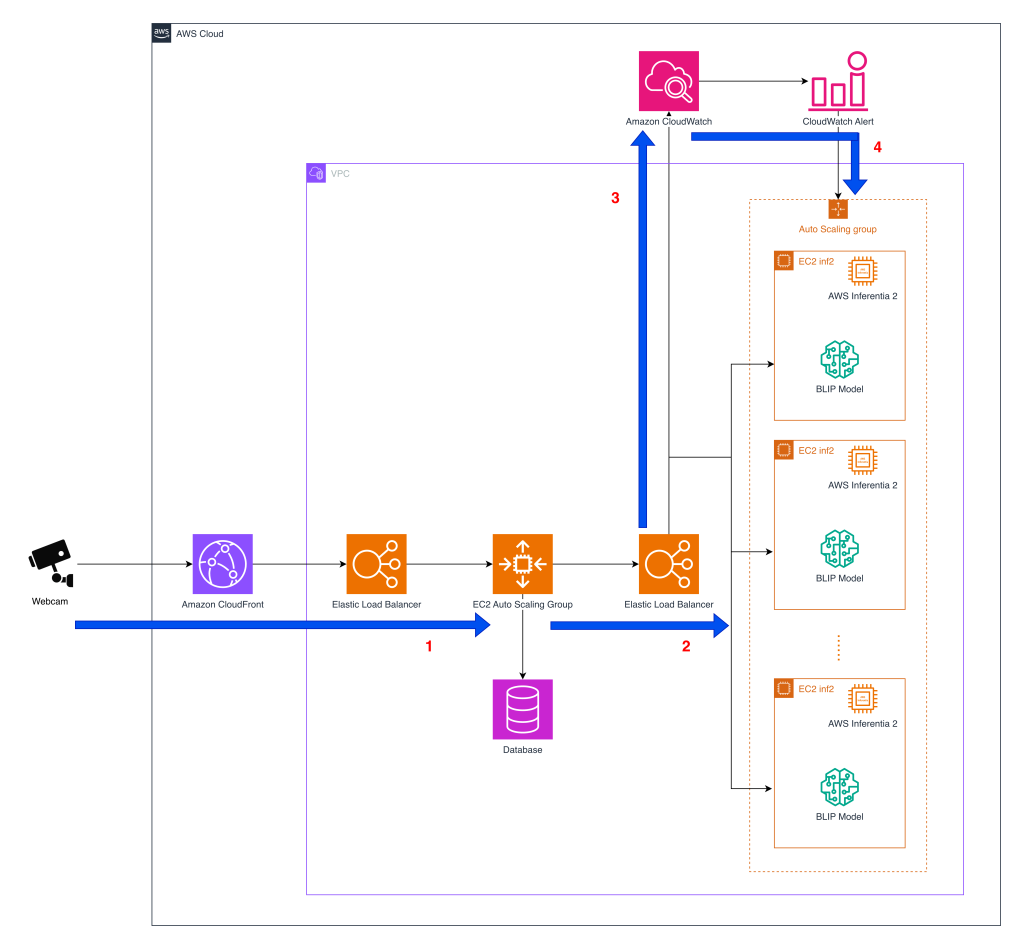
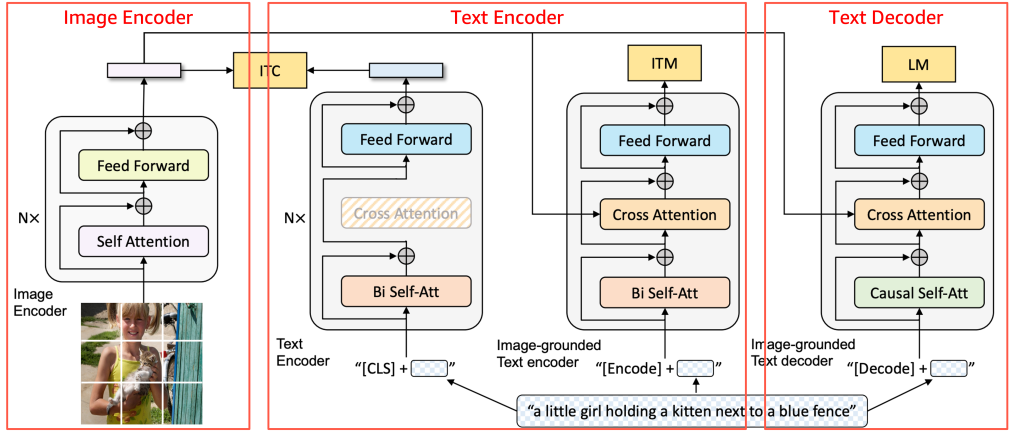
대규모 실시간 반려동물 행동 감지 서비스를 운영하는 Tomofun은 기존 GPU 기반 추론의 높은 비용 문제를 해결하기 위해 AWS Inferentia2 전용 칩을 도입했다. BLIP 모델의 핵심 로직을 수정하지 않고 Neuron SDK와 호환되는 경량 래퍼 클래스를 사용하여 이미지 인코더, 텍스트 인코더 및 디코더를 독립적으로 컴파일했다. 스트레스 테스트 결과 Inf2.xlarge 인스턴스에서 기존 GPU 온디맨드 대비 83%의 비용 절감 효과를 거두면서도 실시간 알림에 필요한 낮은 지연 시간과 높은 처리량을 확보했다. 이 사례는 대규모 시각-언어 모델(VLM) 서비스에서 전용 가속기를 통해 성능 타협 없이 운영 효율성을 극대화할 수 있음을 입증했다.
배경
PyTorch 프레임워크에 대한 이해, AWS EC2 및 Auto Scaling 아키텍처 지식, 기본적인 딥러닝 모델 컴파일 및 추론 개념
대상 독자
대규모 실시간 AI 추론 서비스를 운영하며 비용 최적화를 고민하는 ML 엔지니어 및 클라우드 아키텍트
의미 / 영향
이 사례는 고비용 GPU에 의존하던 시각-언어 모델(VLM) 추론을 전용 가속기로 성공적으로 이전할 수 있음을 보여줍니다. 특히 모델 코드 수정 없이 래퍼만으로 최적화가 가능하다는 점은 기업들이 성능 저하 없이 운영 비용을 획기적으로 낮출 수 있는 실질적인 경로를 제시합니다.
섹션별 상세
실무 Takeaway
- 대규모 실시간 AI 서비스에서 GPU 대신 AWS Inferentia2 전용 가속기를 사용하면 동일 성능 대비 최대 83%의 비용 절감이 가능하다.
- Neuron SDK의 trace API와 경량 래퍼 클래스를 활용하면 기존 PyTorch 모델 로직을 수정하지 않고도 전용 하드웨어용으로 신속하게 이식할 수 있다.
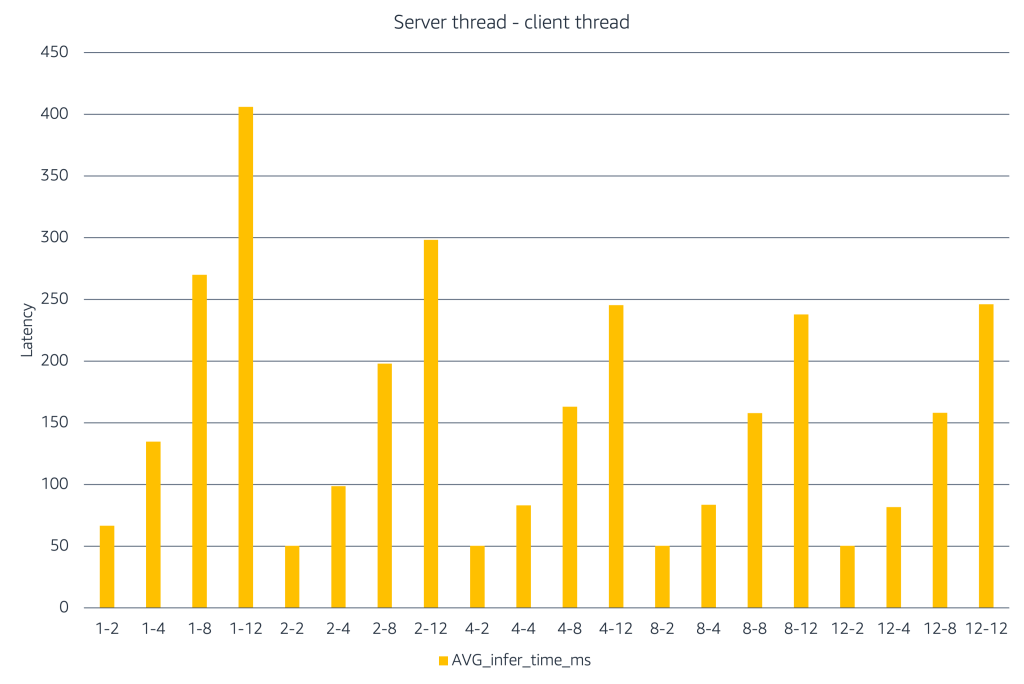
- 성능 최적화를 위해 서버 스레드와 클라이언트 동시성 조합에 따른 지연 시간 변화를 벤치마킹하여 프로덕션 환경의 처리량 한계를 설정해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.