이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
전통적인 피처 엔지니어링은 도메인 지식에 의존한 수동 변환 방식이라 텍스트나 로그 같은 비정형 데이터의 깊은 의미를 놓치기 쉽다. LLM을 활용하면 데이터의 맥락과 시맨틱 의미를 파악하여 고차원 벡터나 구조화된 신호로 자동 변환할 수 있어 ML 파이프라인의 성능을 극대화한다. 본문은 임베딩 추출, 프롬프트 기반 특징 추출, 하이브리드 피처 공간 구축 등 구체적인 기법을 Python 예제와 함께 설명한다. 최종적으로 LLM이 추출한 특징과 기존 수치 데이터를 결합해 분류 모델의 정확도를 높이는 엔드투엔드 워크플로우를 입증한다.
배경
Python 프로그래밍, Scikit-learn 기초, Transformers 라이브러리 이해
대상 독자
데이터 과학자 및 ML 엔지니어
의미 / 영향
이 기술은 데이터 전처리 과정에서 인간의 개입을 최소화하고 비정형 데이터의 가치를 극대화합니다. 특히 금융이나 의료처럼 복잡한 텍스트 로그가 많은 산업군에서 LLM을 피처 생성기로 활용함으로써 기존 ML 모델의 예측력을 획기적으로 높일 수 있습니다.
섹션별 상세
전통적인 방식은 TF-IDF나 원-핫 인코딩처럼 단어 간의 관계나 감정적 맥락을 무시하는 통계적 패턴에 의존한다. LLM 기반 방식은 사전 학습된 지식을 바탕으로 데이터의 숨겨진 의도와 시맨틱 관계를 파악하여 더 풍부한 특징을 생성한다. 이를 통해 도메인 전문가의 수작업 시간을 대폭 단축하고 복잡한 데이터에서도 유의미한 신호를 찾아낸다. 결과적으로 단순 수치 변환보다 정교한 모델 입력값을 제공할 수 있다.
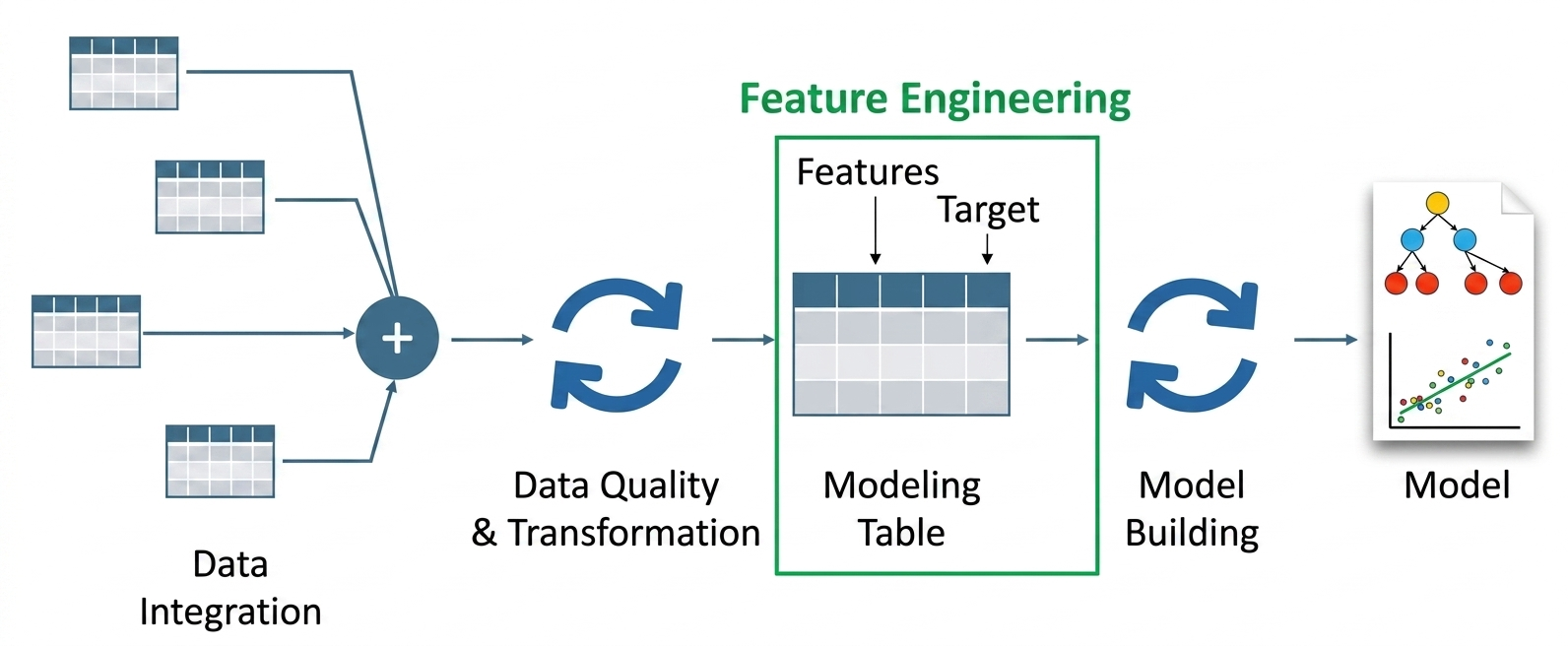
SentenceTransformer와 같은 모델을 사용하여 텍스트를 고밀도 시맨틱 벡터인 임베딩으로 변환하여 모델의 입력 특징으로 활용한다. 임베딩은 단어 빈도 기반의 TF-IDF와 달리 'cat'과 'dog'의 유사성을 인식하는 등 문맥적 의미를 384차원 이상의 벡터 공간에 표현한다. 실제 코드 구현 시 텍스트 리스트를 모델에 입력하면 즉시 수치화된 행렬을 얻을 수 있어 ML 모델에 바로 결합 가능하다. 이는 단순 키워드 매칭을 넘어선 의미론적 분석을 가능하게 한다.
LLM에 특정 프롬프트를 입력하여 비정형 텍스트에서 감성, 제품 이슈, 성능 등 구조화된 정보를 추출하고 이를 독립된 피처 컬럼으로 변환한다. flan-t5-base와 같은 모델을 사용해 리뷰 텍스트에서 '긍정/부정'이나 '과열 여부' 같은 속성을 JSON 형식으로 출력하도록 유도할 수 있다. 추출된 데이터는 범주형 또는 수치형 변수로 변환되어 분류기나 회귀 모델의 학습 데이터로 즉시 사용된다. 사람이 일일이 라벨링하던 작업을 LLM이 대신 수행하여 데이터 전처리 효율을 높인다.
기존의 수치형 데이터(가격, 평점)와 LLM이 생성한 텍스트 임베딩을 결합하여 더 강력한 하이브리드 피처 공간을 구축한다. numpy의 hstack 등을 이용해 정형 데이터 행렬과 비정형 데이터의 벡터 표현을 수평으로 결합하여 하나의 통합된 학습 데이터셋을 만든다. 이 방식은 정형 데이터의 정확성과 비정형 데이터의 풍부한 맥락 정보를 동시에 활용할 수 있게 해준다. 실험 결과, 하이브리드 피처를 사용한 로지스틱 회귀 모델이 감성 분석 작업에서 95%의 높은 정확도를 달성했다.
실무 Takeaway
- 비정형 텍스트가 포함된 ML 프로젝트에서 TF-IDF 대신 SentenceTransformer 임베딩을 사용하면 단어 간 시맨틱 관계를 보존하여 모델 성능을 개선할 수 있다.
- LLM 프롬프트를 활용해 사용자 리뷰에서 '의도(Intent)'나 '고객 유형' 같은 새로운 범주형 특징을 자동 생성하여 타겟팅 모델의 변수로 추가할 수 있다.
- LLM 생성 피처는 일관성 문제가 발생할 수 있으므로 Temperature 설정을 0으로 고정하고 프롬프트 로깅을 통해 재현성을 확보해야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 07.수집 2026. 05. 07.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.