TL;DR
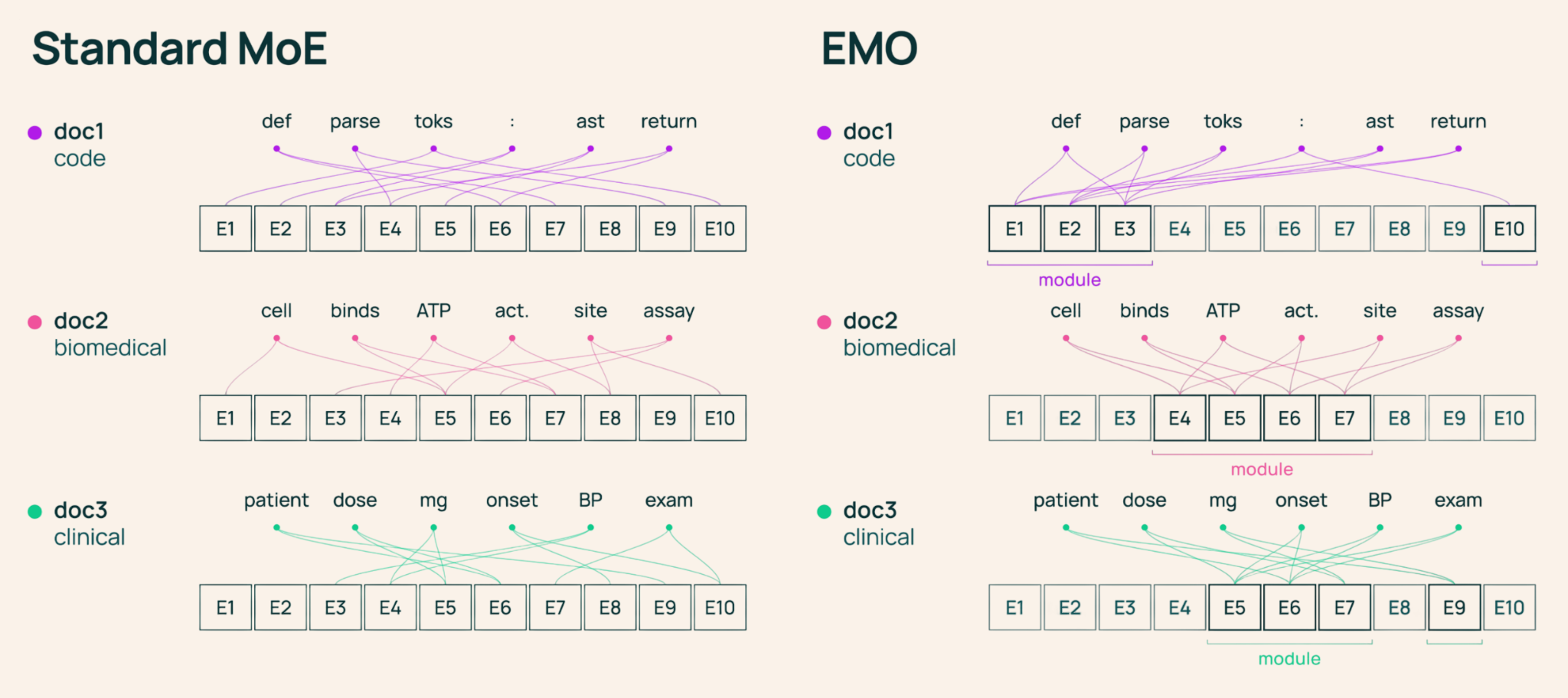
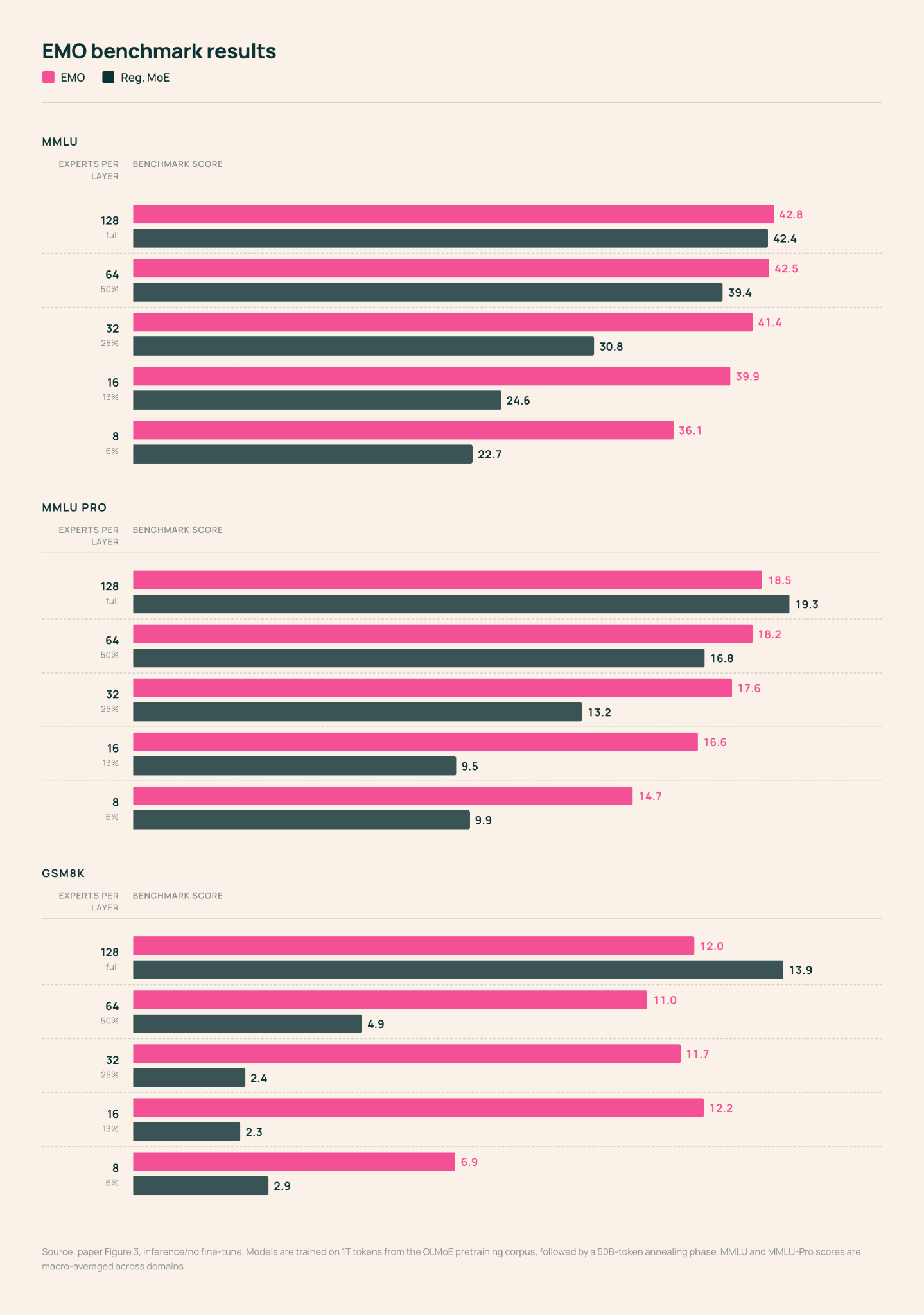
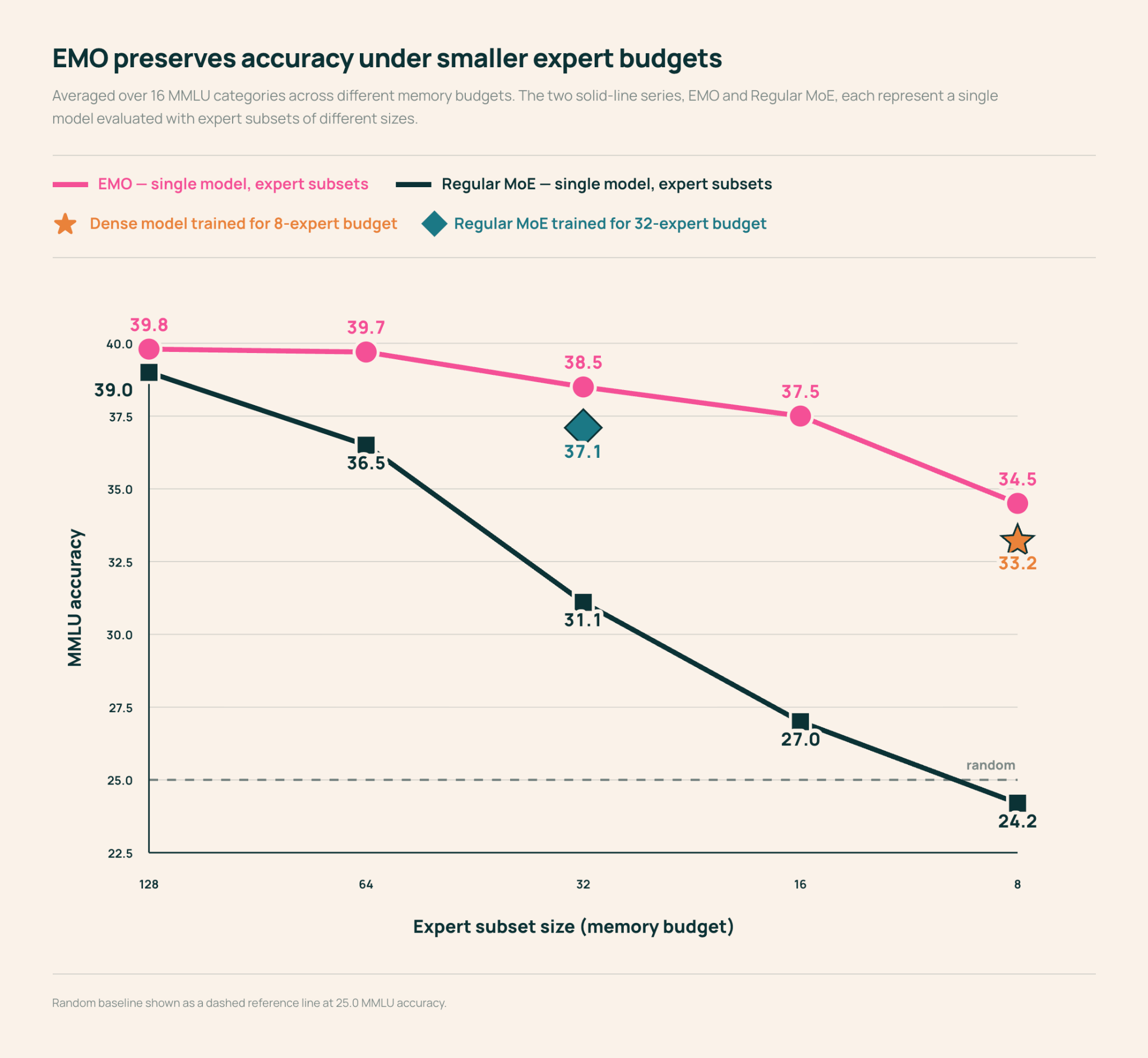
기존 Mixture-of-Experts(MoE) 모델은 전문가들이 문법적 패턴에만 국한되어 전문화되는 경향이 있어 특정 작업에 일부 전문가만 선택적으로 사용하기 어려웠습니다. 연구진은 문서 경계를 약한 감독 신호로 활용하여 동일 문서 내 토큰들이 공유된 전문가 풀을 사용하도록 제한하는 EMO(Emergent Modularity) 학습 방식을 제안했습니다. 이를 통해 전문가들이 수학, 코드, 의료 등 고차원적 도메인 지식을 중심으로 자발적으로 군집화되는 창발적 모듈성이 나타남을 확인했습니다. 결과적으로 EMO는 전체 전문가의 12.5%인 16개 전문가만 활성화하고도 전체 모델에 근접한 성능을 유지하며, 이는 표준 MoE 대비 획기적인 메모리 및 연산 효율성을 제공합니다.
배경
Mixture-of-Experts (MoE) 아키텍처에 대한 이해, LLM 사전 학습(Pretraining) 및 라우팅 메커니즘 지식
대상 독자
LLM 아키텍처 연구자 및 대규모 MoE 모델의 추론 효율성을 개선하고자 하는 MLOps 엔지니어
의미 / 영향
이 연구는 거대 모델을 매번 전체로 사용하는 대신, 필요에 따라 특정 모듈만 조합해 사용하는 '구성 가능한 AI' 시대를 앞당길 것입니다. 특히 하드웨어 자원이 제한된 환경에서 대규모 sparse 모델을 효율적으로 배포하고 도메인별로 최적화하는 새로운 표준을 제시합니다.
섹션별 상세


실무 Takeaway
- 문서 경계를 활용한 라우팅 제약만으로도 인위적인 도메인 라벨링 없이 전문가들의 의미론적 모듈화를 유도할 수 있습니다.
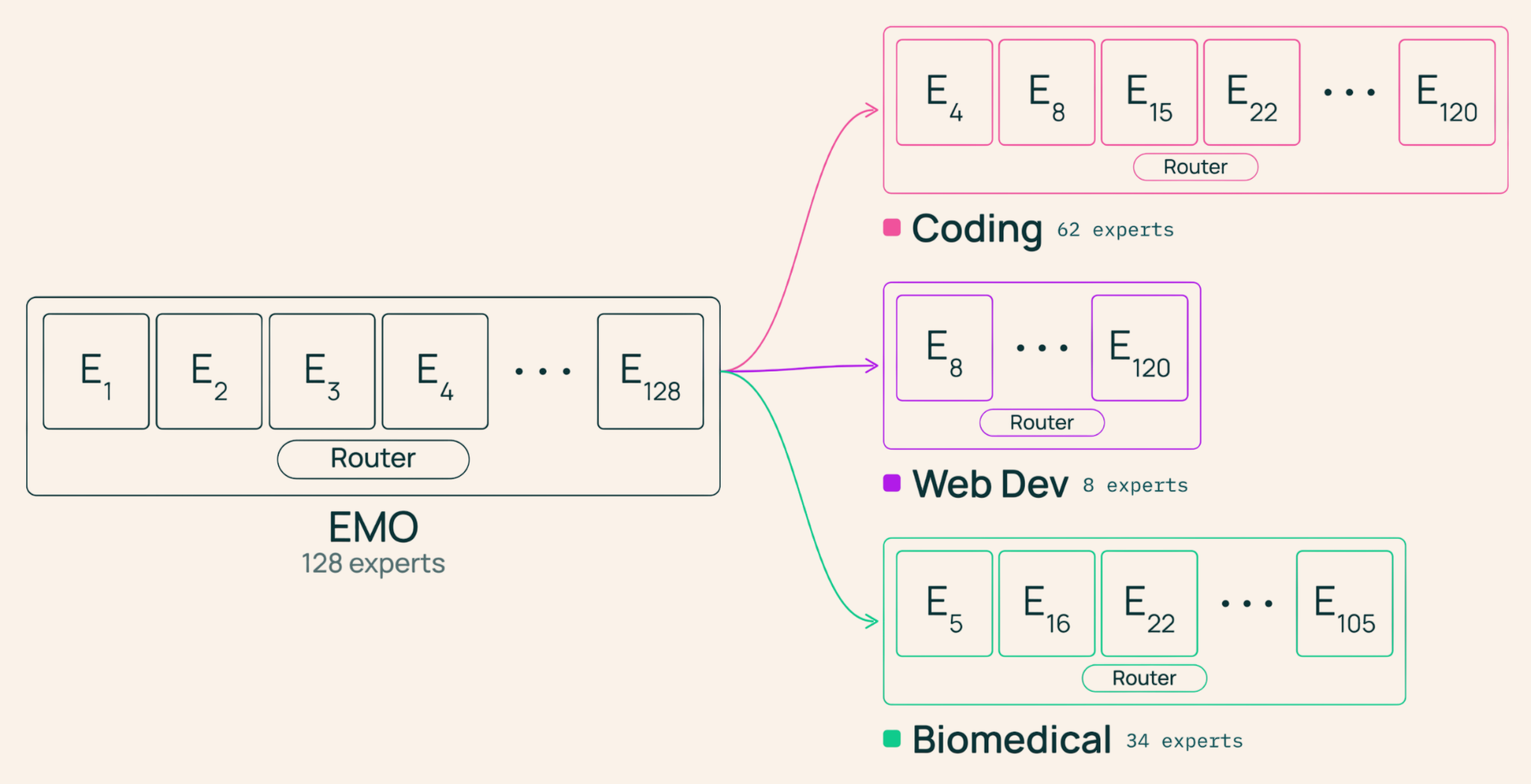
- EMO 아키텍처를 적용하면 특정 도메인 작업 시 전체 파라미터의 1/8 수준인 전문가 서브셋만 로드하여 메모리 사용량을 획기적으로 줄이면서도 성능을 보존할 수 있습니다.
- 단일 예시(Few-shot)만으로도 해당 작업에 최적화된 전문가 모듈을 저비용으로 식별할 수 있어 실무적인 배포 효율성이 매우 높습니다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.