이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대형 언어 모델(LLM)은 범용 작업에는 능숙하지만 기업 고유의 데이터나 전문 용어가 필요한 작업에서는 한계를 보인다. 이를 해결하기 위해 지도 미세 조정(SFT)을 수행하면 특정 도메인 성능은 올라가지만 범용 지능이 하락하는 파멸적 망각 현상이 발생한다. Amazon Nova Forge는 고객 데이터와 자체 큐레이션 데이터를 혼합하는 데이터 믹싱 기능을 통해 이 문제를 해결한다. 실험 결과, 고객 상담 분류 작업에서 성능을 12% 향상시키면서도 MMLU 점수를 베이스라인 수준으로 유지하는 데 성공했다.
배경
LLM Fine-tuning(SFT)에 대한 기본 이해, MMLU 등 모델 평가 벤치마크 지표 지식, Amazon SageMaker 및 Bedrock 환경 지식
대상 독자
기업용 특화 LLM을 구축하고 프로덕션에 배포하려는 AI 엔지니어 및 솔루션 아키텍트
의미 / 영향
이 기술은 기업이 고유 데이터를 학습시키면서도 모델의 추론 및 지시 이행 능력을 잃지 않게 해준다. 이는 단일 모델로 전문 작업과 일반 응대를 모두 처리해야 하는 엔터프라이즈 환경에서 비용과 운영 효율성을 크게 높이는 계기가 된다.
섹션별 상세
Nova Forge의 핵심 기능과 데이터 믹싱: Nova Forge는 사용자가 Nova 모델을 기반으로 자체 프론티어 모델을 구축할 수 있게 돕는 서비스다. 특히 고객의 데이터와 Amazon이 큐레이션한 데이터를 혼합하여 학습시키는 기능을 제공하여 모델의 범용성을 보존한다.

VOC 분류 작업의 복잡성과 도전 과제: 1,420개의 세부 카테고리를 가진 4단계 계층 구조의 고객 피드백 데이터를 분류하는 실험을 진행했다. 데이터의 44.5%가 샘플 5개 미만인 극심한 불균형 상태였으며, 이는 일반적인 파운데이션 모델이 처리하기 매우 어려운 수준이다.
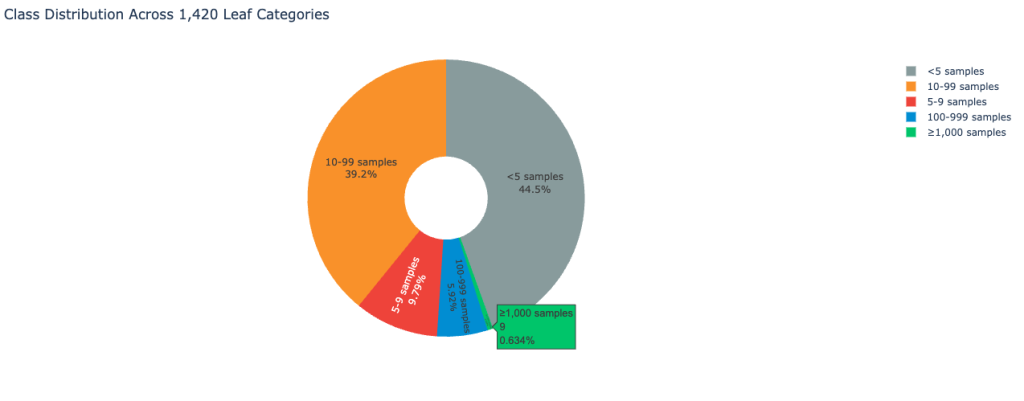
파멸적 망각 현상의 실증적 확인: 고객 데이터로만 전체 파라미터 SFT를 진행했을 때, Nova 2 Lite 모델의 MMLU 점수는 0.75에서 0.47로 급락했다. 오픈소스 모델인 Qwen3-30B의 경우 지시 이행 능력을 거의 상실하는 등 특정 도메인 학습이 범용 지능을 심각하게 훼손함을 확인했다.
데이터 믹싱을 통한 성능 균형 달성: 고객 데이터 75%와 Nova 큐레이션 데이터 25%를 혼합하여 학습시킨 결과, VOC 분류 F1 스코어는 0.38에서 0.50으로 상승했다. 동시에 MMLU 점수는 0.74를 기록하여 베이스라인(0.75)과 거의 차이가 없는 수준으로 범용 지능을 방어했다.
json
[
{
"content": "",
"L1": "",
"L2": "",
"L3": "",
"L4": "",
"emotion": ""
}
]VOC 분류 작업을 위해 모델이 출력해야 하는 JSON 스키마 구조

실무 Takeaway
- 특정 도메인 성능 극대화가 필요할 때는 PEFT보다 전체 파라미터 SFT(Full-rank SFT)가 유리하지만 범용 지능 하락에 유의해야 한다.
- 모델이 여러 워크플로우를 동시에 지원해야 하는 프로덕션 환경이라면 Nova Forge의 데이터 믹싱 기능을 활용해 파멸적 망각을 방지해야 한다.
- 데이터 믹싱 비율을 75:25 정도로 설정함으로써 도메인 성능 향상과 범용 지능 유지 사이의 최적의 균형점을 찾을 수 있다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 03.수집 2026. 03. 03.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.