TL;DR
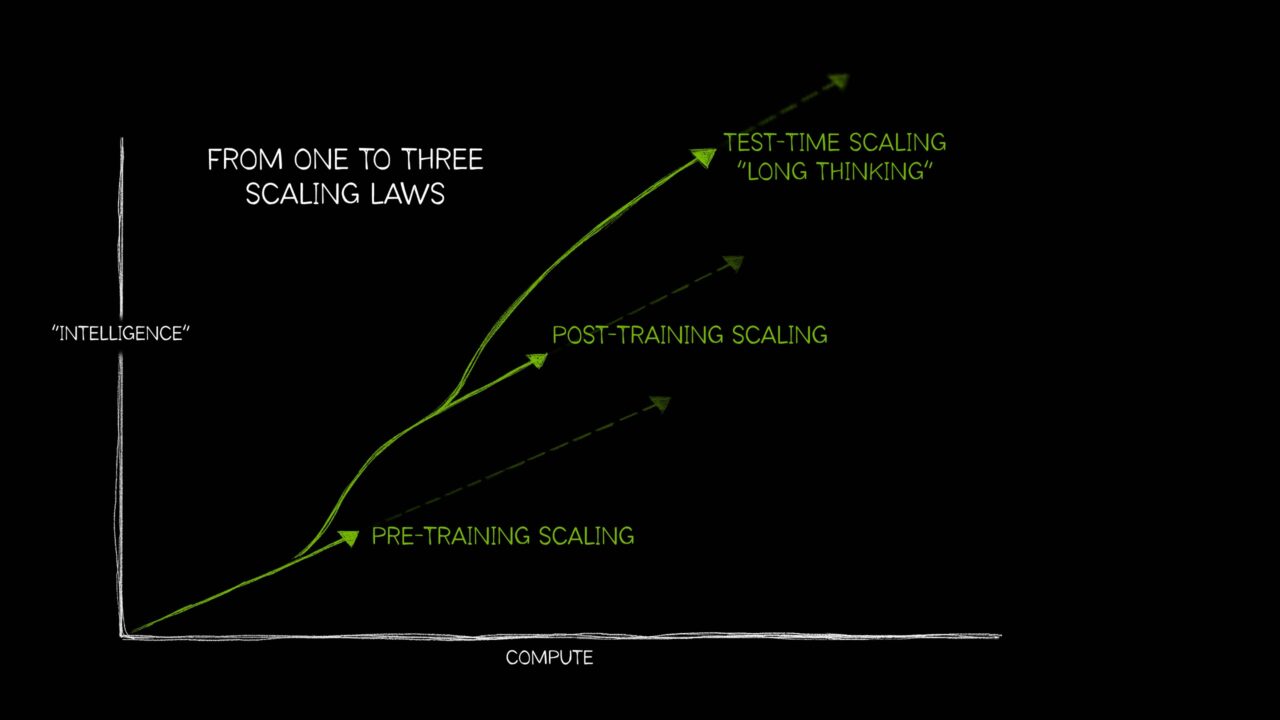
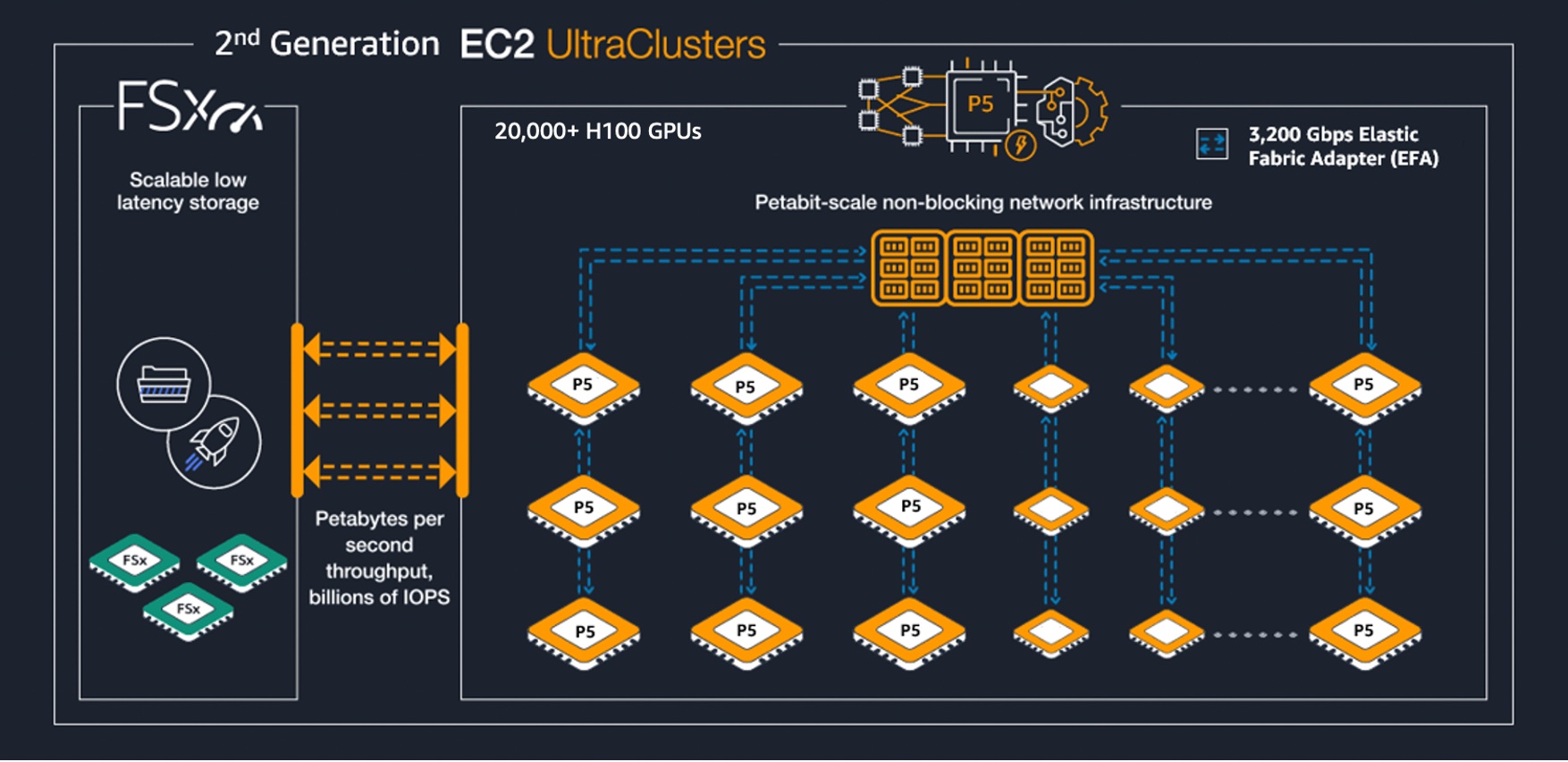
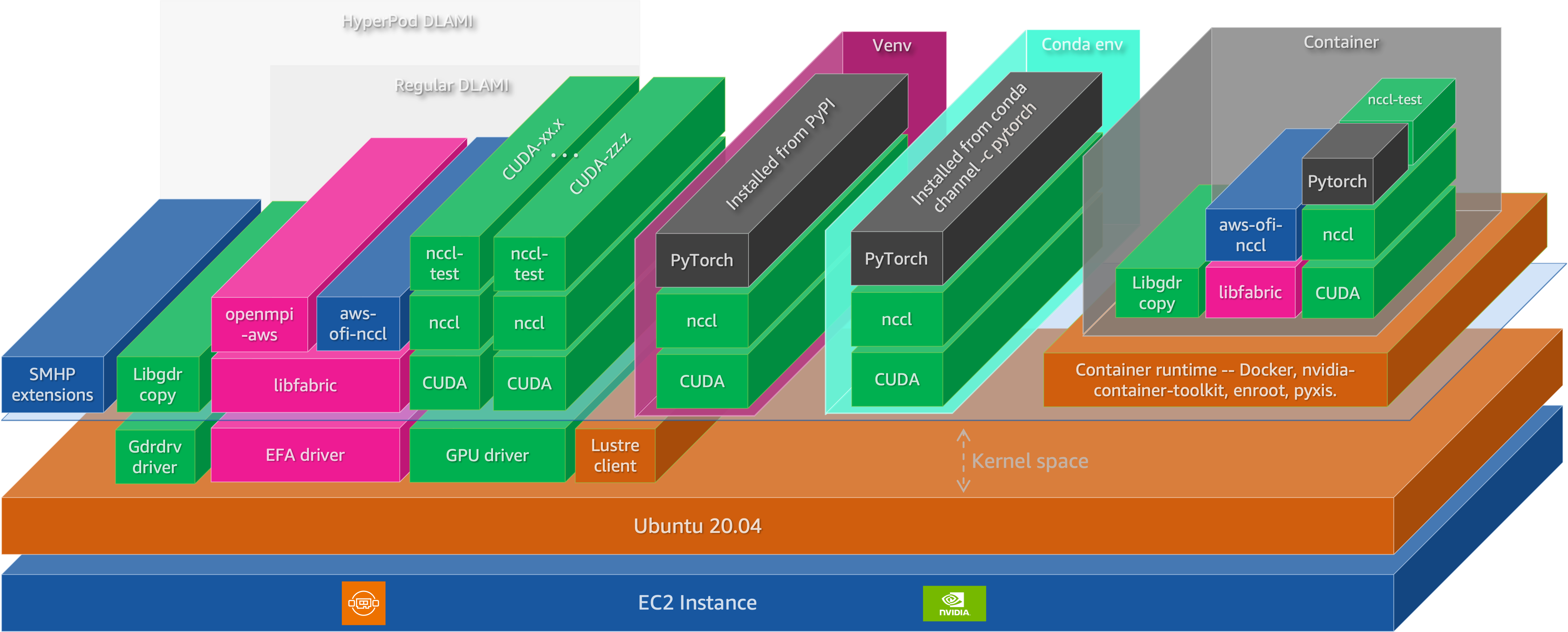
파운데이션 모델의 성능 향상이 사전 학습뿐만 아니라 사후 학습과 테스트 시간 컴퓨팅(Test-time compute)으로 확장됨에 따라, 이를 뒷받침할 통합 인프라의 중요성이 커지고 있습니다. 본 아키텍처는 가속 컴퓨팅, 고대역폭 네트워크, 분산 스토리지로 구성된 하드웨어 계층 위에 Slurm 및 Kubernetes 기반의 리소스 오케스트레이션 계층을 결합합니다. 그 위에서 PyTorch, NCCL, vLLM 등 오픈소스 ML 소프트웨어 스택이 작동하며, Prometheus와 Grafana를 통한 관측성 계층이 전체 시스템의 건전성을 모니터링합니다. 특히 NVIDIA Blackwell B200 기반 P6 인스턴스와 EFAv4 통신 기술은 대규모 분산 환경에서 발생하는 병목 현상을 해결하고 모델 수명 주기 전반의 효율성을 극대화합니다.
배경
분산 학습 기법 (DDP, FSDP, 3D Parallelism)에 대한 기본 이해, AWS EC2 인스턴스 및 네트워킹(VPC, EFA) 기초 지식, Docker 및 Kubernetes/Slurm 오케스트레이션 개념
대상 독자
AWS 인프라에서 대규모 파운데이션 모델을 학습하거나 고성능 추론 시스템을 구축하려는 ML 엔지니어 및 아키텍트
의미 / 영향
이 아키텍처는 모델 성능 향상의 축이 다변화되는 트렌드에 맞춰 하드웨어와 소프트웨어 스택을 통합적으로 설계하는 표준을 제시합니다. 특히 Blackwell 아키텍처와 개선된 EFA 통신 기술의 결합은 추론 비용 절감과 학습 시간 단축을 동시에 달성하여 기업들의 생성형 AI 도입 속도를 가속화할 것입니다.
섹션별 상세
실무 Takeaway
- 대규모 MoE 모델 학습 시 NVLink 도메인이 큰 UltraServer(최대 72 GPU)를 활용하면 all-to-all 통신 병목을 줄여 학습 속도를 높일 수 있다.
- Kubernetes 환경에서 분산 학습을 수행할 때는 Kueue와 Karpenter를 결합하여 작업 단위의 원자적 할당과 적시 노드 프로비저닝을 구현해야 한다.
- 학습 효율을 높이기 위해 단순 GPU 사용률 대신 DCGM_FI_PROF_SM_ACTIVE 지표를 모니터링하여 실제 연산 자원이 얼마나 유효하게 사용되는지 파악해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.