TL;DR
LLM의 다단계 추론 능력을 고도화된 수학 문제로 평가하는 벤치마크가 필요하다. SOOHAK는 연구-수준 수학 지식과 창의적 추론을 요구하는 문제를 expert-저작으로 구성하고, contamination 위험을 줄이는 이원 구성을 통해 frontier 모델의 실전적 한계를 정밀하게 측정한다. 또한 ill-posed 문제에 대한 거절(Refusal) 능력을 평가하는 새로운 축을 제시한다.
왜 중요한가
LLM의 다단계 추론 능력을 고도화된 수학 문제로 평가하는 벤치마크가 필요하다. SOOHAK는 연구-수준 수학 지식과 창의적 추론을 요구하는 문제를 expert-저작으로 구성하고, contamination 위험을 줄이는 이원 구성을 통해 frontier 모델의 실전적 한계를 정밀하게 측정한다. 또한 ill-posed 문제에 대한 거절(Refusal) 능력을 평가하는 새로운 축을 제시한다.
핵심 기여
연구-수준 수학 벤치마크의 신규 구성
SOOHAK는 Challenge(340항목) + Refusal(99항목)으로 구성되며, 64명의 수학자가 직접 저작하고 11개 분야로 분류된다. 702문항의 SOOHAK-Mini도 함께 제공되어 다양한 난이도를 포괄한다.
Refusal 하위집합 도입
ill-posed/모순된 문제를 포함하는 Refusal 항목을 도입하여, 모델이 잘 정의되지 않은 문제에 대해 진단적 거절을 할 수 있는지 평가한다.
SOOHAK-Mini 및 오픈-웨이트 모델 트래킹
SOOHAK-Mini를 통해 오픈-웨이트 모델의 성능 추적이 가능하며, Challenge와 Refusal의 구분으로 모델의 차별화된 능력을 분석한다.
인간 Baseline 및 MSC 하위필드 분석
다섯 팀의 인간 벤치마크를 통해 합치된 커버리지, MSC(수학 주제 분류) 하위필드별 차이, 컨테스트형 사고와 연구형 사고의 차이를 분석한다.
번역 파이프라인 및 번들된 데이터 관리
영문-한국어 이중 언어 벤치마크로, LaTeX 보존 등의 번역 파이프라인과 품질 보증을 통해 다국어 확장을 실현한다.
핵심 아이디어 이해하기
출발점: Frontier 모델의 수학 추론 능력은 contest-style 문제를 넘어 연구 수준의 문제로 확장되며, 데이터 누출(contamination) 문제와 평가 공정의 투명성 요건이 커졌다. 기존 벤치마크는 공개 소스의 overlap와 데이터 누출에 취약해 왔다. 이 논문은 두 가지 축으로 벤치마크를 구성한다: Challenge(graduate 수준 및 연구 인접)와 Refusal(ill-posed 문제에 대한 진단 거절).
방법론
해결 원리의 기초: 다양한 난이도와 도메인을 포괄하는 문제를 expert 저작으로 구성하고, 오염을 줄이기 위해 다중 단계 품질 관리와 이원화된 평가 파이프라인을 활용한다.
주요 결과
주요 수치: SOOHAK-Mini에서 GPT-5가 Avg@3 72.22%로 최고치를 기록했고, Gemini-3-Pro가 71.70%로 뒤를 이었다. Challenge에서 Gemini-3-Pro가 Avg@3 30.39%를 기록했고, Refusal에서 GLM-5가 Avg@3 49.49%로 가장 높은 성능을 보였다. Open-weight 모델은 Challenge에서 성능이 더 낮았다(Kimi-2.5 최상 13.87% Avg@3). Refusal는 모델의 신중성/정확성의 차이가 크게 드러난 축이다.
관련 Figure
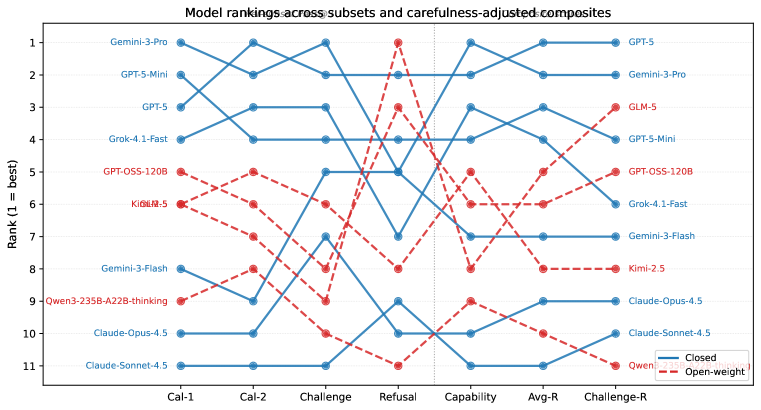
Figure 4는 per-subset Pass@3 및 세 가지 합성 점수의 모델 순위를 시각화한다. MINI에서 GPT-5 계열이 상위권에 위치하고, Challenge에서 Gemini-3-Pro가 선두를 차지하며, Refusal에서 GLM-5의 성능이 돋보인다. 오픈-웨이트 모델은 Challenge에서 상대적으로 열세를 보인다.
Figure: Model rankings across subsets and carefullness-adjusted composites
기술 상세
아키텍처/파이프라인: 다섯 단계의 파이프라인(1) Individual Submission Phase, Consent, (2) Automated LLM-based Checks, (3) Results Returned to Creator & Opt-in Feedback Review, (4) Final Submission Pool, (5) 검증된 데이터셋으로 확정. Gate 1은 Qwen3-7B류, Gate 2는 mid-size 모델, Gate 3은 대형 오픈 모델의 실패를 요구한다. Challenge는 3단계 게이트의 최상위에 해당하고 Refusal는 ill-posed 문제를 다룬다.
한계점
데이터 수집은 4개월의 단축 일정과 대규모 자금 투입으로 운영되었고, 항목의 난이도 라벨은 노이즈가 있을 수 있다. 전제적으로 고유 정답(정수)을 중심으로 평가하는 설계 특성상 증명/구성/정답의 다변형을 완전히 포괄하기 어렵다. 또한 벤치마크의 공개/비공개 발행 정책은 재현성에 영향을 미친다.
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.