TL;DR
메시 기반 그래프가 필요한 기존 시뮬레이터와 달리, 점 구 representation에서의 다중 객체 상호작용을 학습하는 것은 계산 비용과 확장성에서 큰 도전이다. RigidFormer는 object-centric Transformer로 객체 간 상호작용을 중심으로 모델링하고, Anchor-Vertex Pooling 및 ARoPE를 통해 기하 정보를 주입하여 서로 다른 점 해상도와 객체 수에서도 일반화와 속도 모두를 개선한다. 또한 3D rigid-효과를 유지하기 위한 differentiable Kabsch 정합을 도입해 장기간 롤아웃의 안정성을 높인다.
왜 중요한가
메시 기반 그래프가 필요한 기존 시뮬레이터와 달리, 점 구 representation에서의 다중 객체 상호작용을 학습하는 것은 계산 비용과 확장성에서 큰 도전이다. RigidFormer는 object-centric Transformer로 객체 간 상호작용을 중심으로 모델링하고, Anchor-Vertex Pooling 및 ARoPE를 통해 기하 정보를 주입하여 서로 다른 점 해상도와 객체 수에서도 일반화와 속도 모두를 개선한다. 또한 3D rigid-효과를 유지하기 위한 differentiable Kabsch 정합을 도입해 장기간 롤아웃의 안정성을 높인다.
핵심 기여
Mesh-free multi-object rigid-body dynamics를 위한 효율적 학습기
점 입력으로 다중 객체의 강체 역학을 학습하는 객체 중심 Transformer를 제안하고, 시간 스텝 크기(delta t) 조절을 통해 롤아웃 품질을 조절한다.
Anchor-based RoPE로 기하 인식 어텐션 도입
개체 토큰에 대해 Anchor를 중심으로 한 Rotatory Positional Embedding을 적용하고, anchor-ordering 불변성과 객체-토큰 순서를 보존하는 메커니즘을 제시한다.
Anchor-Vertex Pooling으로 로컬 접촉 기하 주입
앵커 주변의 로컬 Vertex 특징을 AVP로 모아 앵커 쿼리에 연결해 접촉 상황의 정밀한 기하 정보를 효과적으로 전달한다.
differentiable Kabsch 정합으로 강체 제약 강화
예측된 앵커를 Kabsch 정합으로 정렬하고, 전체 점 집합에 이를 적용해 intra-object 거리를 보존하는 강체 제약을 학습 신호로 활용한다.
Step-size 조건화로 장기 롤아웃과 계산 효율의 균형
∆t를 조건화하는 FiLM 모듈로 학습 중 다양한 연산 간격을 다루고, 한 모델로 가성비 있게 짧은/긴 시간 해상도를 모두 지원한다.
200+ 객체 확장 및 부분 점 구 입력 처리
200개가 넘는 객체와 부분 관측의 경우에도 일반화와 안정성을 유지하며, 파트-컨트롤러 확장을 통한 관절-구성 가능성을 시연한다.
핵심 아이디어 이해하기
출발점: 점 구 representation에서 다중 객체 간의 상호작용은 전통적 메시지 전달 그래프에 의존하면 비효율적이다. 해결 원리: 객체 수준 토큰을 사용하고, 각 객체의 상태 업데이트를 작은 앵커 집합으로 근사한다. Anchor-based RoPE로 기하 정보를 주의에 주입하고, Anchor-Vertex Pooling으로 접촉 로컬 정보를 확보한다. 마지막으로 Verlet-앵커 업데이트를 통해 예측을 구속하고, differentiable Kabsch 정합으로 강체 제약을 강제한다. 달라지는 점: step-size conditioning으로 다양한 시간 척도에서의 롤아웃을 한 모델로 다룬다. 이로써 mesh-free 입력에서도 긴 시계열에서의 안정성과 확장성이 확보된다.
방법론
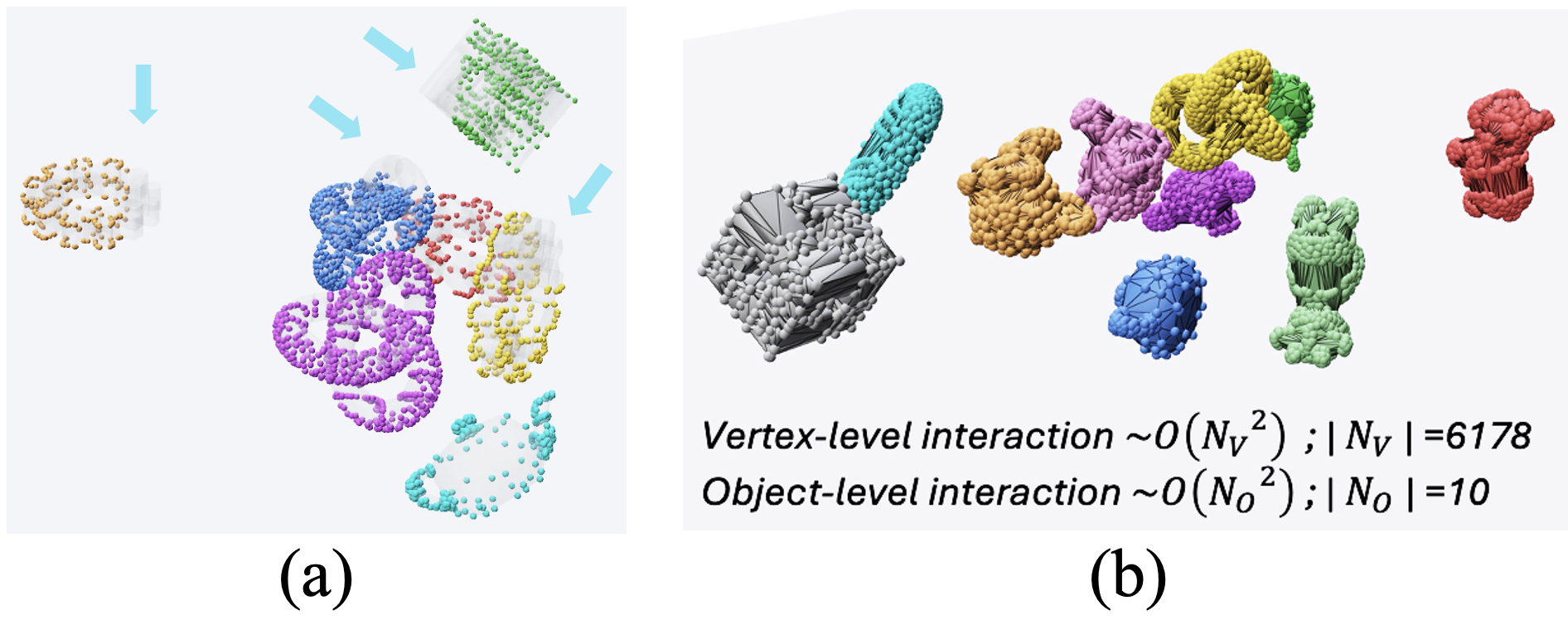
입력: 각 객체의 포인트 클라우드 x(i)t, 시간 간격 Δt, 물리 파라미터 ϕ(i)=(m, μ, ε). → Encθ를 통해 각 객체의 고정 차원 임베딩 o(i)t를 얻고, 객체 임베딩 Ot를 구성한다. → Decoder는 L개의 Transformer 블록으로 객체 토큰의 상호작용을 처리하고, FiLM 코드를 통해 Δt를 시점별로 조건화한다. → 앵커 쿼리 Qt를 cross-attention으로 객체 토큰에-attend시키고, 각 앵커(k)에서 가속도 a(i,k)t를 예측한다. AVP 모듈은 앵커 주변의 로컬 점 특징을 집계해 앵커 쿼리에 보강한다. → Verlet에 의해 qˆ(i,k)t+1을 얻고, Kabsch 정합으로 x(i,v)t+1를 구한다. 이렇게 얻은 R(i), t(i)로 전체 점 집합을 업데이트한다. ARoPE를 통해 쿼리/키의 위치 정보를 보정하고, 비대칭적 객체 수 변화에 대한 일반화를 달성한다.
관련 Figure
입력에서 객체 토큰화, 객체 간 상호작용, 앵커 기반 상태 진전, ARoPE 및 Kabsch 정합의 흐름을 한 눈에 보여준다.
RigidFormer의 파이프라인 개요 다이어그램
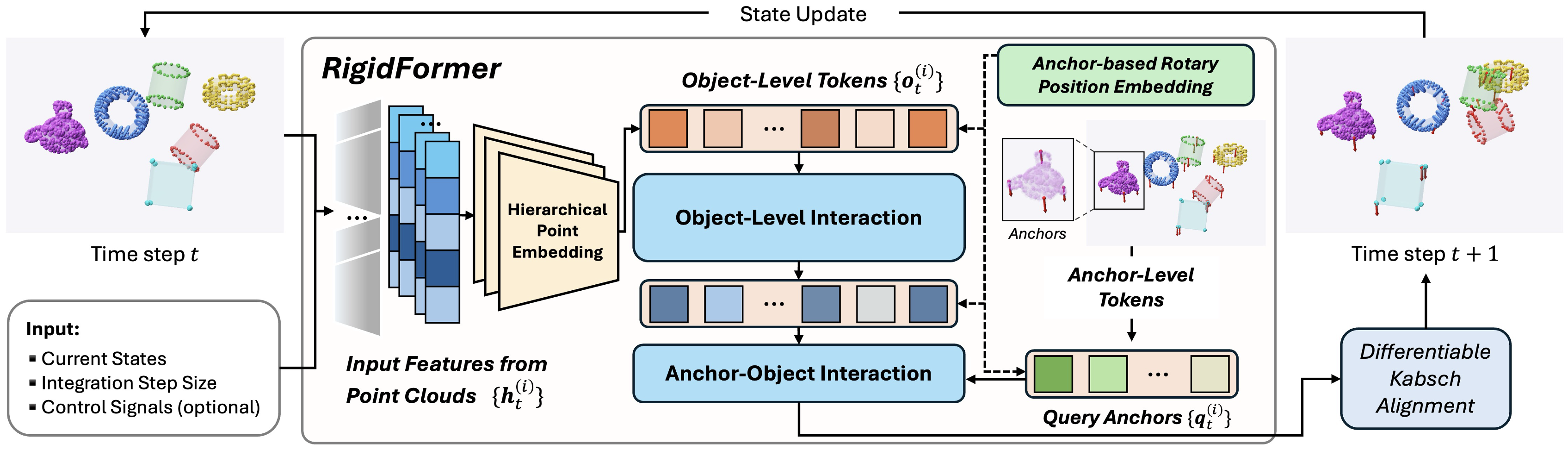
객체-레벨 토큰과 앵커 기반 상호작용, ARoPE, Anchor-Vertex Pooling이 어떻게 연결되는지 보여준다.
RigidFormer 파이프라인 상세 구성
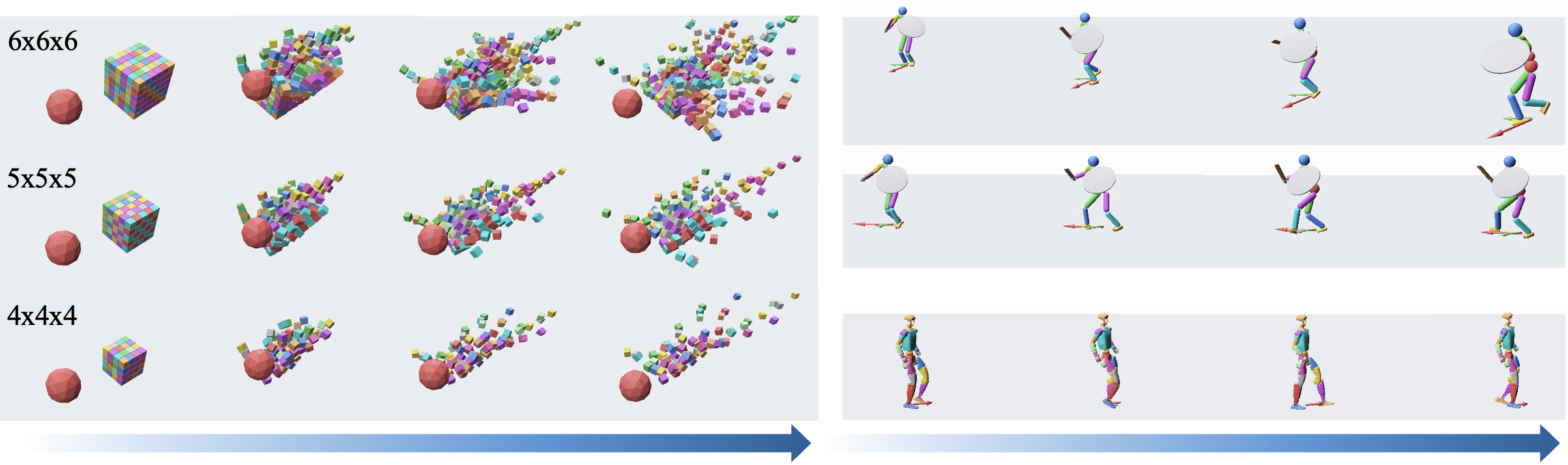
인체/로봇 관절이 방향 제어에 따라 일관된 전체 운동을 따라가는지 보인다.
Controllable articulated body 시뮬레이션 예시
주요 결과
주요 벤치마크에서 Mesh-based 시뮬레이터 대비 우수한 성능을 보인다. MOVi-B에서 100 프레임 시점에 HopNet 대비 0.176 m/17.91°에서 0.161 m/15.33°로 향상된다. SDF-Sim은 0.160 m/18.03°를 기록하였고, RigidFormer는 0.050 m/3.97° (step=1) 및 0.029 m/1.51° (step=10)로 개선한다. Cross-dataset 전이에서 MOVi-Sphere/ MOVi-A로 학습 시 더 나은 일반화가 나타난다(예: step=5/10에서 Translation보다 Orientation 일반화가 더 안정적). MOVi-B에서 학습한 경우도 step-size 1에서 Translation이 더 민감하나 orientation은 robust하게 전이된다. 또한 MOVi-B에서 25% 포인트 손실이 있는 Partial Point Cloud에서도 안정적으로 롤아웃이 가능하다. 런타임 측면에서 모델 코어는 18.61 ms/스텝, 전체 파이프라인은 41.86 ms/스텝으로 23.9 FPS를 달성한다. 파라미터 수는 174.8M이며 메모리 피크는 1.80 GB이다.
관련 Figure
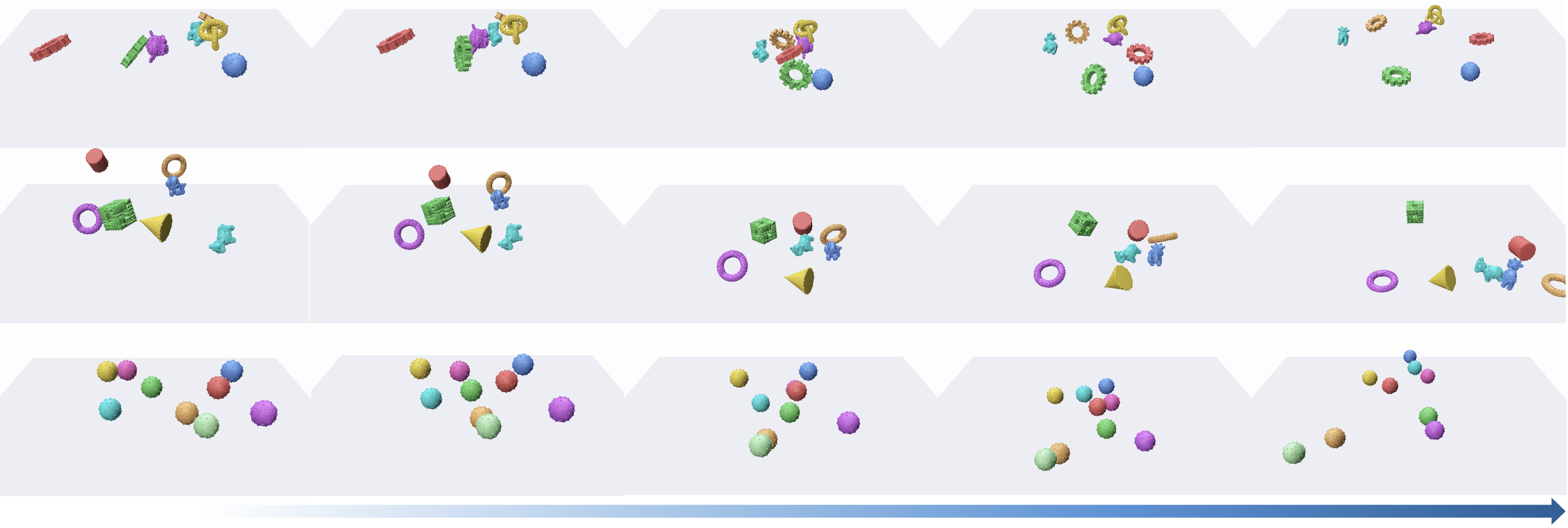
실험 결과 및 시각화가 방법론의 효과를 뚜렷하게 시사한다.
주요 시각화 결과 및 상태 업데이트 흐름

부분 점 구 입력에서도 안정적인 inter-object 접촉을 유지하는 모습을 보여준다.
Partial point cloud에서의 Rollout 안정성

부분 입력에서도 앵커-기반 접근이 견고함을 시각적으로 제시한다.
Partially 가시화된 점 구 입력에서의 성능
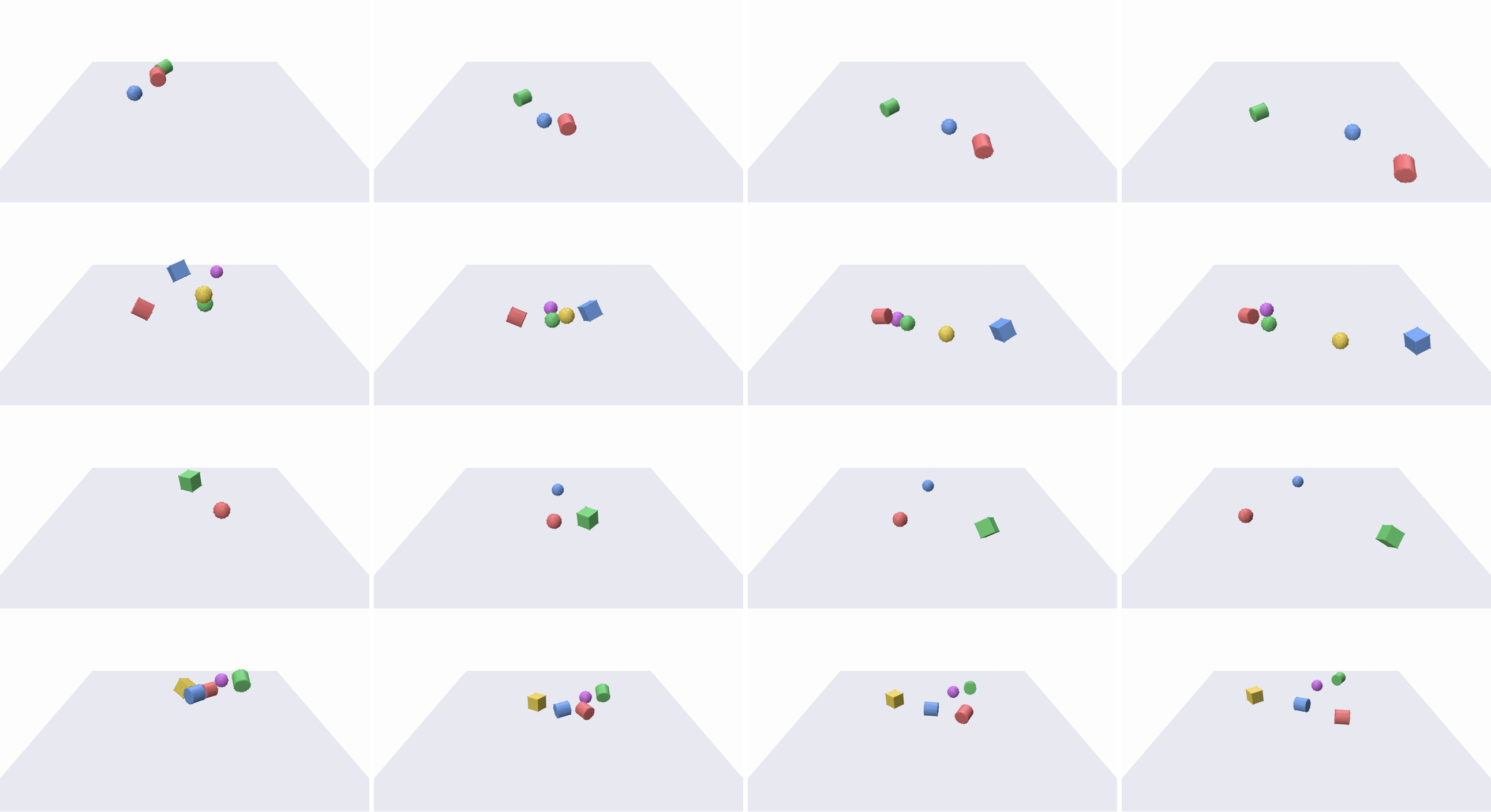
다양한 기하학적 형태에 대한 RolOut 품질과 질적 개선을 시각화한다.
MOVi-A 데이터셋에서의 결과 예시
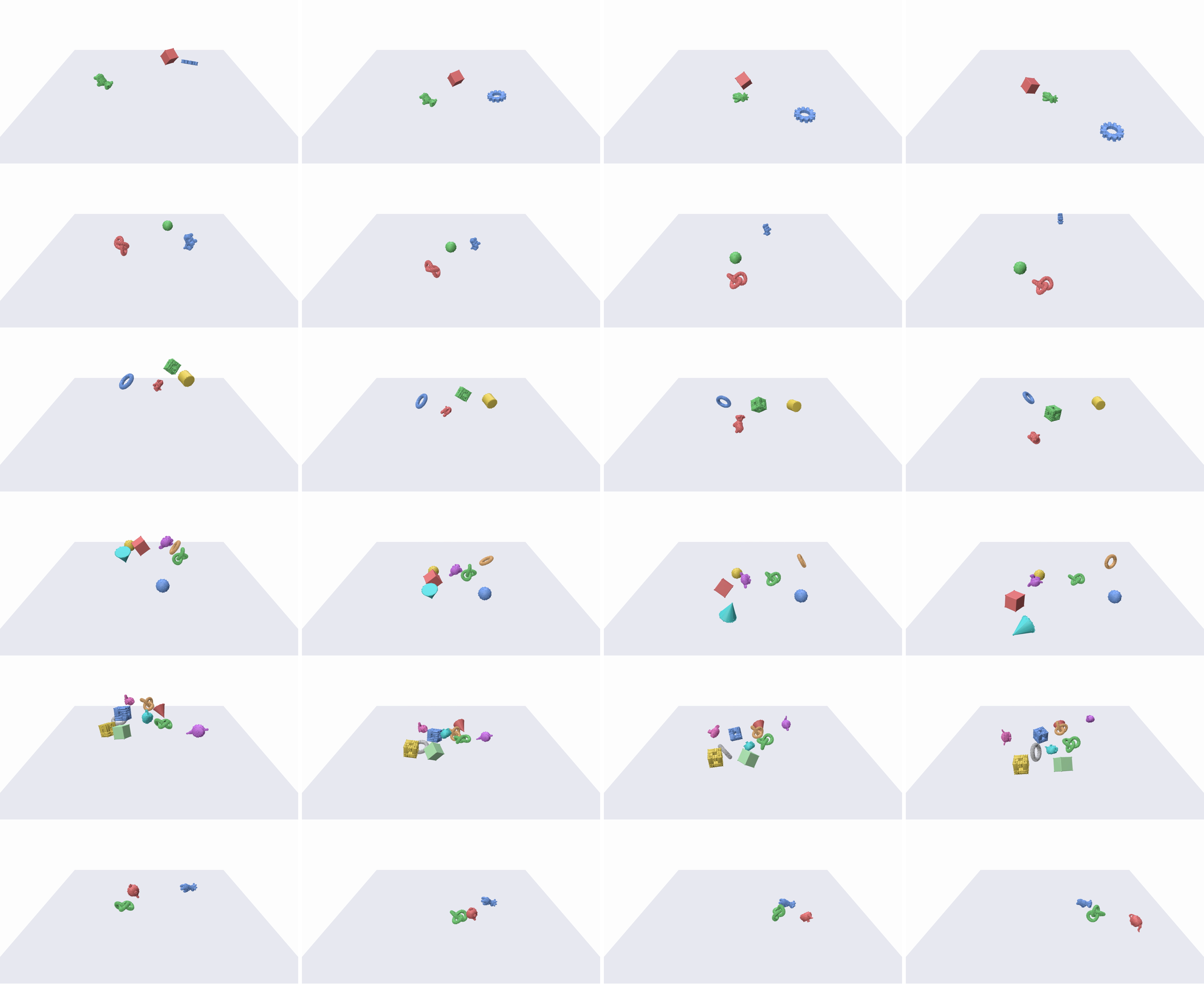
다양한 객체 수와 형상 변화에서의 성능을 시각적으로 보여준다.
MOVi-B 데이터셋에서의 결과 예시
기술 상세
단락 1 — 전체 아키텍처: Hierarchical PointNet 기반 입력 인코더가 N(i)v×12 차원의 per-vertex 피처를 고정 차원 임베딩 o(i)t로 축약하고, M개의 오브젝트 토큰 Ot를 구성한다. Decoder는 L층 Transformer로 각 오브젝트 토큰의 상호작용을 모델링하며, Nr=16의 등록 토큰을 사용해 글로벌 워크스페이스를 형성한다. Anchor predictor는 Na=4의 앵커를 각 오브젝트에서 가져와 cross-attention을 통해 상호작용 맥락을 수집하고 가속도를 예측한다. ARoPE는 3D rotary anchor map으로 각 앵커 좌표를 표현하고, 전체 앵커 Descriptor를 평균 결합해 쿼리/키에 적용한다. 단락 2 — 핵심 메커니즘: AVP는 각 앵커에 대해 x(i,v)t와 q(i,k)t 간의 거리에 의해 가중치를 두고 주변 Vertex 피처를 평균화한다. q(i,k)t에 AVP 출력을 결합해 acceleration a(i,k)t를 예측한 뒤 Verlet integration으로 예측 위치를 얻고, Kabsch alignment를 통해 qˆ(i,k)t+1을 기준으로 R(i), t(i)을 구한 뒤 x(i,v)t+1을 x(i,v)ref에 의해 업데이트한다. 로컬 기하 정보를 보전하기 위해 RoMa를 사용한 differentiable Kabsch를 적용한다. 단락 3 — 차별화 포인트: Mesh-based 접근 대신 object-level 토큰과 앵커를 활용해 상호작용을 효율적으로 학습한다. step-size FiLM(Gating 포함)으로 Δt에 따른 학습 안정성과 롤아웃 품질을 조정하고, Anchored RoPE로 객체 수 변화에 강건하게 일반화한다. 단락 4 — 학습 및 구현 세부: sequence 길이 T=8, Δt ∈ {1,5,10}를 샘플링한 상태에서 AdamW으로 300에폭 학습한다. 손실은 위치/가속도에 대해 raw와 rigid 두 용어를 가진 Smooth L1 손실의 합으로 구성되며, rigid projection 후의 손실도 함께 최적화한다. Multi-scale Cross-attention은 4개의 스케일(Zℓ)의 앵커를 읽고, 각 스케일에서 독립적인 cross-attention 모듈을 거친 뒤 연결한다.
한계점
한계점은 명시적으로 object label이 필요하다는 점이다. 부분 가시성 상태에서 개체의 형상을 충분히 포착하지 못하면 예측이 어려워질 수 있다. 실제 센서 노이즈, 온라인 객체 세분화, 혼합 강체–변형 가능 시나리오 등은 확장 연구가 필요하다. 또한 접촉은 데이터로 학습되며, 명시적 보완/제약 기반 물리 엔진과의 하이브리드는 향후 성능 개선 방향이다.
실무 활용
mesh-free 포인트 입력에서 다중 객체의 rigid-body dynamics를 학습한 모델로, 로봇 시뮬레이션, 가상 프로덕션의 롤아웃 예측 및 계획에 활용 가능하다.
- 로봇 조작 계획에서 다양한 객체 간 충돌 시나리오 예측
- 합성 데이터에서의 빠른 물리 시뮬레이션으로 학습 데이터 확장
- 부분 점 구 입력에서의 실시간 시뮬레이션 및 인터랙티브 시각화
- 관절 제어가 필요한 의사결정 시스템에서의 프리플렌닝
- 자연스러운 물리적 상호작용이 필요한 그래픽/가상현실 시나리오
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.