TL;DR
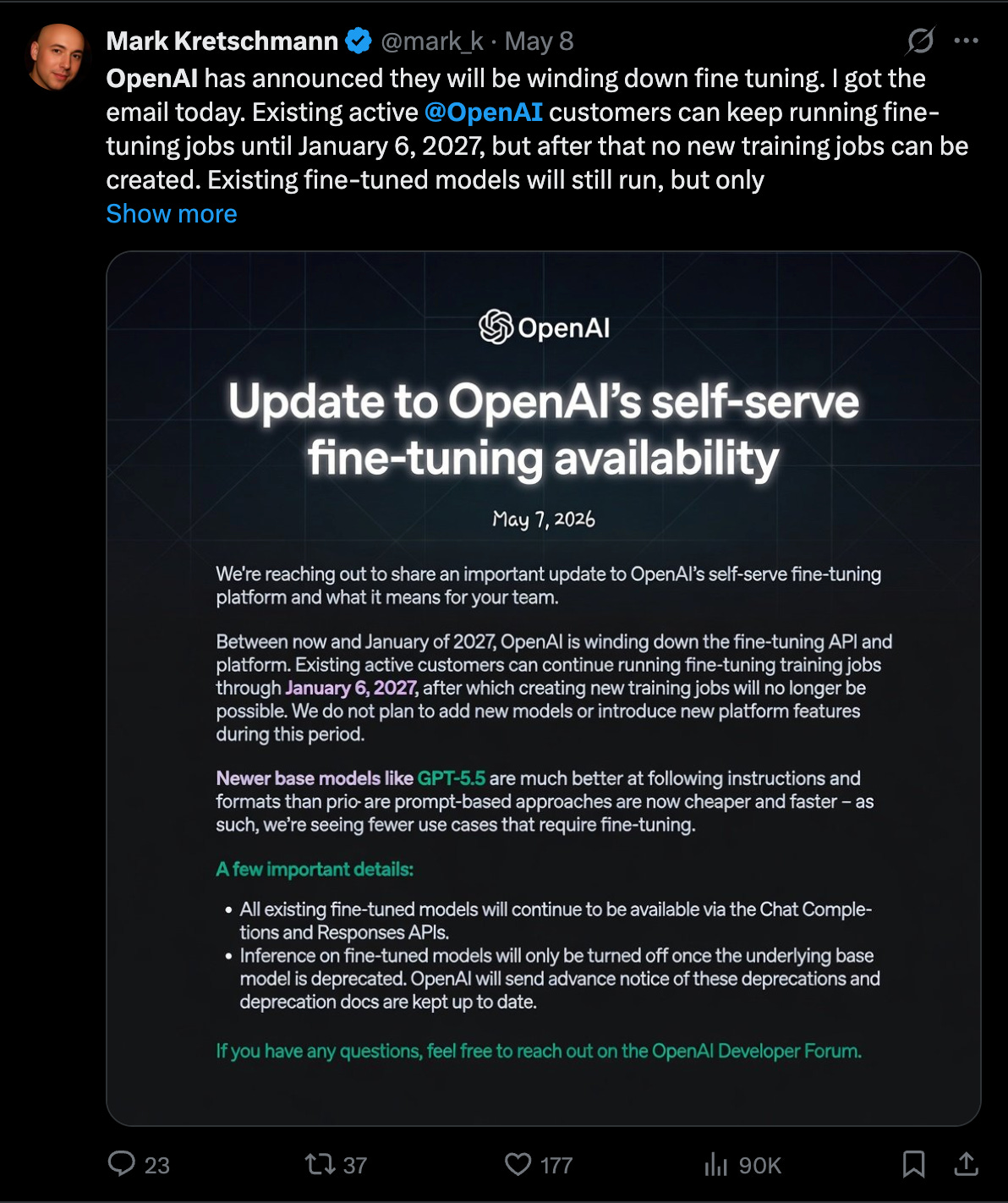
OpenAI가 자사의 셀프 서비스 파인튜닝 플랫폼과 API를 2027년 1월 6일부로 종료한다고 발표했습니다. GPT-5.5와 같은 최신 베이스 모델들이 지시 이행 능력이 뛰어나고 프롬프트 기반 접근법이 더 저렴하고 빨라지면서 파인튜닝의 필요성이 감소했기 때문입니다. 업계에서는 이를 '2026년 사이드 퀘스트 학살'의 일환으로 보며, 대신 에이전트 시스템, 추론 최적화, 그리고 Blackwell 기반의 대규모 MoE 서빙 인프라로 관심이 옮겨가고 있습니다. 특히 Perplexity는 GB200 시스템을 통해 대규모 MoE 모델의 추론 성능을 획기적으로 개선하며 새로운 인프라 표준을 제시하고 있습니다.
배경
LLM Fine-tuning 및 Prompt Engineering 기본 개념, MoE(Mixture of Experts) 아키텍처 이해, GPU 인프라 및 추론 최적화 기초 지식
대상 독자
LLM 인프라 엔지니어, AI 에이전트 개발자, 로컬 모델 최적화에 관심 있는 연구자
의미 / 영향
파인튜닝의 시대가 저물고 프롬프트 기반의 고성능 베이스 모델 활용과 정교한 에이전트 오케스트레이션이 주류가 될 것입니다. 하드웨어 측면에서는 Blackwell과 같은 고대역폭 인프라가 대규모 MoE 모델의 실시간 서빙 가능 여부를 결정짓는 핵심 요소가 될 전망입니다.
섹션별 상세
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.