TL;DR
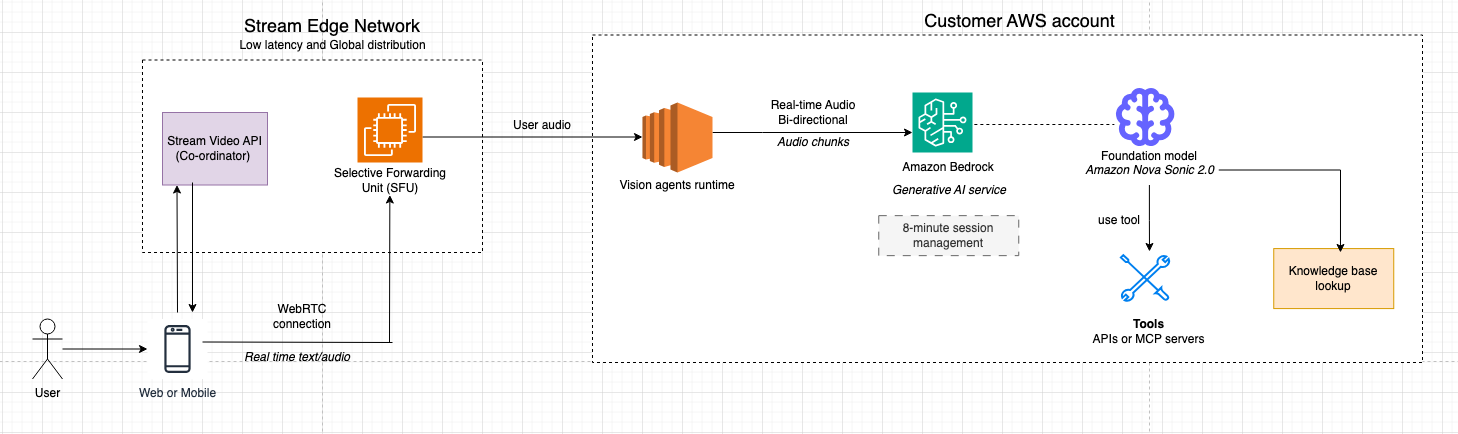
실시간 음성 에이전트 구축은 오디오 스트리밍, 모델 오케스트레이션, 연결 관리 등 복잡한 인프라 문제를 동반한다. Stream의 Vision Agents 프레임워크는 WebRTC 연결과 오디오 처리를 추상화하고, Amazon Nova 2 Sonic은 실시간 음성-음성(S2S) 변환과 함수 호출을 처리한다. 이 시스템은 Stream의 글로벌 엣지 네트워크를 통해 500ms 미만의 지연 시간을 제공하며, 복잡한 인프라 구현 없이도 프로덕션 수준의 음성 AI를 구현한다. 실제 구현 시 Python 기반의 Vision Agents 플러그인을 사용하여 최소한의 코드로 에이전트를 배포하고 외부 API와 연동할 수 있다.
배경
Python 3.12 이상, AWS 계정 및 자격 증명, Stream 계정 및 API 키, uv 패키지 관리자
대상 독자
실시간 음성 AI 에이전트를 프로덕션 환경에 구축하려는 개발자
의미 / 영향
이 아키텍처는 복잡한 음성 인프라를 추상화하여 소규모 팀도 고성능 음성 에이전트를 빠르게 배포할 수 있게 한다. 특히 S2S 모델과 함수 호출의 결합은 음성 인터페이스를 단순한 챗봇에서 실질적인 업무 자동화 도구로 진화시킨다.
섹션별 상세
async def create_agent(**kwargs) -> Agent:
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Helpful Assistant", id="agent"),
instructions="You are a helpful voice assistant. Be concise and friendly.",
llm=aws.Realtime(
model="amazon.nova-2-sonic-v1:0",
region_name="us-east-1",
voice_id="matthew",
),
)
return agentVision Agents와 Amazon Nova 2 Sonic을 사용하여 음성 에이전트를 초기화하는 코드
@agent.llm.register_function(
name="get_weather",
description="Get the current weather for a given city"
)
async def get_weather(location: str) -> Dict[str, Any]:
# In production, call a real weather API
return {
"city": location,
"temperature": 72,
"condition": "Sunny",
"humidity": "45%"
}에이전트가 외부 API를 호출할 수 있도록 함수를 등록하는 예시
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.