TL;DR
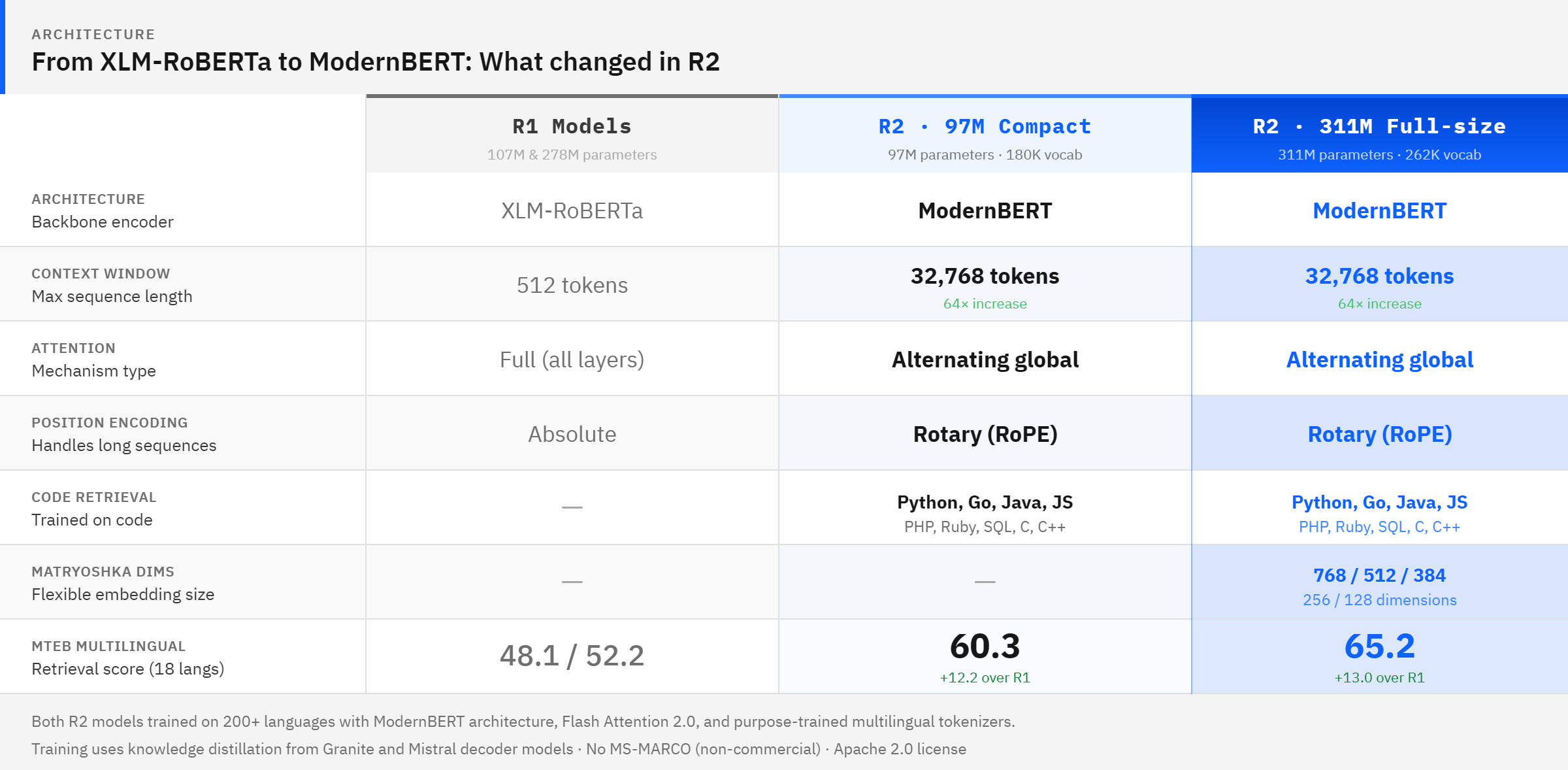
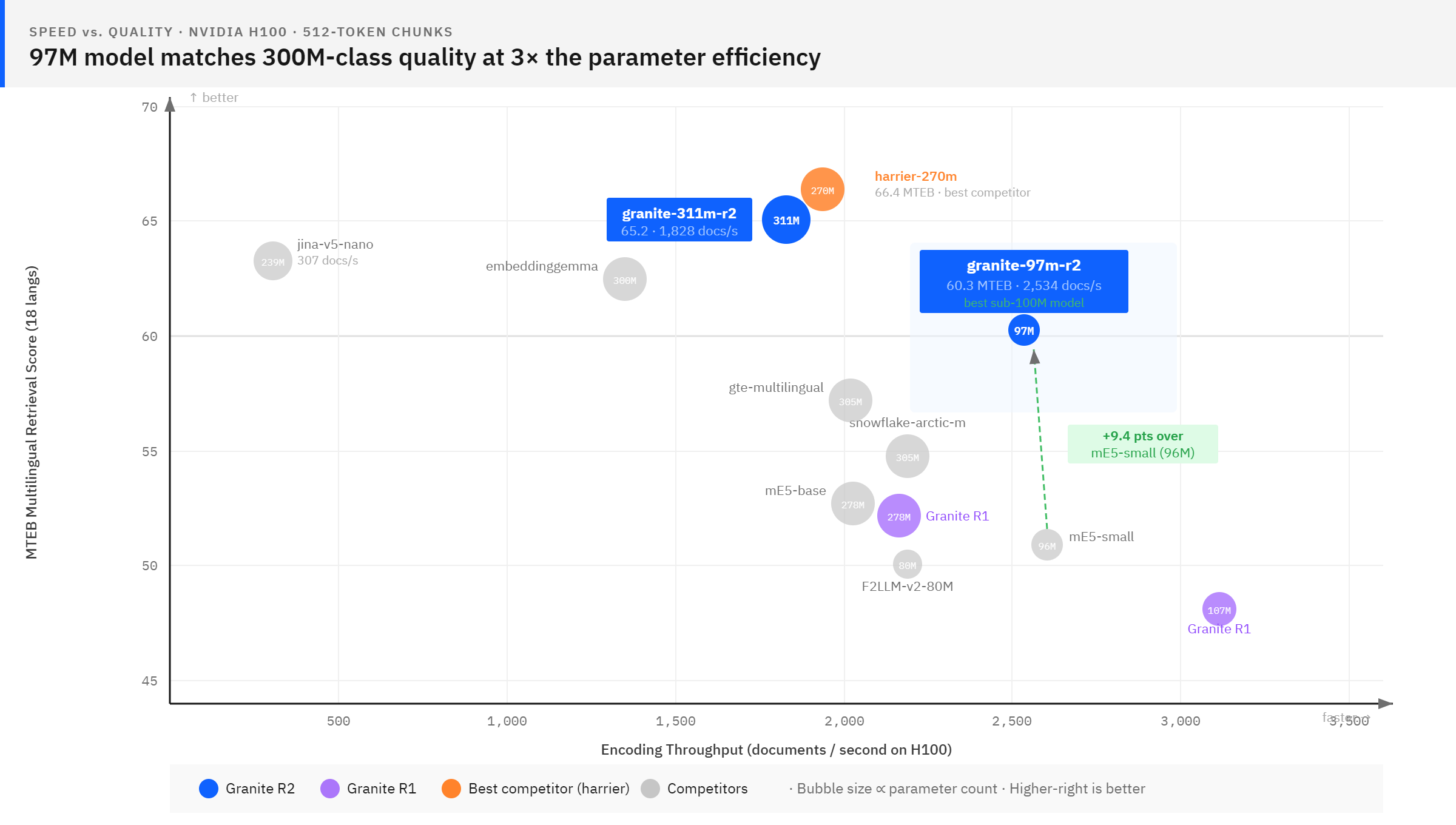
IBM Granite Embedding Multilingual R2는 97M과 311M 파라미터 규모의 두 가지 다국어 임베딩 모델로 구성된다. ModernBERT 아키텍처를 기반으로 200개 이상의 언어와 32K 토큰의 긴 컨텍스트를 지원하며, 기존 R1 대비 MTEB 벤치마크에서 큰 폭의 성능 향상을 보였다. 97M 모델은 100M 미만 파라미터 모델 중 최고 수준의 검색 품질을 기록했고, 311M 모델은 Matryoshka 임베딩을 지원하여 효율적인 차원 축소가 가능하다. 두 모델 모두 Apache 2.0 라이선스로 배포되며, LangChain, LlamaIndex 등 주요 프레임워크와 즉시 호환된다.
배경
Python, Sentence Transformers, RAG 시스템에 대한 기본 이해
대상 독자
다국어 RAG 시스템을 구축하거나 임베딩 모델의 비용 효율성을 최적화하려는 AI 엔지니어
의미 / 영향
이 모델들은 고성능 다국어 임베딩을 Apache 2.0으로 공개하여 기업의 RAG 파이프라인 구축 장벽을 낮춘다. 특히 97M 모델의 효율성은 모바일이나 엣지 환경에서도 고품질 검색 기능을 구현할 수 있는 가능성을 제시한다.
섹션별 상세

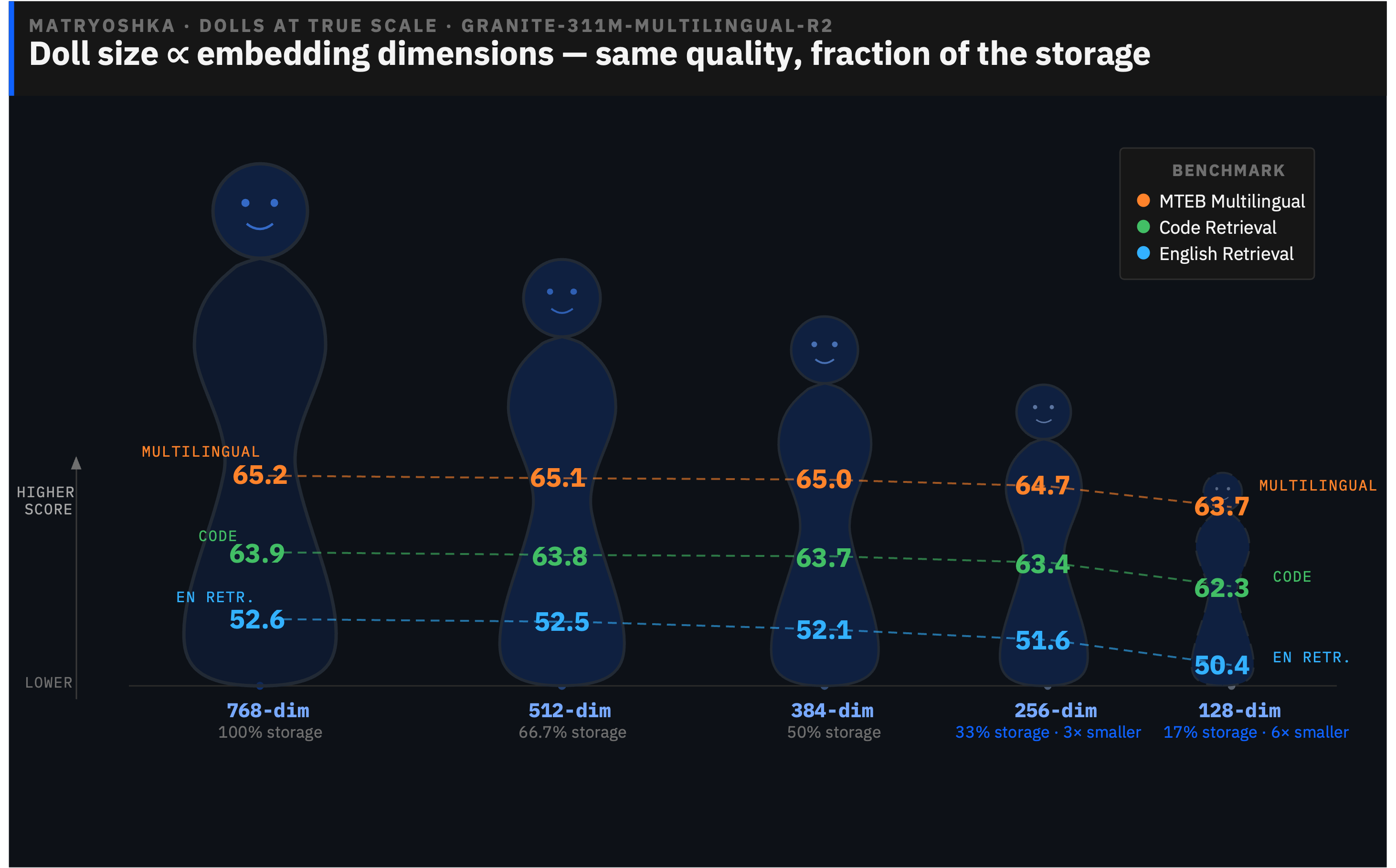
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("ibm-granite/granite-embedding-311m-multilingual-r2")
# Full 768-dimensional embeddings
full = model.encode(["example text"])
print(full.shape) # (1, 768)
# Truncated to 384 dimensions
small = model.encode(["example text"], truncate_dim=384)
print(small.shape) # (1, 384)Sentence Transformers를 사용하여 임베딩을 생성하고 Matryoshka 기능을 통해 차원을 축소하는 예시
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.