TL;DR
온-정책 증류(OPD)에서 reward extrapolation 계수 λ를 1보다 크게 설정하면 학생 모델이 교사의 영역을 넘어설 수 있지만, 특정 임계값을 넘기면 출력 계약이 붕괴한다. 본 연구는 단일 위치 Bernoulli 축소를 통해 λ⋆를 닫힌 형태로 도출하고, Fashion 데이터에서 이를 교차 검증함으로써 실전 시스템에서의 안정적 운영 포인트를 제시한다. 이로써 OPD 튜닝이 단순한 λ 스윕이 아닌 예측 가능한 경계 설정 문제로 바뀐다.
왜 중요한가
온-정책 증류(OPD)에서 reward extrapolation 계수 λ를 1보다 크게 설정하면 학생 모델이 교사의 영역을 넘어설 수 있지만, 특정 임계값을 넘기면 출력 계약이 붕괴한다. 본 연구는 단일 위치 Bernoulli 축소를 통해 λ⋆를 닫힌 형태로 도출하고, Fashion 데이터에서 이를 교차 검증함으로써 실전 시스템에서의 안정적 운영 포인트를 제시한다. 이로써 OPD 튜닝이 단순한 λ 스윕이 아닌 예측 가능한 경계 설정 문제로 바뀐다.
핵심 기여
클립-안전 임계 λ⋆의 닫힌 형태 도출
하나의 위치에서 p, b, c로 표현되는 매개변수로부터 base-relative extrapolation 대상 pλ를 클립-안전 구역 qc와의 관계로 정의하고, λ⋆(p,b,c) = log((1−p)/(c−1+p)) − log((1−b)/b) / log((1−p)/p) − log((1−b)/b) 형태의 해를 제시한다. τ와 p의 특성에 따라 이 임계값은 감소/증가하며, λ가 λ⋆를 넘어가면 fixed point가 clip-unsafe 영역으로 벗어난다.
Fashion 데이터에서의 예측 브래킷 및 현장 캘리브레이션
Fashion K=8 바인딩 클래스에서 구조적 위치의 modal 확률 ptyp와 warmstart mass beff를 측정하고, c=5에서 λ⋆safe≈1.18, λ⋆typ≈1.28의 브래킷을 얻었다. 이 브래킷은 실제 cliff 시작 구간 [1.15, 1.25]를 한 λ-grid 단계 내로 포착한다. N=200 예산 확장 및 c=1.5 스윕에서도 클리프-현상이 일관되게 나타났다.
배포 규칙 및 범위 체크
λ⋆ 바로 아래에서 운영하도록 권고하고, ListOPD를 이용해 1.7B 학생 모델이 8B-SFT 베이스라인과 도메인 내 동등성에 도달하는 것을 보인다. 이는 파라미터 수를 줄이고 시스템 효율을 높이면서도 출력 계약의 준수성을 유지하는 방법을 제시한다.
핵심 아이디어 이해하기
출력 계약이 구조화된 태스크에서 형식-적합성과 계약 일치를 필요로 한다. ON-policy rollout에서 교사-학생 간의 확률 비율을 기반으로 한 보상 신호를 λ배로 증폭하면, 특정 임계에서 고정점이 clip-safe 영역에서 벗어나며 형식-붕괴가 발생한다. 이 현상은 구조적 토큰(예: JSON 스켓처)의 modal mass가 집중될 때 더욱 뚜렷하며, 가장 집중된 위치의 고정점 q⋆가 λ⋆에 의해 결정된다. sequence-level로는 Neff 클래스 수가 작고, 한(binding) 클래스가 지배적일 때 예측 가능한 cliff가 나타난다.
관련 Figure
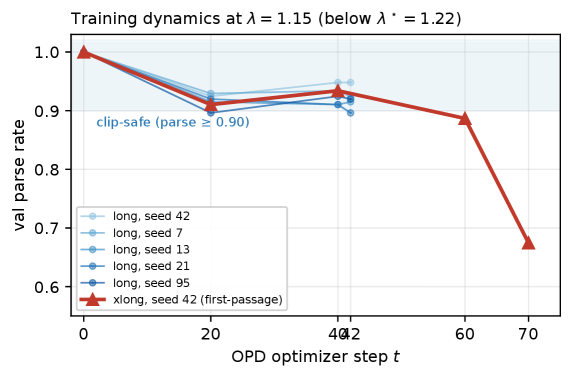
Figure 1은 λ가 임계값에 접근할 때 fixed point의 위치가 clip-safe 영역을 벗어나는 것을 직관적으로 보여주며, λ⋆의 필요성과 근거를 시각적으로 보조한다.
Left 패널은 IS-clip-safe 기하학, Right 패널은 Fashion에서의 parse-rate와 λ의 관계를 보여주는 다이어그램이다.
방법론
- ListOPD를 위한 리스트-와이즈 롤아웃 설정과 per-token IS clipping(c) 적용. ρt = min(c, πT(at|st)/πS(at|st))를 사용하고 L = − Σt ρt A(st,at;λ) log πS(at|st)로 업데이트한다. 2) 단일 Bernoulli reduction에서 λ⋆(p,b,c)를 도출하고, pλ가 qc를 넘으면 cliff가 발생함을 보인다. 3) 다중 토큰 환경으로 확장하여 off-modal 비율 invariance를 가정하고 Thm. C.4를 통해 근사적 정확도를 확보한다. 4) Fashion 데이터에서 λ 스윕과 예산 확장(N=42,70,200)으로 예측 브래킷과 실제 cliff를 비교한다. 5) Cross-arch/다양한 task에서의 범위 체크 및 정량적 검증을 수행한다.
주요 결과
주요 벤치마크는 Fashion(K=8, JSON 리스트형 출력)에서 parse_rate가 λ≈1.22 근방에서 급락하는 cliff를 재현했다. 1.7B-ListOPD는 0.23의 USEFUL에서 0.86으로 상승했으며, 8B-SFT 베이스라인과의 도메인 내 동등성은 동일한 seed-variance 하에서 달성되었다. 예산 확장(N=200)에서 cliff midpoint는 1.06으로 관측되었고, c=1.5 스윕에서 서브-클리프 예측이 유효했다. MS MARCO/TREC-DL 같은 범용 벤치에서도 cliff의 위치가 Fashion와 동일한 예측 브래킷 내부에 들어올 수 있음을 확인했다. 다양한 cross-task/scope 체크에서도 λ⋆가 브래킷 안에 들어오며, 1.7B-ListOPD의 parity를 확인했다.
관련 Figure
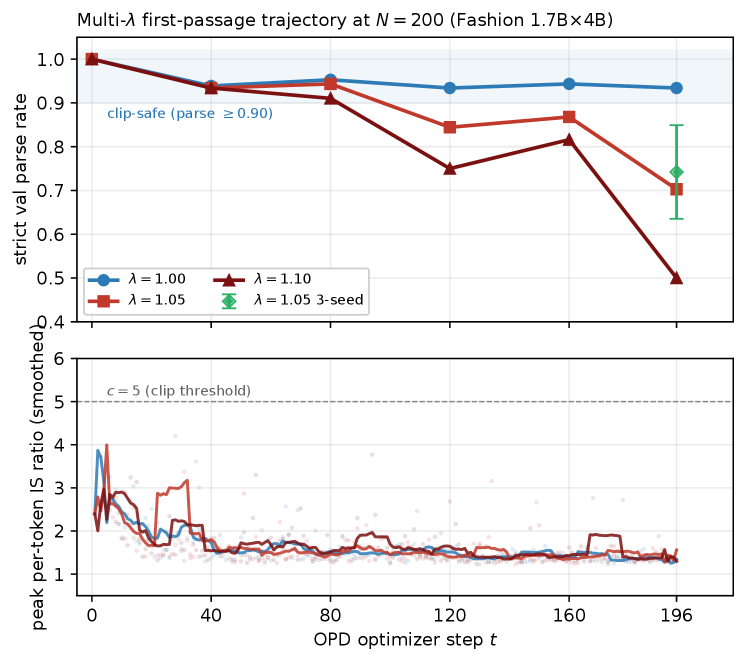
Figure 2는 λ=1.0,1.05,1.10 등의 다중 λ에서의 최초-패스 경로와 IS 비율의 변화를 시각화하여, Clarke boundary를 넘어서는 과정의 시간적 특성과 post-cliff 확산을 보여준다.
Multi-λ first-pass trajectory 및 IS 비율의 최대/최소를 보여주는 차트 형식의 그림이다.
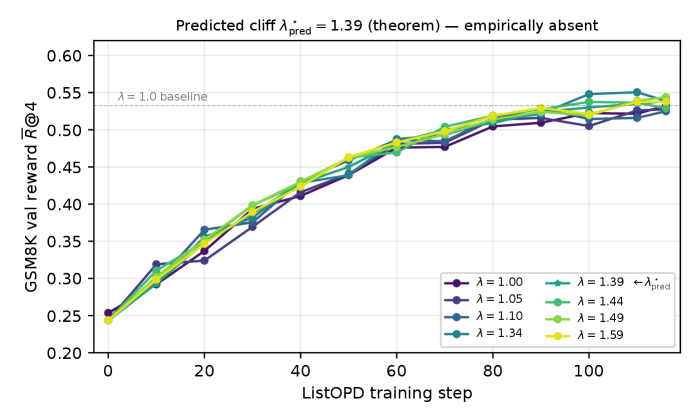
Figure 3은 GSM8K에서의 다중-λ 스윕에 따른 성능 곡선을 보여주며, 예측 클리프 λ_pred=1.39의 실험적 부합 여부를 확인하는 맥락에서 타당성을 제공한다.
GSM8K 문제에 대한 목록형 리스트OPD의 성공 여부를 나타내는 그래프이며 λ_pred=1.39의 예측과 비교한다.
기술 상세
3토큰 Bernoulli 감소와 base-relative extrapolation의 수학적 구조를 도입하고, 싱글-포지션 λ⋆를 도출한다. 다토큰 케이스에서 off-modal-ratio invariance를 가정하면 Thm. C.4가 성립하고, Thm. 4.1의 확장이 성립한다. 예산-의존적 예측인 Thm. 4.2의 Leftward-Drift 진단은 N 증가에 따라 cliff 위치가 좌측으로 이동하는 경향을 보인다. 해당 클리프는 대개 페어-생성의 구조적 등가 클래스를 가진 조합에서 가장 강하게 나타난다. Cross-task 및 cross-architecture 실험에서 peff와 binding mass의 차이가 λ⋆의 민감도에 미치는 영향이 작게 나타난다.
한계점
λ⋆는 near-deterministic scaffolding의 단일 binding 클래스에 대한 운영 규칙이다. inner-schema가 서로 다른 경우(예: JSONSchemaBench의 이질적 inner 스키마) cliff의 anchor가 분산될 수 있어 예측 정확도가 감소한다. 또한 finite-budget에서의 post-clip drift를 정량화하는 것은 남은 문제이며, SFT-parse headroom이 충분히 존재하지 않는 경우 cliff가 관찰되지 않을 수 있다.
실무 활용
ListOPD를 활용하면 작은 규모의 SFT 기반 모델이 대형 모델과 비슷한 도메인 적합성을 달성할 수 있다. 클리프 경계가 예측 가능하므로 운영 포인트를 안정적으로 선택할 수 있다.
- structured-output JSON 생성을 포함하는 LLM 애플리케이션의 품질/일관성 향상
- 다중 토큰 출력의 리스트-랭킹 태스크에서 파라미터 효율성 증가
- 도메인 적응 시, 학습 예산에 맞춘 운영 포인트 조정
- 오프-라인 배포에서의 계약 준수성 향상과 파서 호환성 개선
코드 공개 여부: 미확인
키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.