TL;DR
대학술 연구의 인용은 신뢰성의 핵심이다. LLM이 생성한 인용은 표면적으로 타당해 보이지만 실제 출처와의 검증이 필요하며, 필드 단위의 진단이 없으면 수정이 어렵다. 본 연구는 12-code taxonomy와 CITETRACER 파이프라인을 통해 필드 수준으로 REAL/POTENTIAL/HALLUCINATED를 구분하고, 증거를 모아 판정 근거를 제시한다. 합성 벤치마크에서 97.1%의 정확도, 실세계 데이터에서 97.1%의 재현율을 달성했다.
왜 중요한가
대학술 연구의 인용은 신뢰성의 핵심이다. LLM이 생성한 인용은 표면적으로 타당해 보이지만 실제 출처와의 검증이 필요하며, 필드 단위의 진단이 없으면 수정이 어렵다. 본 연구는 12-code taxonomy와 CITETRACER 파이프라인을 통해 필드 수준으로 REAL/POTENTIAL/HALLUCINATED를 구분하고, 증거를 모아 판정 근거를 제시한다. 합성 벤치마크에서 97.1%의 정확도, 실세계 데이터에서 97.1%의 재현율을 달성했다.
핵심 기여
12-code taxonomy
REAL, POTENTIAL, HALLUCINATED의 3대 클래스와 R1–R3, P1–P3, H1–H6의 세부 코드를 제시하여 필드별 인용 오류를 정확히 진단하는 구체적 분류체계를 제공한다.
CITETRACER 아키텍처
Reference Extractor, Cascading Evidence Collector, Field Matcher, Class-Specialist Judgers의 4개 모듈로 구성된 다중 에이전트 detector를 제시하고, 각 모듈이 필드 단위 verdict를 내리며 ambiguous 사례를 전문 심판자에게 전달한다.
대규모 벤치마크 및 실세계 평가
2,450-citation synthetic benchmark와 957 real-world fabricated citations로 ground-truth를 구성하고, PDF/BibTeX 입력에서 최상위 성능을 달성한다. 3개Class의 F1 및 per-subtype 성능이 모두 개선된다.
실험 결과 및 효율성
합성 벤치마크에서 97.1%의 accuracy, BibTeX 입력에서 REAL 97.0, POTENTIAL 95.8, HALLUCINATED 98.5의 F1을 달성. PDF 입력에서 REAL 95.1, POTENTIAL 95.5, HALLUCINATED 96.9. 실세계 데이터에서 recall 97.1%. 엔드-투-엔드 속도는 약 0.50 citations/s로 운영된다.
오픈 소스 벤치마크/도구
프레임워크와 벤치마크 데이터는 GitHub 저장소 https://github.com/aaFrostnova/CiteTracer에서 공개된다.
핵심 아이디어 이해하기
The 인용은 학술 커뮤니케이션의 핵심 인프라이며, 인용 항목의 메타데이터가 외부 확인 가능성으로 검증되어야 한다. 기존 도구는 필드별 체크를 부분적으로 다루거나 이진 Real/Fake 판단만 제공했으나, 본 연구는 12-code taxonomy를 기반으로 필드 단위 검증 신호를 제공하고, 4단계 모듈로 구성된 다중 에이전트 프레임워크를 통해 easy 케이스를 빠르게 처리하고 어려운 케이스를 노출시킨다. 또한 memory/URL Fetch/ Scholar Connectors/Web Search의 캐시 및 다중 소스 증거 수집으로 누락 가능성을 최소화한다.
방법론
전체 접근은 네 모듈로 구성된다: Reference Extractor, Cascading Evidence Collector, Field Matcher, Class-Specialist Judgers. 입력 논문의 각 참조를 structured citation으로 파싱하고, 외부 증거를 8대 학술 소스와 웹에서 수집한 뒤, Field Matcher의 결정 규칙 및 Matcher Agent의 잔여 상태를 통해 per-field verdict를 도출한다. 최종 verdict는 routing 함수 ρ에 의해 적절한 Class-Specialist Judger로 전달되어 REAL/POTENTIAL/HALLUCINATED 중 하나로 확정된다.
관련 Figure

네 모듈 간의 흐름과 상호작용, 증거 수집 경로, 판정 흐름을 시각적으로 제시한다. methodology의 핵심 구성 요소를 한눈에 파악 가능하며 anchors를 제공한다.
CITETRACER 파이프라인 다이어그램
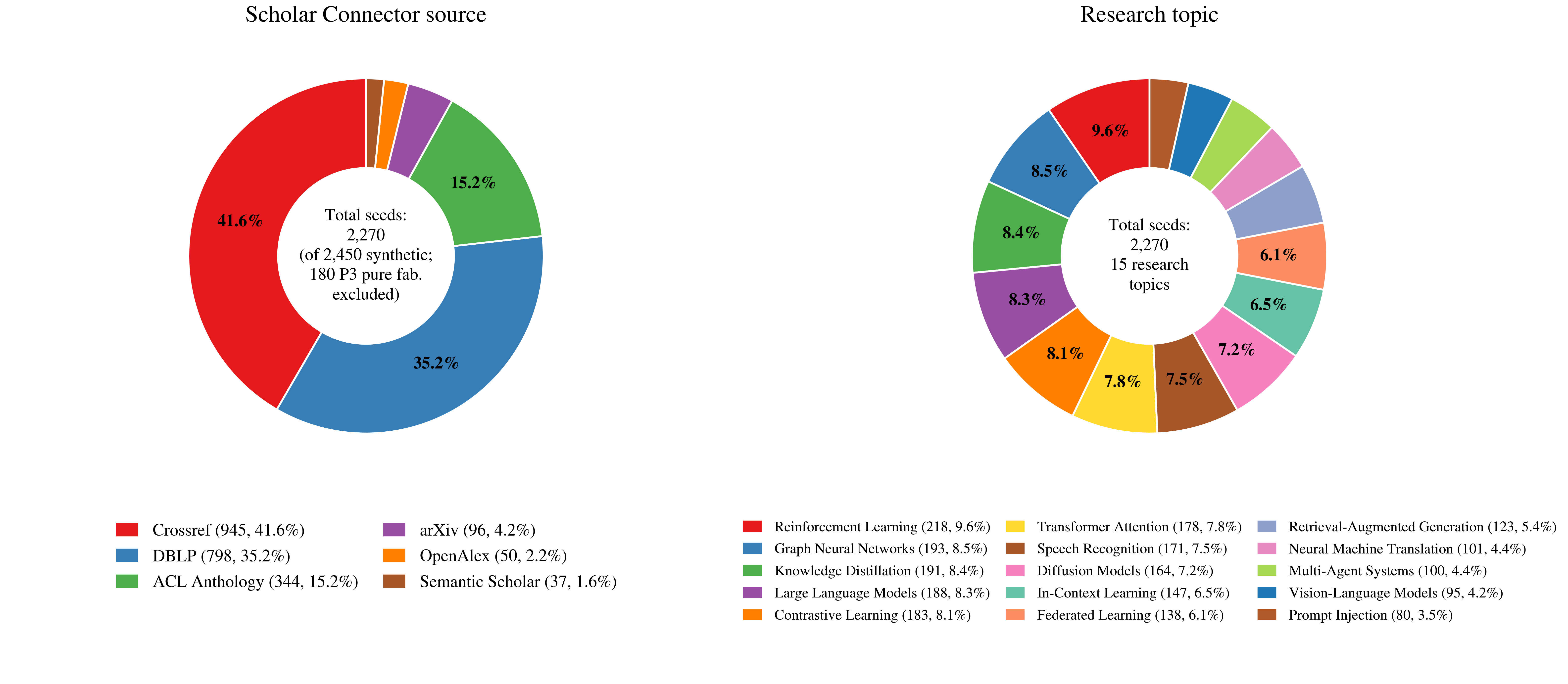
벤치마크의 소스 분포와 주제 다양성을 시각화하여 재현성과 커버리지를 설명한다.
Seed-pool 구성 및 연구 주제 분포를 나타내는 도넛 차트
주요 결과
- 주된 벤치마크: 2,450-citation synthetic benchmark에서 97.1% 정확도. BibTeX 입력의 F1: REAL 97.0, POTENTIAL 95.8, HALLUCINATED 98.5. PDF 입력의 F1: REAL 95.1, POTENTIAL 95.5, HALLUCINATED 96.9.
- Ablation: Web Agent 제거 시 REAL 79.6, POTENTIAL 79.0, HALLUCINATED 85.8; Scholar Connectors 제거 시 REAL 31.4, POTENTIAL 43.3, HALLUCINATED 69.1.
- Real-World Evaluation: ICLR 2026 desk-rejected에서 807건 중 796건을 HALLUCINATED로 탐지(재현율 98.6%), 150건 중 133건을 FAKE-REFERENCE로 식별.
관련 Figure
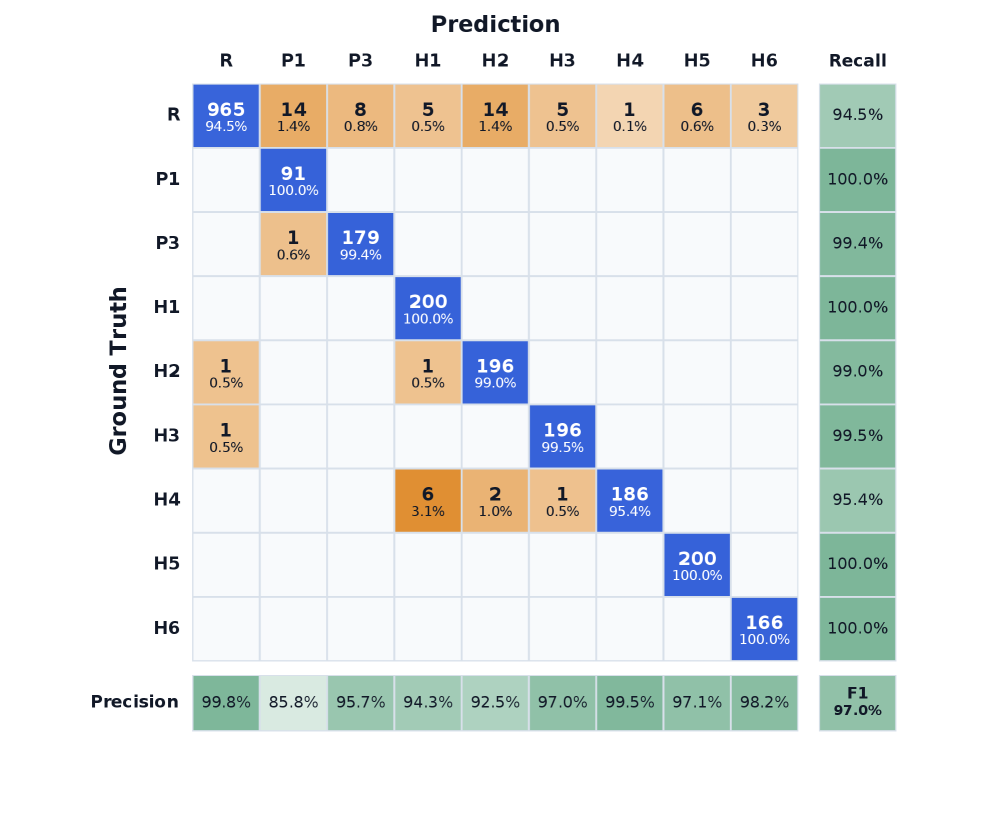
레이블 수준 REAL/POTENTIAL/HALLUCINATED 간의 예측 차이를 시각화하고, 각 클래스의 정밀도/재현율의 차이를 보여준다.
Prediction 매트릭스(Confusion Matrix) 형태의 결과 표
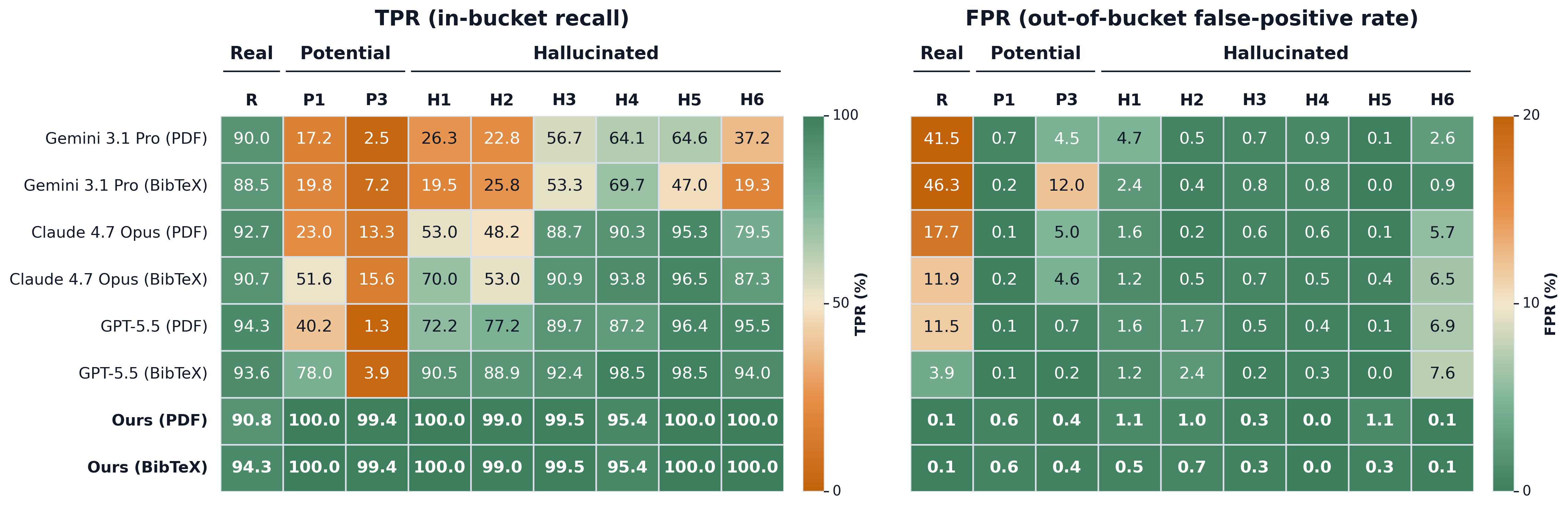
세부 코드별 성능을 한눈에 파악하게 하여 POTENTIAL/HALLUCINATED 구분의 난이도와 개선 영역을 보여준다.
세부 코드(P1-P6, H1-H6)별 TPR/FPR 히트맵
기술 상세
4-모듈 아키텍처의 구체적 동작: (1) Reference Extractor는 OCR으로 참조 블록을 탐지하고 crop된 이미지와 OCR 텍스트를 재파싱해 {title, authors, venue, year, doi/arxiv_id/url}를 산출한다. (2) Cascading Evidence Collector는 Memory, URL Fetch, Scholar Connectors, Web Search의 4단계로 증거를 수집하고, Stage별로 Field Matcher와 Class-Specialist Judgers가 누적 증거 Ei를 검토한다. (3) Field Matcher는 νf(·) 규칙 기반 정규화와 AMatcher 잔여 상태를 통해 필드별 매칭 상태를 산출하고, 모든 필드가 MATCH인 경우 DETerministic VALID로 종료한다. (4) Class-Specialist Judgers는 각 코드군에 맞춘 판단 임계값으로 verdicts를 산출하고, routing ρ에 따라 최종 라벨(REAL/POTENTIAL/HALLUCINATED)과 offending fields를 생성한다.
한계점
CS/ML 중심의 평가에 한정되어 있어 다른 분야에서의 일반화 가능성은 불확실하다. API rate limits 및 외부 엔진의 커버리지 차이에 의해 일부 후보 증거의 누락 가능성이 있음.
실무 활용
저자 및 편집자용 인용 신뢰성 검토 도구로 활용 가능하다. 제출 전 self-check를 통해 인용 필드의 정확성을 높이고, desk-review에서 의심 인용을 자동으로 표시한다.
- 제출 전 인용 목록의 필드 단위 검증
- 저널/학회 desk-review에서 인용의 신뢰성 선별
- 대규모 문헌 리뷰의 인용 관리 자동화
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.