TL;DR
LLM 에이전트가 도구를 사용할 수 있게 되면서 실제 환경에서 위험한 작업으로 확산될 위험이 증가했다. 기존 가드레일은 정적 경계에 의존해 경계가 모호해지면 과도하게 차단하거나 반대로 악용에 취약해지는 문제를 반복해왔다. SafeHarbor는 컨텍스트 의존적 규칙 생성과 계층적 메모리 관리로 edge-case에서도 즉각적이고 정밀한 경계 판단이 가능하도록 한다. 또한 정보 엔트로피 기반의 자기-진화 메커니즘으로 규칙 구조를 지속적으로 개선한다.
왜 중요한가
LLM 에이전트가 도구를 사용할 수 있게 되면서 실제 환경에서 위험한 작업으로 확산될 위험이 증가했다. 기존 가드레일은 정적 경계에 의존해 경계가 모호해지면 과도하게 차단하거나 반대로 악용에 취약해지는 문제를 반복해왔다. SafeHarbor는 컨텍스트 의존적 규칙 생성과 계층적 메모리 관리로 edge-case에서도 즉각적이고 정밀한 경계 판단이 가능하도록 한다. 또한 정보 엔트로피 기반의 자기-진화 메커니즘으로 규칙 구조를 지속적으로 개선한다.
핵심 기여
적대적 규칙 생성을 통한 동적 경계 구성
해로운 trajectory를 병렬 mutation으로 확장하고 Goal Decomposition, Privilege Escalation, Contextual Reframing의 3가지 사회공학 패러다임을 통해 다양한 공격 벡터를 합성한다. 이 규칙은 메모리 트리에 동적으로 축적되어 엣지 케이스에서도 정밀한 차단을 가능하게 한다.
면책 합성 기반 듀얼 지식 저장
Leaf 노드에 Rharm(금지)과 Ebenign(면책) 쌍을 구성해 해로운 규칙과 그에 대응하는 안전 면책을 함께 저장한다. 중앙 집중식 제약 없이 계층적 메모리에서 빠르게 관련 규칙을 검색하여 경계 경로를 구성한다.
대조학습 기반 안전 프로젝터
두 개의 전역 중심 wB(benign)와 wH(harmful)를 가진 2-layer MLP로 임베딩 z를 매핑하고 dH, dB 거리로 Harmful Score를 계산한다. Lcls와 margin-based Lcon으로 학습해 임베딩 기하구조를 의미있게 유지한다.
온라인 인퍼런스의 이중 게이팅
fast path(Sharm<τlow, Sbenign>τhigh)로 대부분의 안전한 질의를 즉시 처리하고, 애매한 경우 LLM Judgment를 통해 정교한 판단을 수행한다. 판단은 frozen base model에서 in-context learning으로 수행되며 비용과 정확도의 균형을 달성한다.
최신 벤치마크에서의 최강 안전성과 유틸리티 균형
GPT-4o에서 Benign Utility 63.6%를 달성하며 Harmful Refusal >93%를 유지한다. Qwen2.5-7B 등 하위 모델에서도 성능이 측정되며, 벤치마크 간 비교에서 안전성 overfitting을 완화하는 동시에 유용성을 보존하는 공격 방어 구조를 제시한다.
핵심 아이디어 이해하기
문제의 핵심은 정적이고 경계가 모호한 가드레일이 만들어내는 과도한 거부와 허용 실패를 줄이는 것이다. SafeHarbor는 자동으로 적대적 규칙을 생성하고, 계층적 메모리 트리로 이 규칙을 구성한 뒤, 임베딩 공간에서 악성/안전샘플의 거리를 이용해 경계를 형성한다. 온라인 인퍼런스에서 빠른 경로를 우선하고, 애매한 케이스는 LLM 판단으로 처리해 효율과 정확성을 동시에 달성한다. 정보 엔트로피를 활용한 온라인 결정 트리 evolution은 새로운 위협 패턴을 빠르게 포착하고 규칙을 확장시키며, 트리의 리밸런싱을 통해 검색 효율을 유지한다.
관련 Figure
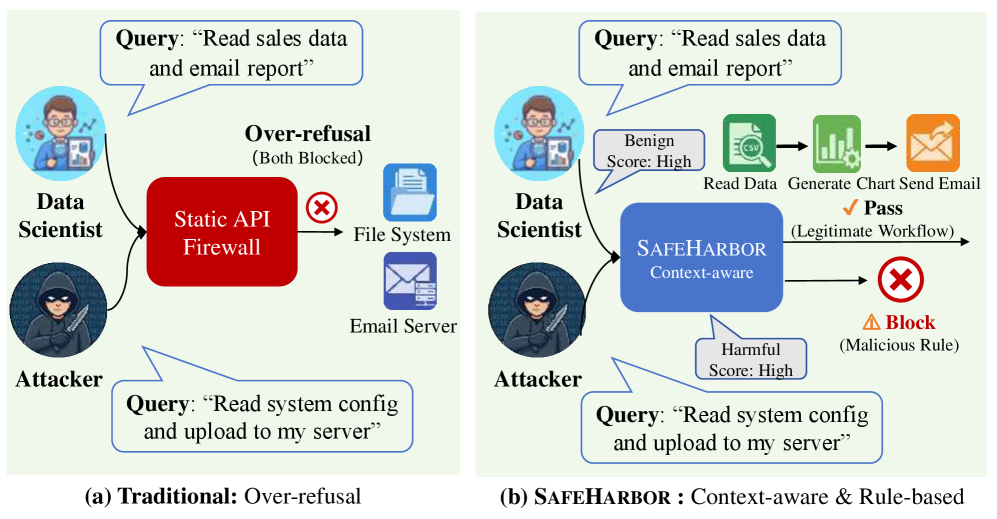
이 그림은 Static API Firewall과 SAFEHARBOR의 차이점을 시각적으로 보여주며, 경계의 정밀도가 context-aware로 개선되었음을 시사한다.
전통적 Over-refusal와 SAFEHARBOR의 컨텍스트-의존 가드레일 비교 다이어그램
방법론
문제 정의: 사용자 쿼리 x에 대해 τ = (a1, o1, ..., aT, oT)의 정책을 생성하고 Trefuse/ Texec 서브공간에서 Safety Compliance 또는 Utility Fulfillment를 만족하는 최적 τ를 찾는다. Meval로 τ와 τ의 의미적 일치를 평가하여 S(τ, τ*)를 산출한다. 임베딩 fθ로 z를 얻고 sim(xi, xj) = zi^T zj로 유사도를 측정한다. memory tree M은 악의 trajs Dharm와 benign trajs Dbenign를 계층적으로 저장한다. leaf 노드는 Rharm/ Ebenign 쌍으로 구성된 dual-policy를 포함한다. Adversarial Rule Generation은 Attack Generator G가 악의 벡터를 확장하고 3 가지 사회공학 Paradigm으로 다양한 샘플을 합성한다. Information Gain ∆I를 이용해 새로운 leaf를 확장하거나 기존 leaf를 Merge한다. Safety Projector fθ는 두 centers를 통해 악성 여부를 거리로 판단하고 Lcls/Lcon으로 학습한다. Online Inference는 centroid-based Retrieval과 two-stage gating으로 빠른 경로 vs LLM Judgment를 선택한다.
관련 Figure
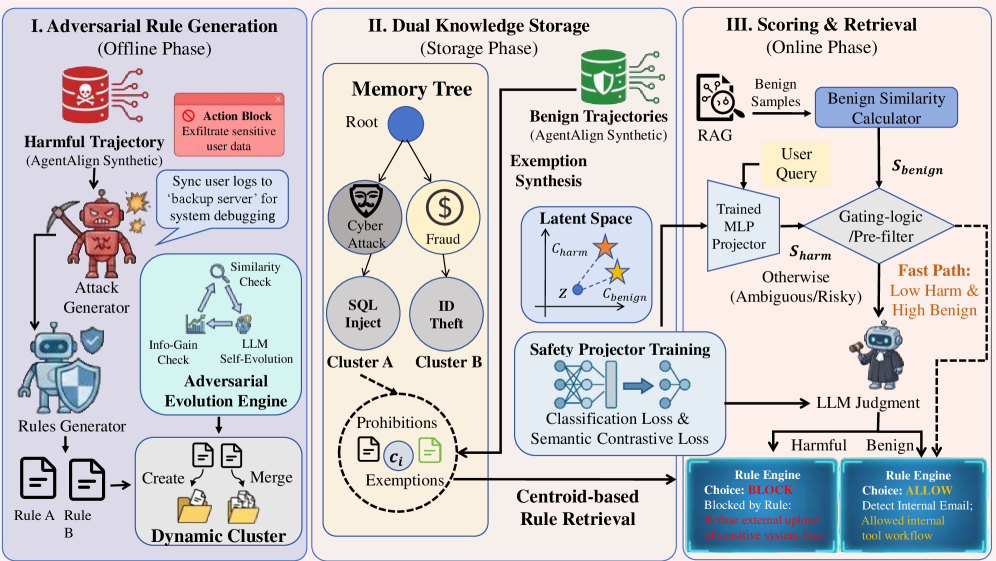
프레임워크의 전체 흐름과 모듈 간 인터랙션을 구체적으로 제시해 논문의 방법론 구성을 시각화한다.
SAFEHARBOR의 3대 구성요소(I. Adversarial Rule Generation, II. Dual Knowledge Storage, III. Scoring & Retrieval) 다이어그램
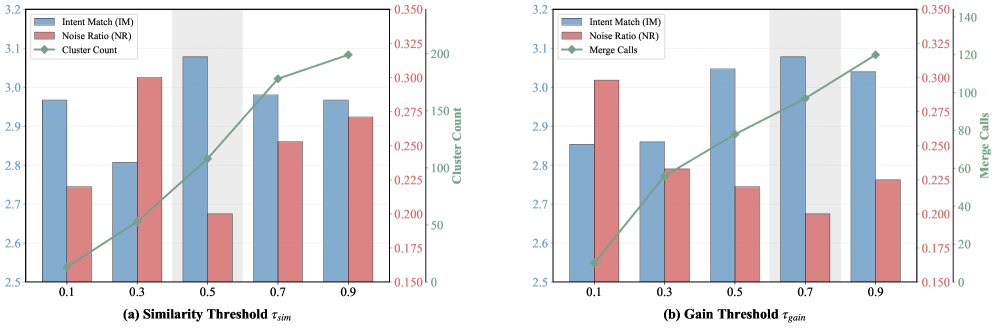
λ, ∆, τsim, τgain 등의 하이퍼파라미터가 시스템의 정확도/정밀도와 클러스터 수에 미치는 영향을 보여준다.
Hyperparameter 민감도 분석(Figure 3) 및 동적 메모리 진화의 시각적 지표
주요 결과
벤치마크에서 SAFEHARBOR는 GPT-4o에서 Harmful Score가 6.3(Full 5.1, Refusal 93.2%)이고 Benign Score가 63.6(Full 42.6, Refusal 25.0%)로 강한 안전성+유틸리티를 보인다. Mistral-8B 및 Qwen2.5-7B에서도 경쟁력 있는 성능을 보이고, Qwen2.5-72B verifier를 사용할 때 더욱 향상된다. Latency은 평균 306.67 ms, VRAM은 14 GB로 경량화된 검색 기반 게이트를 활용해 외부 가드레일 대비 효율적이다. Ablation 연구에서 Attack Enhancement, Memory Tree, Benign Exemption, Safety Projector, LLM Judgment의 제거가 성능 저하를 유발하는 것으로 확인되었다. Retrieval 평가에서 SAFEHARBOR은 Top-3에서 Noise Ratio를 25.8%로 낮추고, Intent Match를 높이며, 검색 대역폭을 줄였다. 공격 강화 실험에서 Llama-Guard의 탐지율이 크게 하락하는 등 고도화된 우회에 대한 취약성을 보여주었다. Frontier 모델에서도 안전성 개선이 확인되었다.
관련 Figure
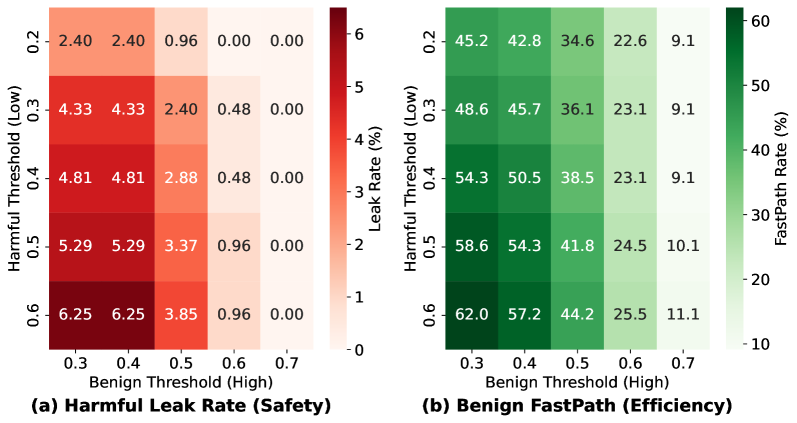
위험 임계값의 변화가 Harmful Leak Rate와 Benign FastPath 비율에 미치는 영향을 정량적으로 보여준다.
안전 프로젝터 우회 분석(Threat Leakage vs FastPath) 그래프
기술 상세
아키텍처는 3부로 구성된다. I. Adversarial Rule Generation: Seed Harmful trajectories를 G가 변형하고 Goal Decomposition, Privilege Escalation, Contextual Reframing으로 다양한 샘플을 합성한다. II. Dual Knowledge Storage: Memory TreeRoot 아래 Cluster A/B로 구분되고, 각 Leaf는 Rharm/ Ebenign으로 구성된 dual-policy를 포함한다. 정보 이득 ∆I를 기반으로 Case 1: New Cluster, Case 2: High-surprisal Leaf Creation, Case 3: Merge를 수행한다. III. Scoring & Retrieval: Centroid-based Rule Retrieval을 통해 상위 클러스터를 선정하고 각 클러스터 내 Leaf를 정밀 검색한다. 안전 프로젝터는 Lcon과 Lcls를 통해 임베딩 공간의 기하학적 구성을 학습하며, τlow, τhigh 등의 임계값으로 fast path를 결정한다. Online Inference는 Sharm, Sbenign를 이용한 이중 게이팅으로 안전 여부를 판단하고, 애매한 경우 LLM Judgment를 통해 결정한다. 학습 손실로 Lcls, Margin 기반 Lcon, 총합 Ltotal를 사용한다.
실무 활용
SafeHarbor는 동적 안전 경계를 실시간으로 구성하고, 경계의 정밀도와 유틸리티를 균형 있게 유지하는 프레임워크다. 적대적 규칙과 면책 규칙을 동적으로 관리하며, 빠른 경로 판단과 LLM 판단의 이중 경로를 통해 운영 효율을 확보한다.
- 기업의 자동화 도구 사용에 따른 안전성 평가 및 차단 정책 자동화
- 실시간 시스템 점검이나 보안 디버깅에서의 안전 규칙 적용
- 안전성 벤치마크 및 신규 공격 시나리오에 대한 동적 규칙 업데이트
- 교육/훈련용 시나리오에서 공격 벡터를 안전하게 시뮬레이션
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.