TL;DR
SDPA의 시퀀스 길이 의존성으로 인한 연산/메모리 증가를 해결하기 위해, Q/K/V를 대칭적으로 풀링하는 다층 피라미드와 비미분 Top‑K 선택을 적용한다. 선택 단계는 어텐션 커널 밖에서 수행되며, 선택된 서브시퀀스에 dense SDPA를 적용해 학습 중에도 인퍼런스에서의 dense 모델 성능을 보장한다. 또한 두 단계 학습 전략으로 전체 토큰 예산 하에서 Dense SDPA 재개 시 성능 회복이 가능함을 보여준다.
왜 중요한가
SDPA의 시퀀스 길이 의존성으로 인한 연산/메모리 증가를 해결하기 위해, Q/K/V를 대칭적으로 풀링하는 다층 피라미드와 비미분 Top‑K 선택을 적용한다. 선택 단계는 어텐션 커널 밖에서 수행되며, 선택된 서브시퀀스에 dense SDPA를 적용해 학습 중에도 인퍼런스에서의 dense 모델 성능을 보장한다. 또한 두 단계 학습 전략으로 전체 토큰 예산 하에서 Dense SDPA 재개 시 성능 회복이 가능함을 보여준다.
핵심 기여
Symmetric Q/K/V Pooling 및 다계층 피라미드
Q, K, V를 대칭적으로 풀링해 L 레벨 피라미드를 구성하고, 각 피라미드 엔트리가 (Q(ℓ), K(ℓ), V(ℓ)) 트리플을 형성하도록 하여 다층 표현을 유지한다. 피라미드의 엔트리 수는 PL−1ℓ=0 N/pℓ,总합은 O(N)이다.
비차별적 Top-K 선택 및 외부 스코어링
각 피라미드 엔트리에 대해 파라미터-프리 쿼리/키 점수(QK 및 KQ의 l2 노름 등)로 순위를 매기고, chunked-bitonic Top‑K 커널로 상위 항목을 선택한다. Top‑K는 비미분이며, 그래디언트는 수집‑배치 스캐터를 통해 흐른다.
Dense sub-sequence attention 및 scatter-back
선정된 (Q(ℓ), K(ℓ), V(ℓ)) 트리플을 모아 연속 서브시퀀스 S를 구성하고 stock FlashAttention으로 어텐션을 수행한 뒤, scatter-back으로 원래 위치에 분산시킨다.
2단계 학습 전략 및 회복 검증
Lighthouse로 프리훈련 후 dense SDPA로 재개하는 두 단계 학습을 통해, 50B 토큰 규모의 예산에서도 dense-from-scratch 대비 성능 회복을 확인한다.
핵심 아이디어 이해하기
- 시작점과 한계: Transformer의 Self-attention은 시퀀스의 모든 토큰 쌍에 대해 계산하므로 N² 복잡도를 낳고 긴 컨텍스트에서 자원 소모가 커진다. 2) 해결 원리: Lighthouse는 Q/K/V를 다층 피라미드에서 대칭적으로 풀링하고, 비미분 Top‑K로 중요한 엔트리만 선택한 뒤 이들을 contiguous 서브시퀀스로 묶어 stock FlashAttention으로 처리한다. 선택 단계는 학습에 영향을 주되, 키-값 경로의 압축을 통해 전체 모듈의 역전파에서의 복잡성을 줄인다. 3) 달라지는 점: selection- 및 어텐션 커널의 분리로 인해 학습-추론 간 커널 차이가 없고, Dense SDPA 재개를 통해 긴 컨텍스트에서의 성능 손실 없이 학습이 가능한 점이 실험적으로 입증된다.
방법론
- 네 가지 파이프라인으로 구성된 Lighthouse 어텐션: Pyramid pooling, Scoring/Top‑K, Gathered-Sequence 어텐션, Scatter-back. 2) 피라미드 구성: ℓ = 0..L−1에서 Q^(ℓ), K^(ℓ), V^(ℓ)를 p배수로 윈도우 풀링하여 트리플을 구성한다. 3) 스코어링/선택: ℓ2 노름 기반의 스코어를 Level 0에서 계산하고, 상위 엔트리를 통해 I를 얻은 뒤, I를 이용해 컨듀시 서브시퀀스를 구성한다. 4) Gather/Attn/Scatter: S 토큰에 대해 stock FlashAttention으로 어텐션을 수행하고, 결과를 원래 시퀀스로 scatter-back 한다. 5) 학습 흐름: Top‑K는 비미분이므로, 그래디언트는 scatter/back, Gather, FlashAttention, WQ/WK/WV로 역전파된다. 6) 구현 상세: top‑K 커널은 Chunked Bitonic으로 구현되고, Gather/Scatter는 PyTorch 연산으로 구현되며, 1M 토큰 규모의 컨텍스트에서도 context-parallel 실행이 가능하다.
주요 결과
주요 실험에서 Lighthouse는 dense-SDPA로의 재개를 통해 16k 스텝(≈50B 토큰)에서 Dense-from-scratch 대비 최종 손실 0.6980–0.7102로 낮아진다(기준 Dense SDPA 0.7237). Stage 1의 Throughput은 84–126k tok/s/GPU, 1M 컨텍스트에서도 2× 수준의 속도향상을 보였고 End-to-end 런타임은 22.5–27.0h로, dense-SDPA-from-scratch 대비 1.40×~1.69×의 속도up를 달성한다. Ablation에서 L=3, p=2, k=1536 구성이 최적으로 평가되며, k 증가가 항상 성능을 개선하지는 않는다. Needle-in-a-Haystack 평가에서 Retrieval 성능은 k와 scorer에 따라 달라지며, 일반적으로 k가 커질수록 성능이 향상된다. 512K 컨텍스트에서 forward/backward 런타임은 각각 Lighthouse가 SDPA 대비 21×, 17.3× 빠르게 나타난다.
관련 Figure
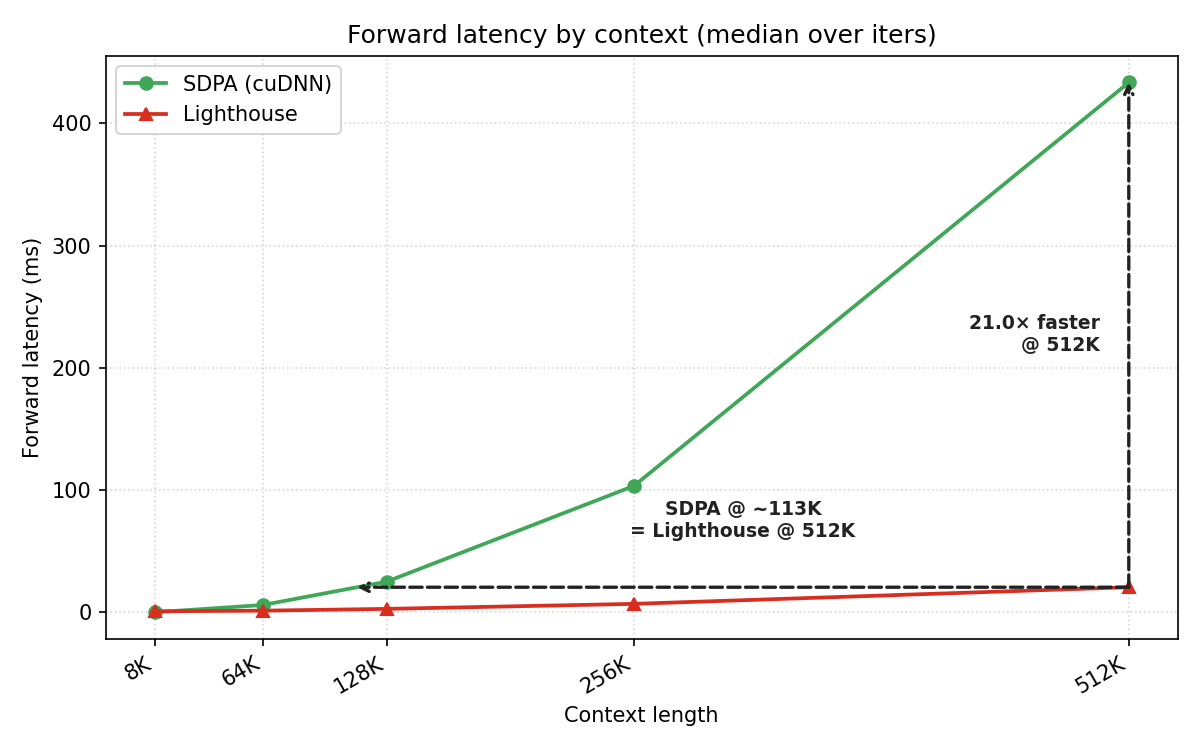
상대적 속도 향상은 긴 컨텍스트에서의 실제 학습 속도 이점을 직접적으로 보여준다. 이는 실무에서 긴 시퀀스 학습을 수행할 때의 이점으로 연결된다.
Forward latency: Lighthouse와 SDPA 간 컨텍스트 길이에 따른 추정 지연 비교 그래프(512K에서 Lighthouse가 크게 빨라짐).
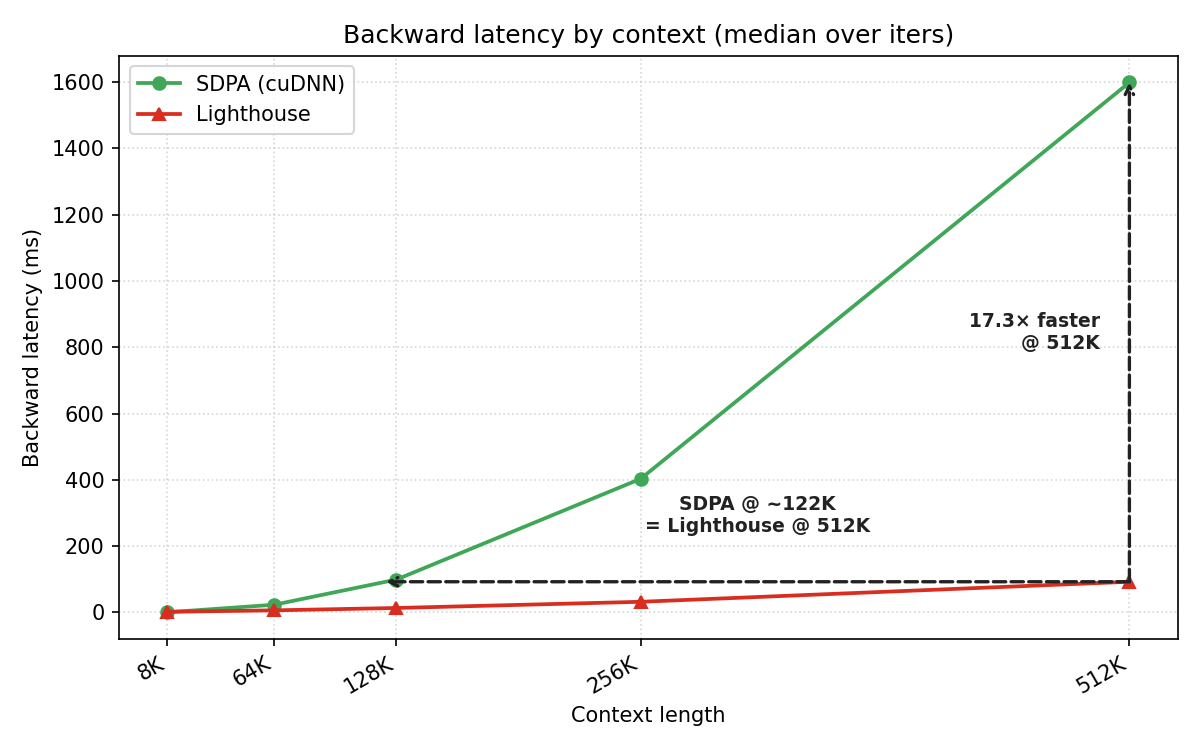
역전파에서도 비슷한 속도 향상이 관찰되며, 엔드-투-엔드 학습의 총 소요를 크게 감소시킴을 시사한다.
Backward latency: 컨텍스트 길이에 따른 역전파 지연 비교 그래프(512K에서 Lighthouse가 크게 빨라짐).
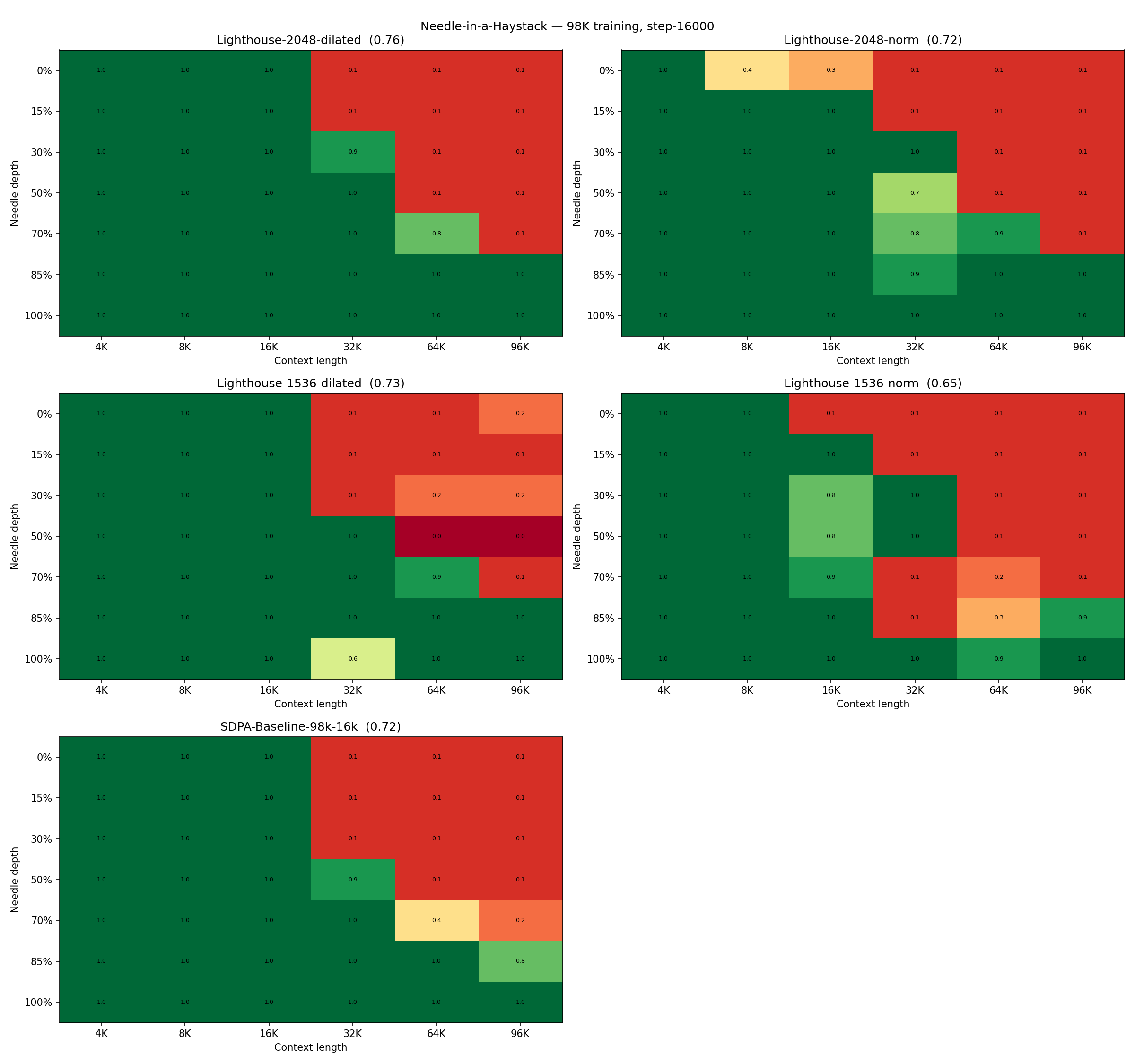
다양한 k, scorer, L, p 조합에 따른 검색 정확도와 재현율 차이를 보여주며, k의 증가가 성능에 미치는 영향과 scorer의 차이가 학습 손실과 retrieval 간 trade-off를 형성함을 시사한다.
Needle-in-a-Haystack(NIAH) 시각화: 98K 학습 단계에서의 여러 Lighthouse→SDPA 구성의 검색/회복 성능 비교 heatmap.
기술 상세
아키텍처 구성: 1) Pyramid Pool: Q, K, V를 ℓ=0..L−1까지 p 배수로 윈도우풀링하여 Q(ℓ), K(ℓ), V(ℓ) 트리플 생성; 2) Scoring/Selection: level 0에서 ∥Q_i∥₂, ∥K_i∥₂를 점수로 삼고, coarser level은 max-pooling으로 전달; Top‑K는 chunked-bitonic으로 구현되어 I를 산출; 3) Gathered-Sequence Attention: Qem, Kem, Vem을 S 토큰으로 구성하고, stock FlashAttention으로 Attn(Qem, Kem, Vem) 수행; 4) Scatter-Back: Ot를 원래 N 위치로 분산시키고, 각 위치 j에 대해 R(ℓ,i) 범위로 합산.
한계점
논문은 대칭 Q/K/V 풀링의 가정이 autoregressive decoding에서의 한계를 초래할 수 있음을 명시하고, 추론 시에는 dense SDPA 재개가 필요하다고 기술한다. 또한 inner attention의 복잡도는 Θ(S²d)로, S는 N으로 확장될 때 여전히 완전 선형은 아니다.
실무 활용
긴 컨텍스트를 다루는 LLM 사전학습에서 Lighthouse Attention은 학습 속도와 메모리 효율성을 크게 향상시키며, dense SDPA 재개를 통해 추론 시 성능을 보장한다. 1M 토큰 수준의 컨텍스트에서도 확장 가능하다.
- 롱 컨텍스트 LLM 프리트레이닝 가속화
- Dense SDPA 재개 전략 도입으로 인퍼런스 성능 보장
- context-parallelism을 활용한 대규모 프리트레이닝
- 멀티모달 모델의 긴 컨텍스트 확장 연구
코드 공개 여부: 공개
코드 저장소 보기키워드
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.