이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
Cerebras가 600억 달러 규모의 IPO를 달성하며 비 NVIDIA 하드웨어 아키텍처의 시장성을 입증했다. OpenAI의 Codex는 모바일과 데스크톱을 아우르는 에이전트 플랫폼으로 확장하며 사용자 경험과 통합의 중요성을 강조한다. AI 인프라 시장은 학습 중심에서 추론 경제와 효율적인 서빙 중심으로 재편되고 있다. 이러한 변화는 에이전트 평가, 관측 가능성, 최적화 기법에 대한 새로운 기술적 요구를 창출한다.
배경
LLM 추론 인프라, AI 에이전트 아키텍처, 모델 최적화 기초
대상 독자
AI 인프라 엔지니어 및 LLM 프로덕션 개발자
의미 / 영향
AI 인프라 시장이 학습 중심에서 추론 경제 중심으로 이동함에 따라, Cerebras와 같은 비 NVIDIA 하드웨어와 에이전트 하네스 최적화 기술의 중요성이 더욱 커질 전망이다.
섹션별 상세
Cerebras는 600억 달러 규모의 IPO를 통해 웨이퍼 스케일 하드웨어의 상업적 가치를 증명했다. 이 회사는 현재 OpenAI의 5.4 및 5.5 모델을 포함한 조 단위 파라미터 모델을 서빙하며 추론 인프라 시장의 주요 플레이어로 자리 잡았다.
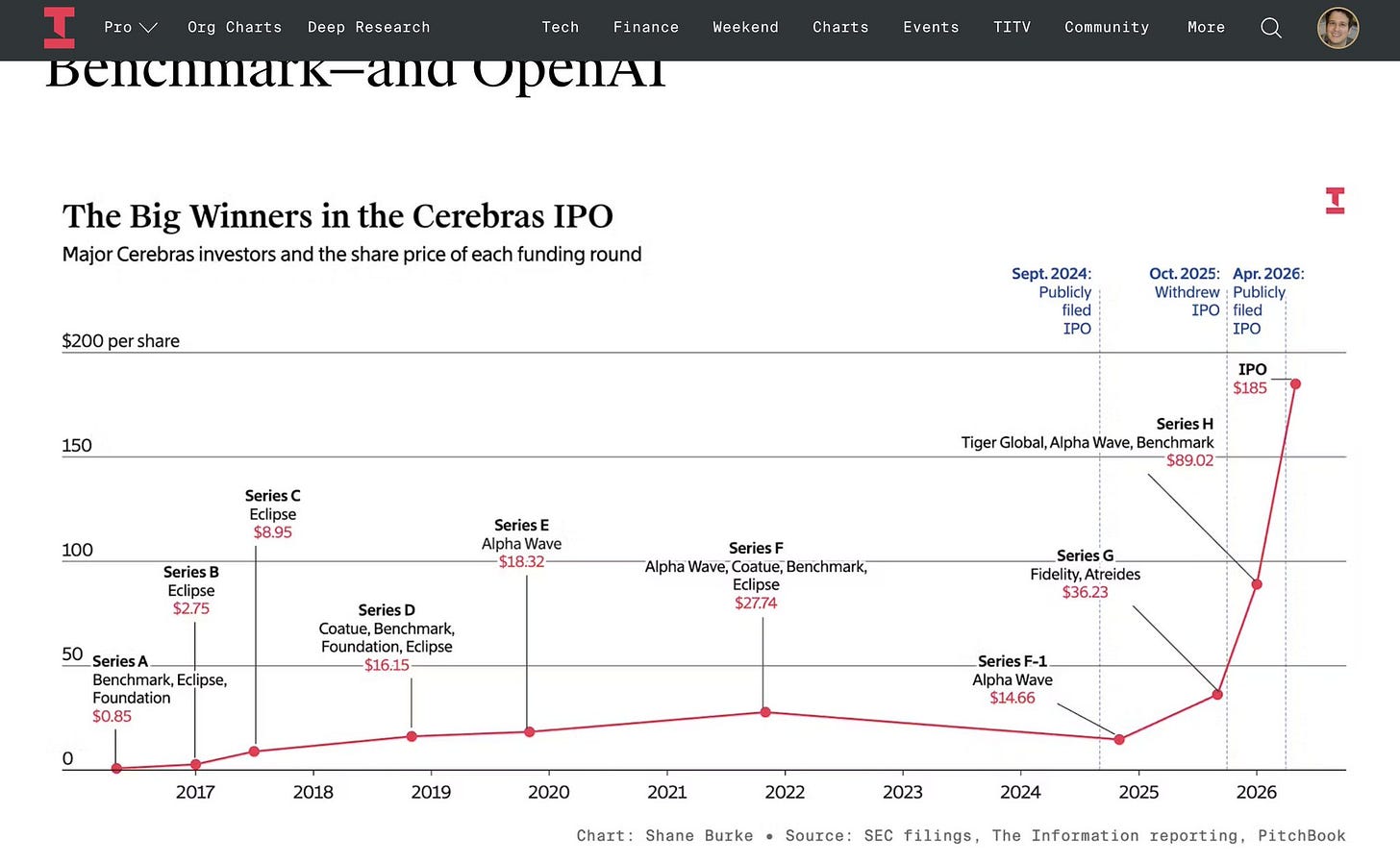
OpenAI의 Codex는 단순한 코딩 보조 도구를 넘어 모바일, 데스크톱, 서버를 연결하는 다중 표면 에이전트 플랫폼으로 진화했다. 개발 생태계는 모델 성능 자체보다 에이전트 하네스, 도구 통합, 사용자 경험 최적화에 집중하는 추세다.
에이전트 시스템의 복잡성이 증가함에 따라 평가와 관측 가능성이 핵심 인프라 과제로 부상했다. 기존 임베딩 기반 검색보다 grep 스타일의 텍스트 검색이 에이전트 작업에서 더 효과적이라는 연구 결과가 제시됐다.
학습 및 최적화 분야에서는 Adam 계열을 대체하는 Shampoo, Muon과 같은 새로운 최적화 기법이 주목받는다. 추론 효율화를 위해 KV 캐시 프루닝과 같은 메모리 관리 기법이 활발히 연구되고 있다.
경쟁 환경에서 Anthropic은 레이트 리미트를 재설정하며 개발자 점유율을 방어하고, xAI는 1.5조 파라미터 모델 출시를 준비 중이다. OpenAI는 개인 금융 데이터를 활용한 에이전트 서비스를 출시하며 개인화된 에이전트 시장을 공략한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 16.수집 2026. 05. 16.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.