이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
5월 한 달간 DeepSeek V4, Gemma 4 등 다수의 오픈 모델이 출시되며 생태계가 활발해졌다. CAISI는 오픈 모델이 미국 폐쇄형 모델에 비해 성능이 뒤처진다는 평가를 내놓았으나, 이는 특정 벤치마크와 평가 방식에 의존한 결과이다. 실제 코딩 작업 등에서는 모델별 최적화된 프롬프트와 도구 사용이 성능에 큰 영향을 미친다. 따라서 단순 벤치마크 수치만으로 모델 간의 절대적 격차를 단정하기 어렵다.
대상 독자
AI 모델 연구자 및 오픈소스 LLM 활용 개발자
의미 / 영향
벤치마크 중심의 모델 평가 방식이 실제 사용 환경과 괴리가 있음을 시사하며, 향후 모델 평가 시 도구 활용과 최적화된 프롬프트를 고려한 다각적 접근이 필요함을 보여준다.
섹션별 상세
DeepSeek V4, Gemma 4, Kimi K2.6 등 주요 오픈 모델이 연이어 출시되며 모델 생태계가 확장됐다.
CAISI는 Elo 점수를 기반으로 오픈 모델이 폐쇄형 모델보다 성능이 뒤처진다고 평가했다.
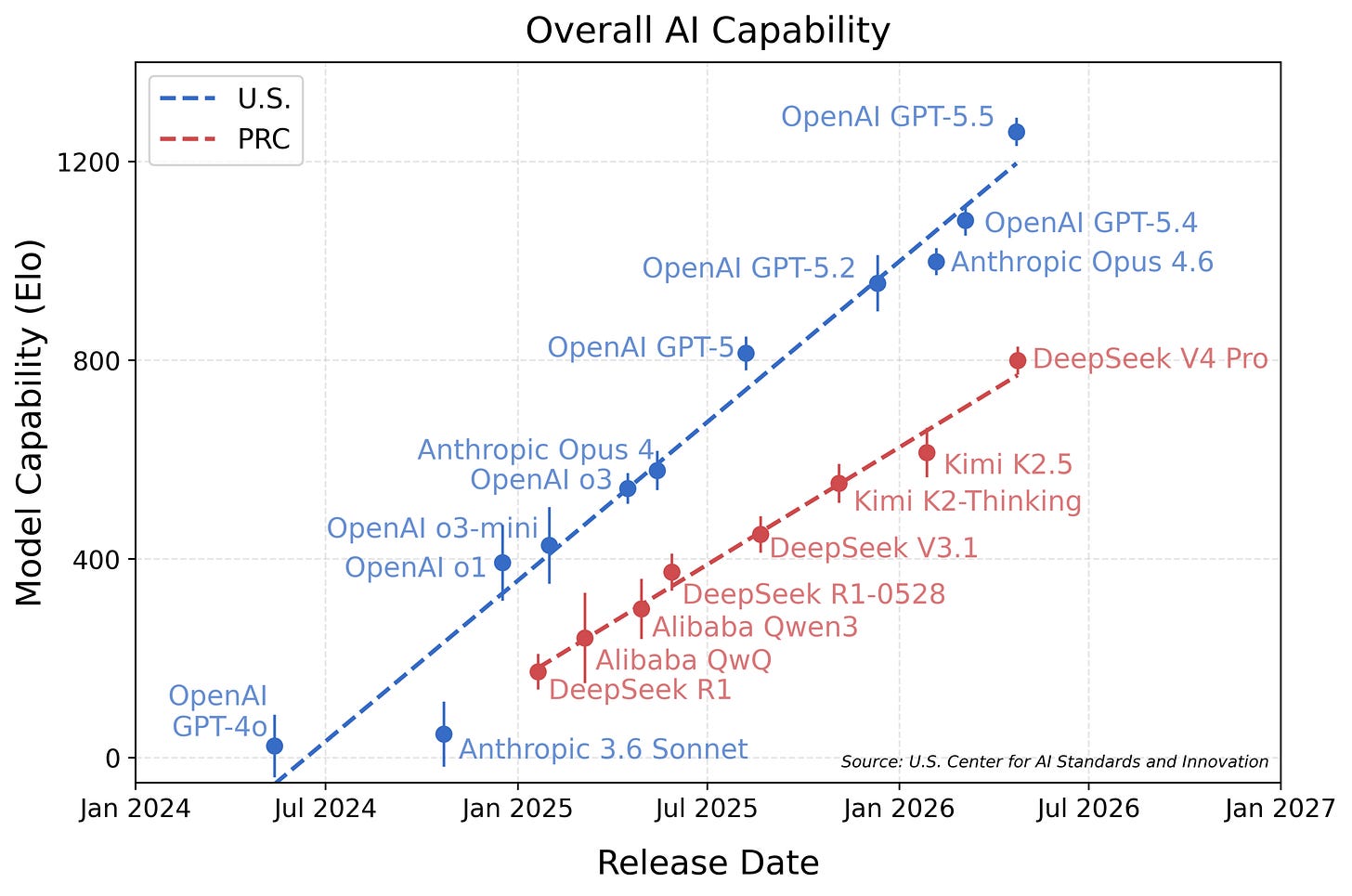
CAISI의 평가는 특정 벤치마크(CTF-Archive-Diamond 등)의 결과에 크게 의존하며, 이는 전체 모델 성능을 완전히 대변하지 못한다.
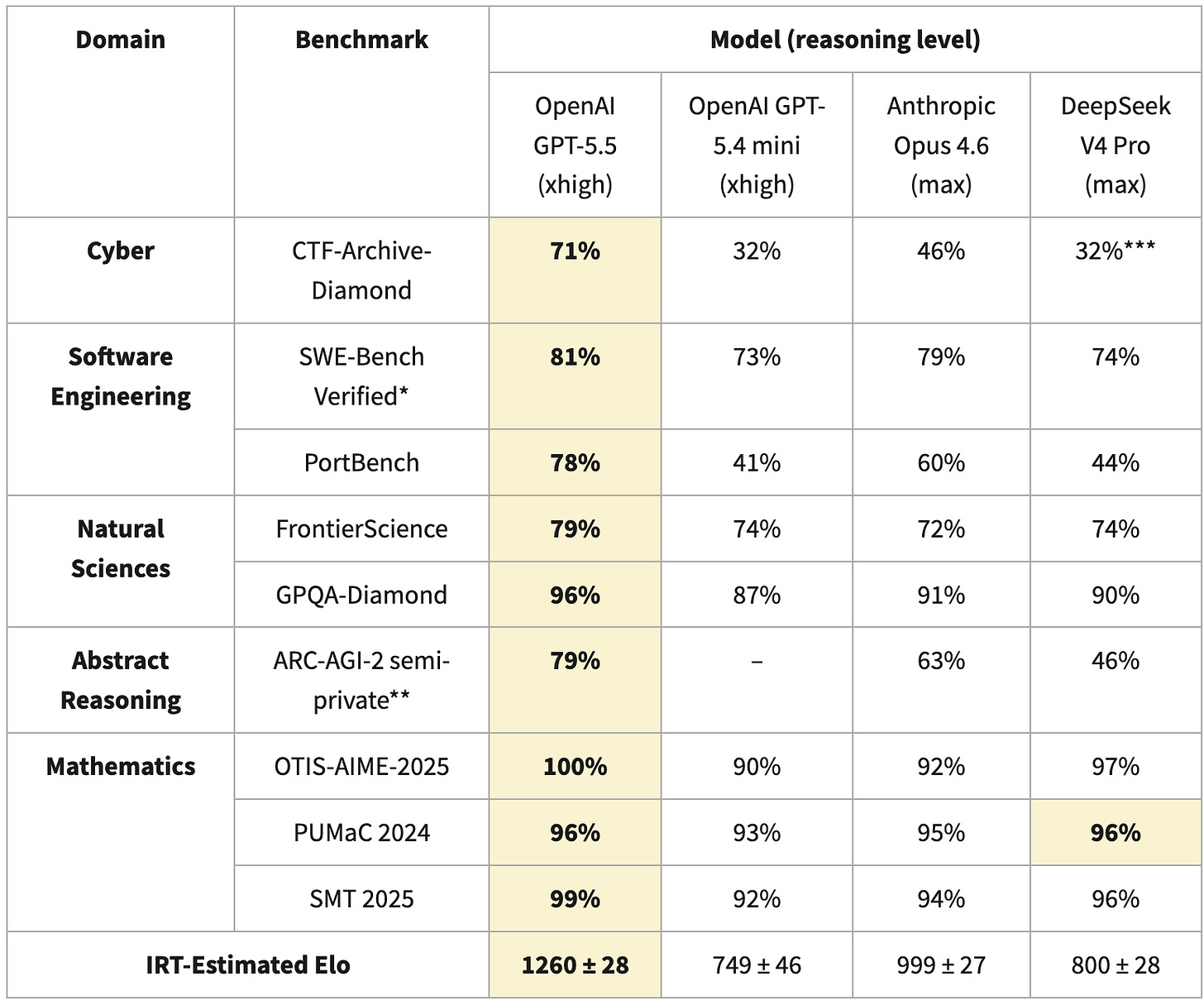
실제 코딩 작업에서는 Claude Code와 같은 전용 도구 사용 여부가 성능에 결정적 영향을 미치지만, 현재 벤치마크는 이를 충분히 반영하지 못한다.
오픈 모델과 폐쇄형 모델의 진정한 성능 비교를 위해서는 모델별 최적화된 프롬프트와 도구 활용 환경이 전제되어야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 17.수집 2026. 05. 17.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.