이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
AI 에이전트는 모델뿐만 아니라 도구 사용, 계획 수립, 메모리 관리 등 전체 시스템 구성에 따라 성능과 비용이 크게 달라진다. Open Agent Leaderboard는 6개의 다양한 벤치마크를 통해 범용 에이전트 시스템을 평가하는 오픈 프레임워크를 제공한다. 표준화된 프로토콜을 통해 서로 다른 환경의 벤치마크를 통합하고 에이전트의 품질과 비용 효율성을 동시에 측정한다. 실험 결과, 에이전트 아키텍처와 도구 최적화가 모델 선택만큼이나 결과에 결정적인 영향을 미치는 것으로 나타났다.
대상 독자
AI 에이전트 시스템을 개발하거나 프로덕션 환경에 배포하려는 엔지니어 및 연구자
의미 / 영향
에이전트 평가의 표준화는 모델 중심의 경쟁에서 시스템 중심의 최적화로 패러다임을 전환한다. 이는 기업들이 단순히 성능이 좋은 모델을 선택하는 것을 넘어, 비용 효율적이고 신뢰할 수 있는 에이전트 아키텍처를 설계하도록 유도한다.
섹션별 상세
에이전트 성능은 단순히 내부 모델에 의존하지 않고 도구 사용, 계획 수립, 메모리 관리 등 시스템 설계에 따라 크게 좌우된다.
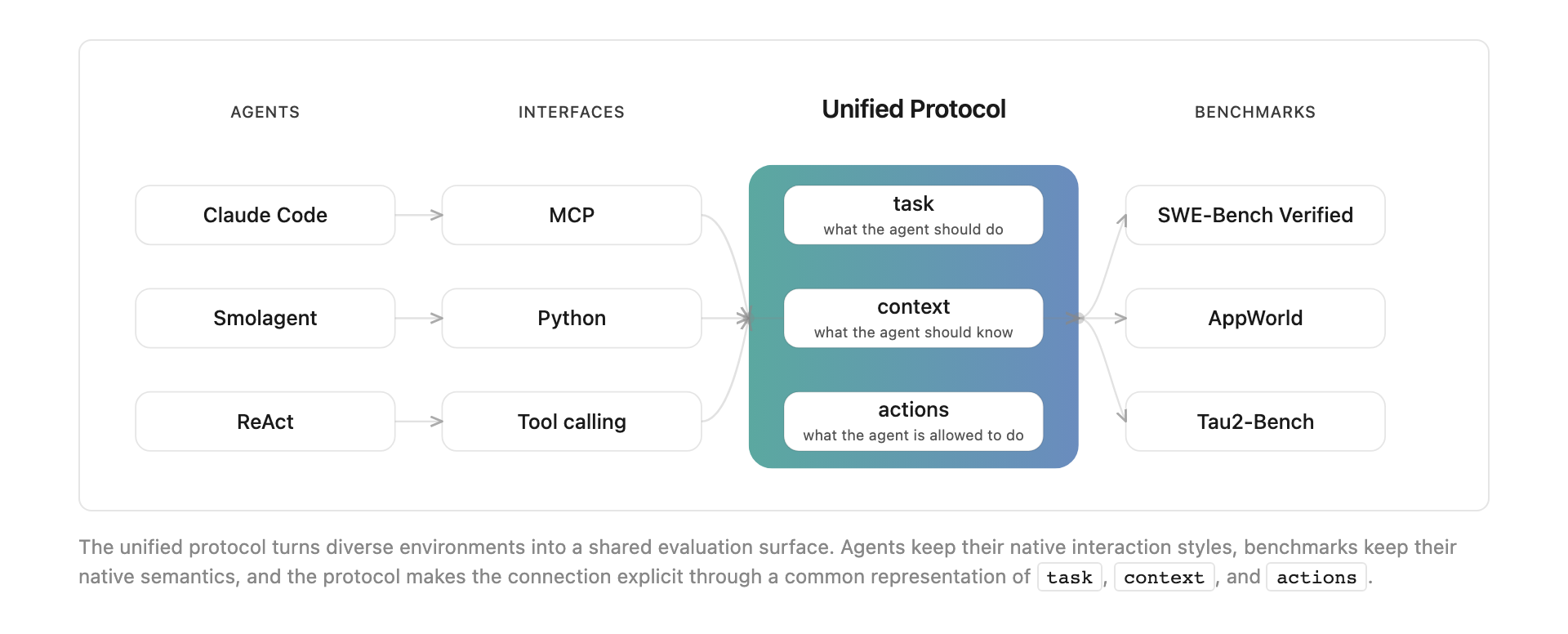
Open Agent Leaderboard는 SWE-Bench Verified, BrowseComp+, AppWorld 등 6개 벤치마크를 통합하여 범용 에이전트의 능력을 측정한다.
통합 프로토콜은 각 벤치마크의 과제, 맥락, 허용된 행동을 표준화하여 서로 다른 환경에서도 에이전트가 일관되게 작동하도록 지원한다.
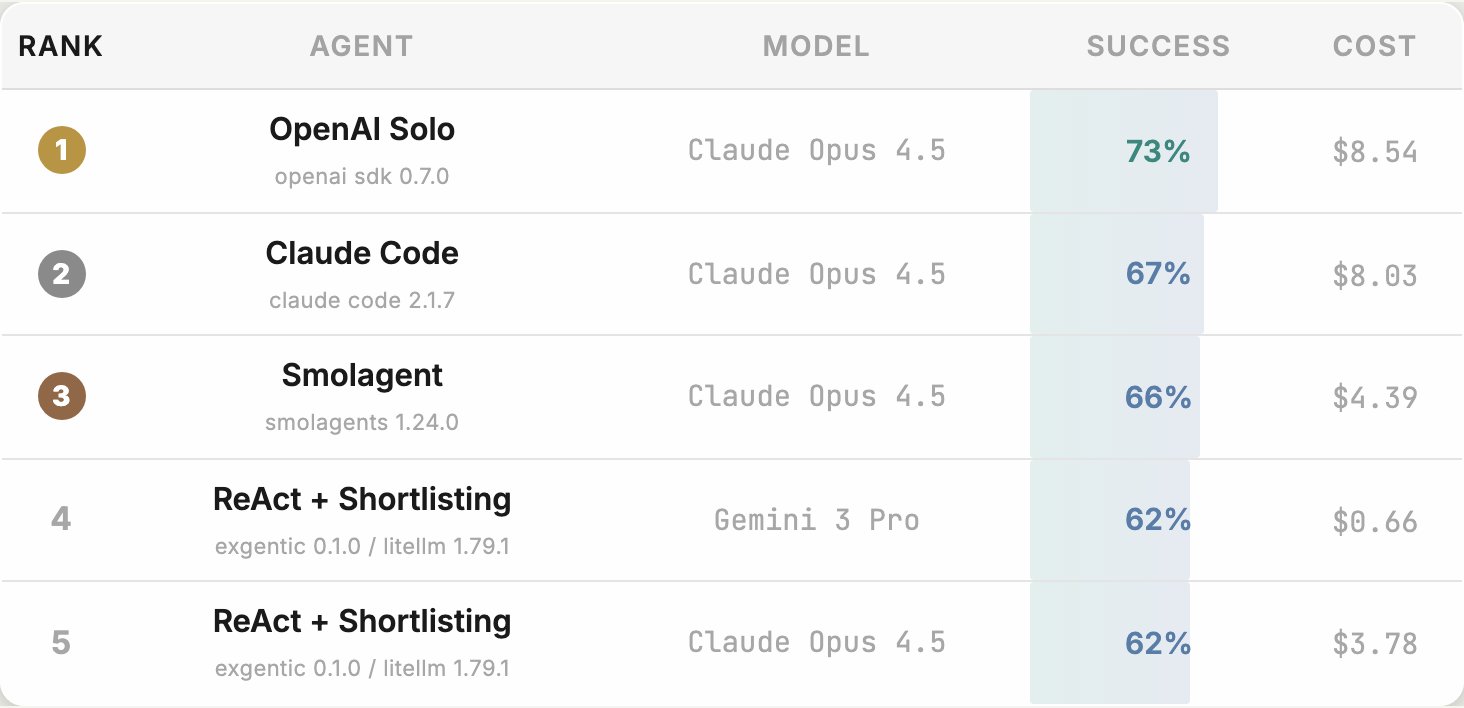
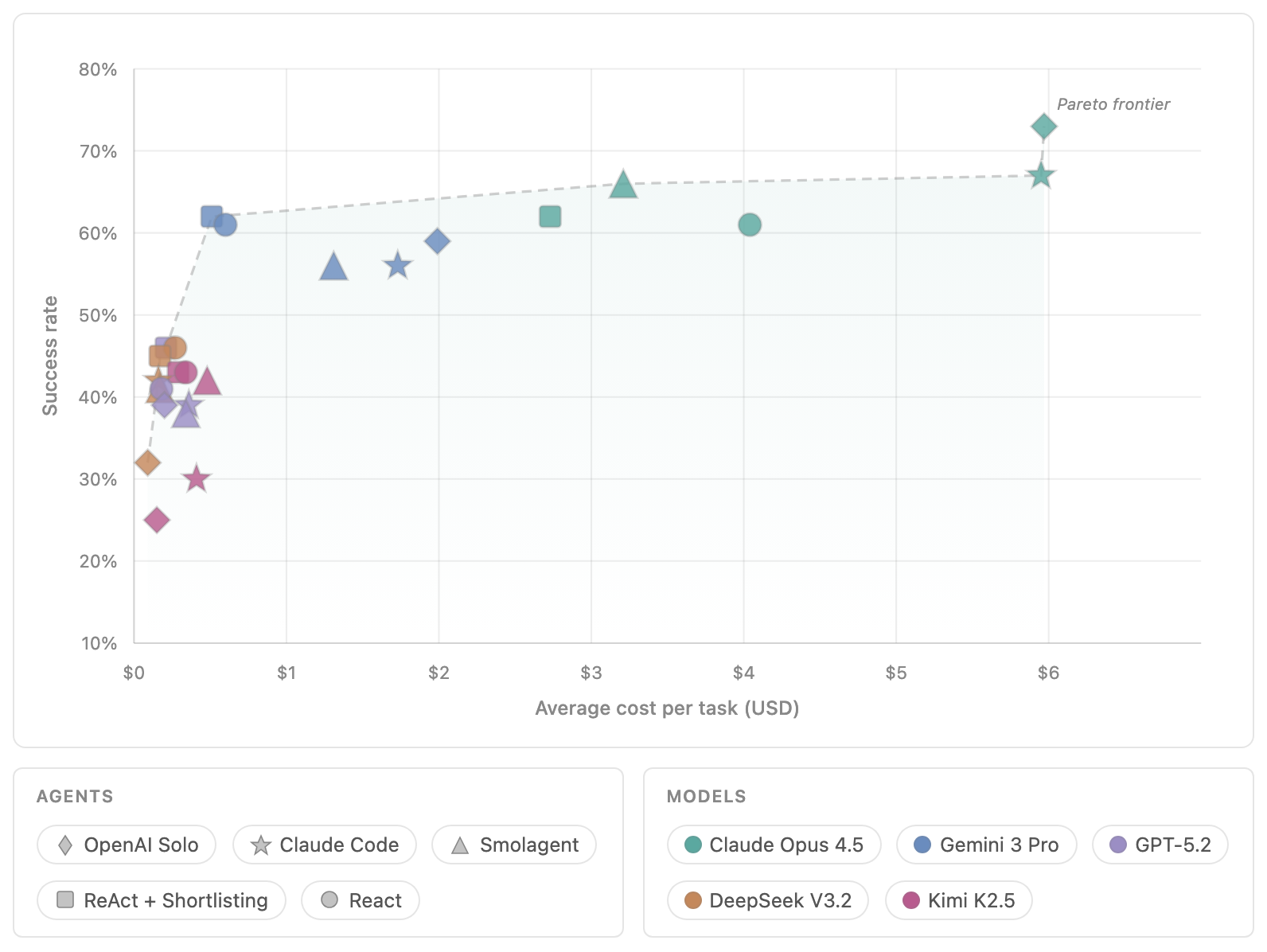
실험 결과, 도구 단축 목록(Tool shortlisting)과 같은 아키텍처 개선은 모든 모델에서 성능을 향상시키고 실패한 구성을 성공적인 구성으로 전환했다.
실패한 에이전트 실행은 성공한 실행보다 비용이 20~54% 더 많이 발생하여 프로덕션 환경에서 비용 효율성에 직접적인 영향을 미친다.
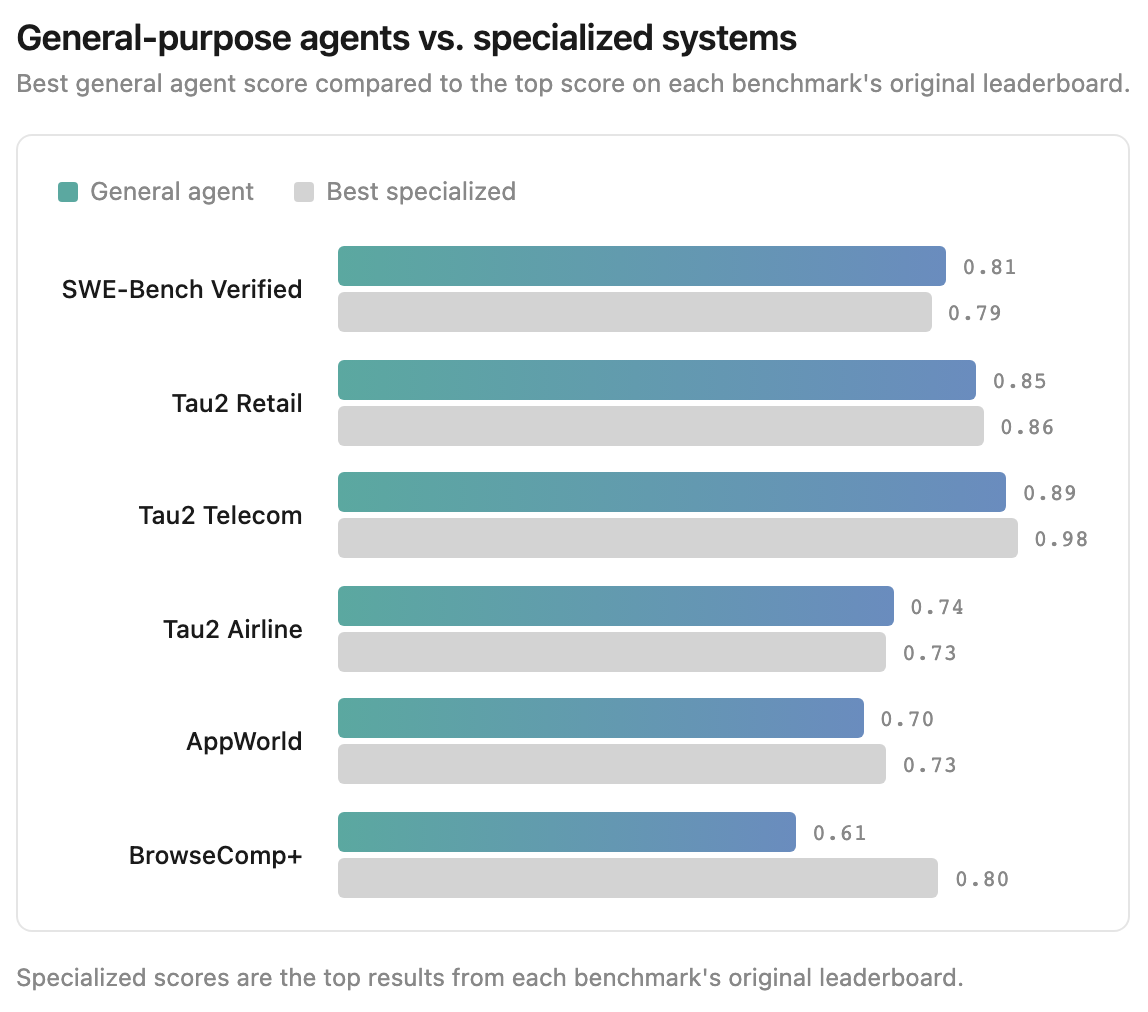
오픈 웨이트 모델인 DeepSeek V3.2와 Kimi K2.5는 특정 작업에서 경쟁력을 보였으나, 최상위 폐쇄형 모델 대비 평균 18~29% 낮은 성능을 기록했다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 18.수집 2026. 05. 18.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.