이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
LLM의 자동 회귀 생성 과정에서 KV 캐시가 GPU 메모리를 점유하며 메모리 벽(Memory Wall) 문제가 발생한다. 기존 PCIe 기반 시스템은 낮은 대역폭으로 인해 HOL(Head-of-Line) 블로킹을 유발하며 SLO를 위반한다. NVIDIA GH200과 같은 Superchip은 NVLink-C2C를 통해 900 GB/s의 고속 대역폭을 제공하여 이러한 병목을 해소한다. 기존 서빙 스택은 SLO를 고려하지 않거나 PagedAttention의 파편화 문제로 C2C 대역폭을 충분히 활용하지 못한다.
배경
LLM 추론 아키텍처, GPU 메모리 계층 구조, 인터커넥트 대역폭 개념
대상 독자
LLM 추론 엔진 및 인프라 최적화 엔지니어
의미 / 영향
고대역폭 인터커넥트를 갖춘 Superchip 아키텍처는 기존 PCIe 기반 시스템의 병목을 해결하여 LLM 서빙의 처리량과 지연 시간을 획기적으로 개선한다. 향후 고성능 LLM 추론을 위해서는 하드웨어 인터커넥트 특성을 고려한 새로운 메모리 관리 및 스케줄링 전략이 요구된다.
섹션별 상세
자동 회귀 생성 시 KV 캐시가 메모리를 빠르게 점유하며, 고부하 환경에서 SLO 위반을 초래한다.
PCIe Gen5x16의 제한적인 대역폭(32-64 GB/s)은 스왑 성능을 저하시키고 HOL 블로킹을 유발하여 지연 시간을 증가시킨다.
NVIDIA GH200은 Hopper GPU와 Grace CPU를 NVLink-C2C로 연결하여 900 GB/s의 대역폭을 확보함으로써 PCIe 병목을 돌파한다.
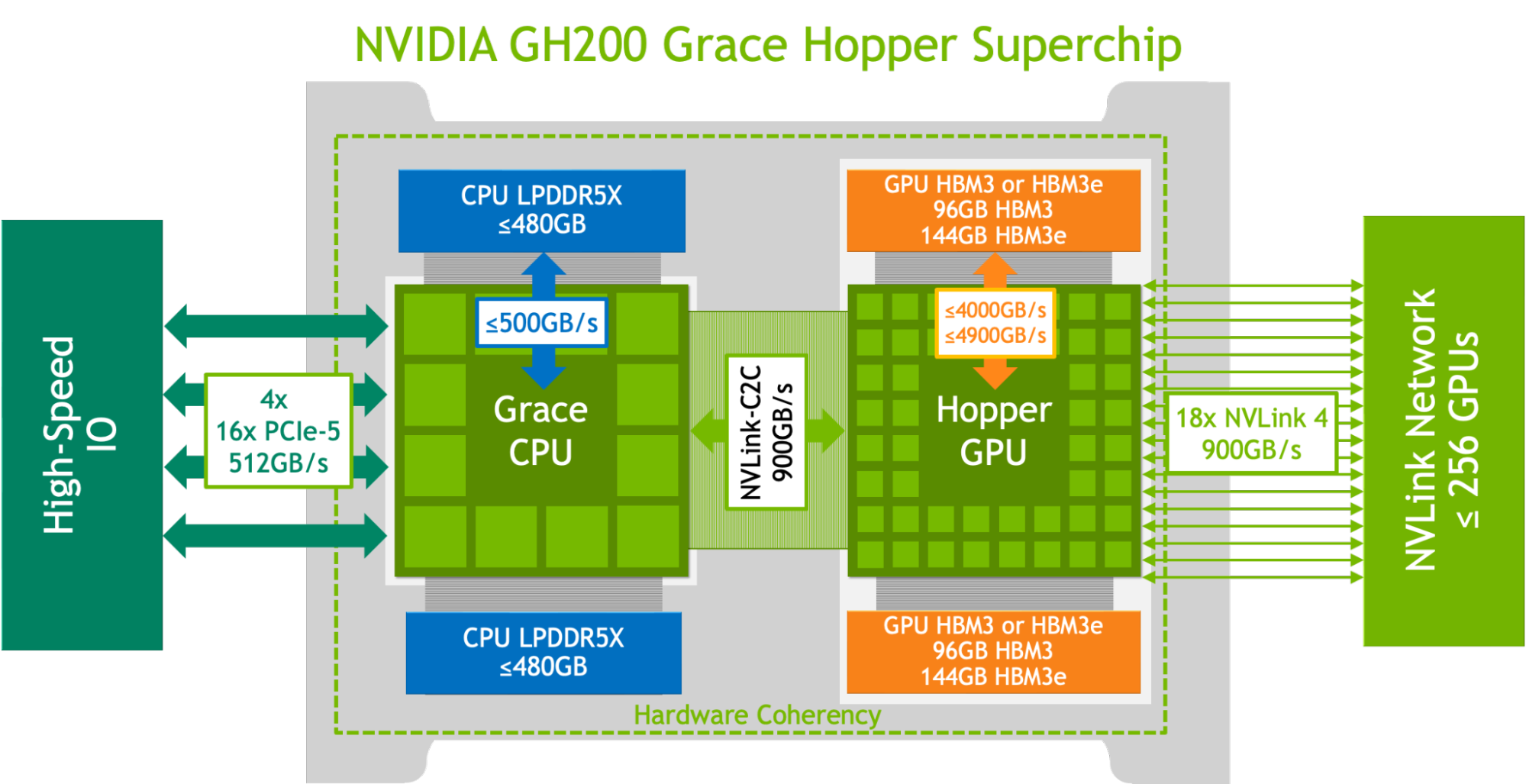
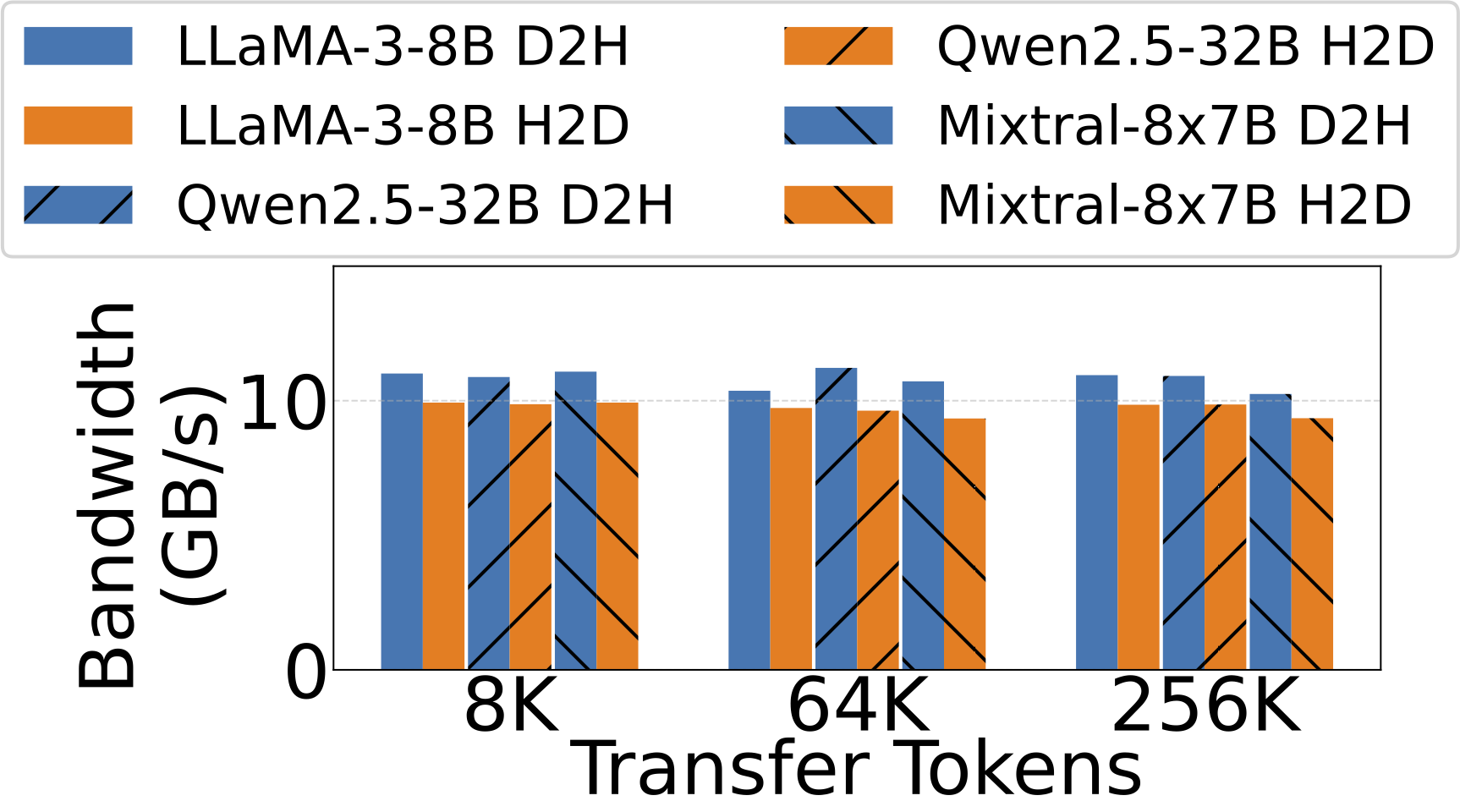
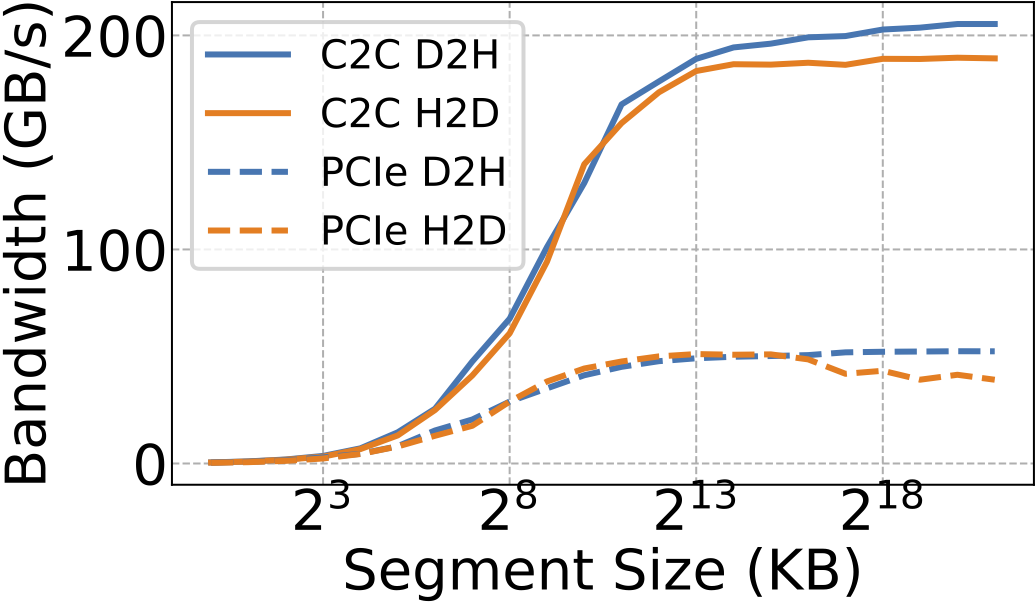
기존 서빙 스택은 SLO 기반의 대응이 부족하고, PagedAttention이 KV 캐시를 파편화하여 C2C 대역폭의 5% 미만만 활용하는 비효율이 존재한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 19.수집 2026. 05. 19.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.