이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
2025년 11월을 기점으로 LLM 시장은 코딩 에이전트의 실용화와 모델 성능 경쟁이 가속화되는 변곡점을 맞이했다. Anthropic, OpenAI, Google 등 주요 기업들이 주도하는 모델 경쟁 속에서 코딩 에이전트는 실무에 즉시 투입 가능한 수준으로 품질이 향상됐다. 오픈 웨이트 모델인 Gemma 4, GLM-5.1, Qwen3.6-35B-A3B 등이 등장하며 로컬 환경에서도 고성능 모델 구동이 가능해졌다. 기존의 벤치마크 테스트였던 '자전거 타는 펠리컨' 그림 생성은 모델들의 성능 향상으로 더 이상 유효한 변별력을 갖지 못하게 됐다.
대상 독자
LLM 트렌드와 기술 발전에 관심 있는 개발자 및 AI 실무자
의미 / 영향
코딩 에이전트의 실용화는 소프트웨어 개발 생산성을 획기적으로 높였으며, 로컬 모델의 성능 향상은 클라우드 의존도를 낮추고 온프레미스 AI 환경을 구축하는 데 기여한다. 모델 성능의 상향 평준화로 인해 기존의 단순한 벤치마크 방식은 재검토가 필요한 시점이다.
섹션별 상세
2025년 11월은 코딩 에이전트가 실무 수준의 품질을 확보한 중요한 변곡점이다. OpenAI와 Anthropic은 강화학습을 통해 코드 생성 품질을 높였고, 이는 개발자가 일상적으로 코딩 에이전트를 활용할 수 있는 환경을 조성했다.
Claude Sonnet 4.5, GPT-5.1, Gemini 3, Claude Opus 4.5 등 주요 모델들이 짧은 기간 동안 성능 우위를 번갈아 차지하며 치열한 경쟁을 벌였다.

Warelay 프로젝트로 시작된 OpenClaw는 개인용 AI 어시스턴트로 발전하며 Mac Mini 등 로컬 하드웨어에서 구동되는 디지털 펫 형태로 주목받았다.

Google의 Gemma 4, 중국 GLM의 GLM-5.1, Qwen의 Qwen3.6-35B-A3B 등 고성능 오픈 웨이트 모델들이 등장하며 로컬 환경에서의 LLM 활용 범위가 확장됐다.
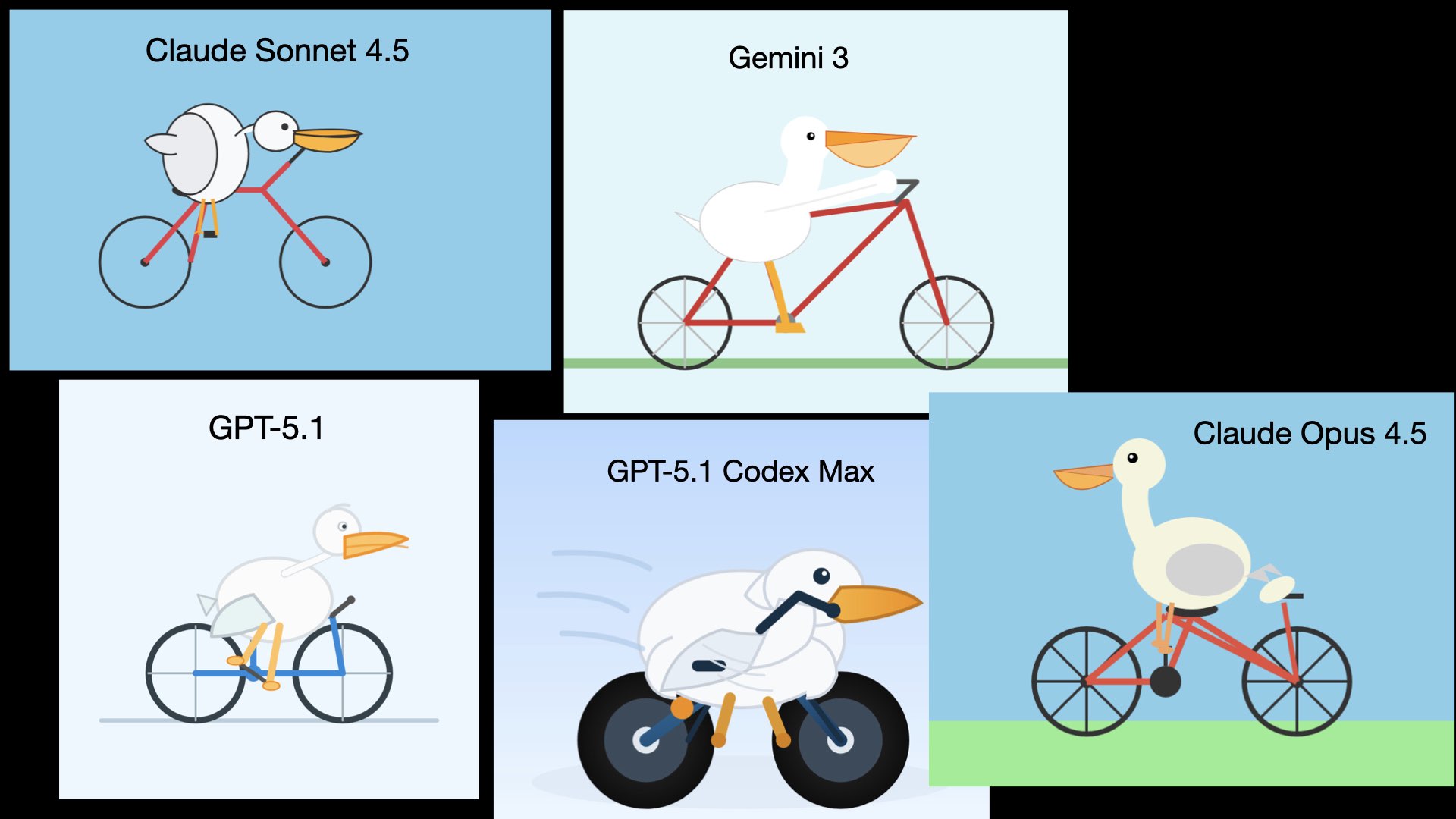
기존의 복잡한 이미지 생성 테스트였던 '자전거 타는 펠리컨'은 모델들의 성능이 상향 평준화되면서 더 이상 모델 간 변별력을 확인하는 벤치마크로서의 기능을 상실했다.
언급된 리소스
GitHubWarelay GitHub
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 19.수집 2026. 05. 19.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.