이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
자율주행차 플릿은 매일 차량당 최대 152TB의 데이터를 생성하며, 이 중 대부분은 반복적이고 가치가 낮은 데이터로 구성되어 학습 효율을 저하시킨다. 센서 데이터 트리아지는 원시 로그를 품질, 참신함, 학습 가치에 따라 필터링하고 우선순위를 정해 주석 작업의 효율성을 극대화하는 과정이다. 이 과정은 규칙 기반 필터, 시나리오 기반 우선순위 지정, 능동 학습을 활용하여 모델 성능 향상에 기여하는 핵심 데이터만 선별한다. 다중 센서 퓨전 환경에서는 시간 정렬과 센서 간 일관성 검증이 필수적이며, 이를 통해 모델 학습을 위한 고품질의 지상 진실 데이터를 확보한다.
배경
자율주행 센서 데이터 구조, 데이터 라벨링 파이프라인, 기본적인 머신러닝 학습 프로세스
대상 독자
자율주행차 개발 및 데이터 파이프라인 엔지니어
의미 / 영향
데이터 트리아지는 방대한 자율주행 데이터를 효율적으로 관리하여 라벨링 비용을 절감하고, 모델의 안전성과 엣지 케이스 대응 능력을 획기적으로 개선한다. 이는 대규모 데이터셋을 다루는 자율주행 기업이 프로덕션 환경에서 모델을 지속적으로 업데이트하는 데 필수적인 인프라이다.
섹션별 상세
자율주행차의 데이터 과부하는 수동 라벨링 비용을 급증시키며, 단순하고 반복적인 데이터는 모델의 엣지 케이스 대응 능력을 저하시키는 원인이 된다.
근거
- Fleets with multi-sensor systems produce between 11 TB and 152 TB of data per vehicle daily. — The Data Bottleneck Facing Autonomous Vehicle Training Programs section
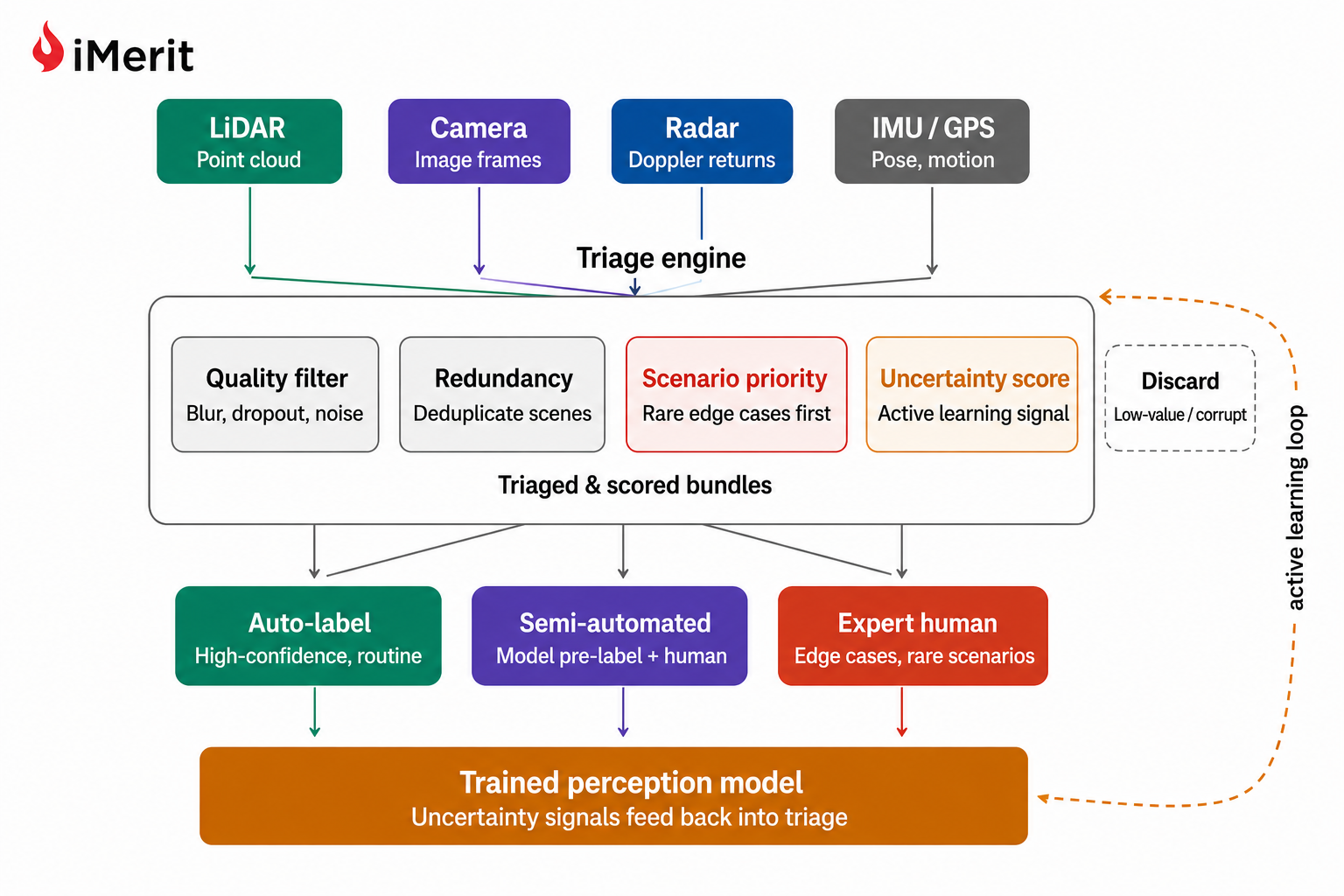
규칙 기반 필터는 센서 드롭아웃이나 모션 블러 등 부적합 데이터를 제거하고, 중복 제거 기술은 유사한 장면을 걸러내어 라벨링 예산을 절감한다.
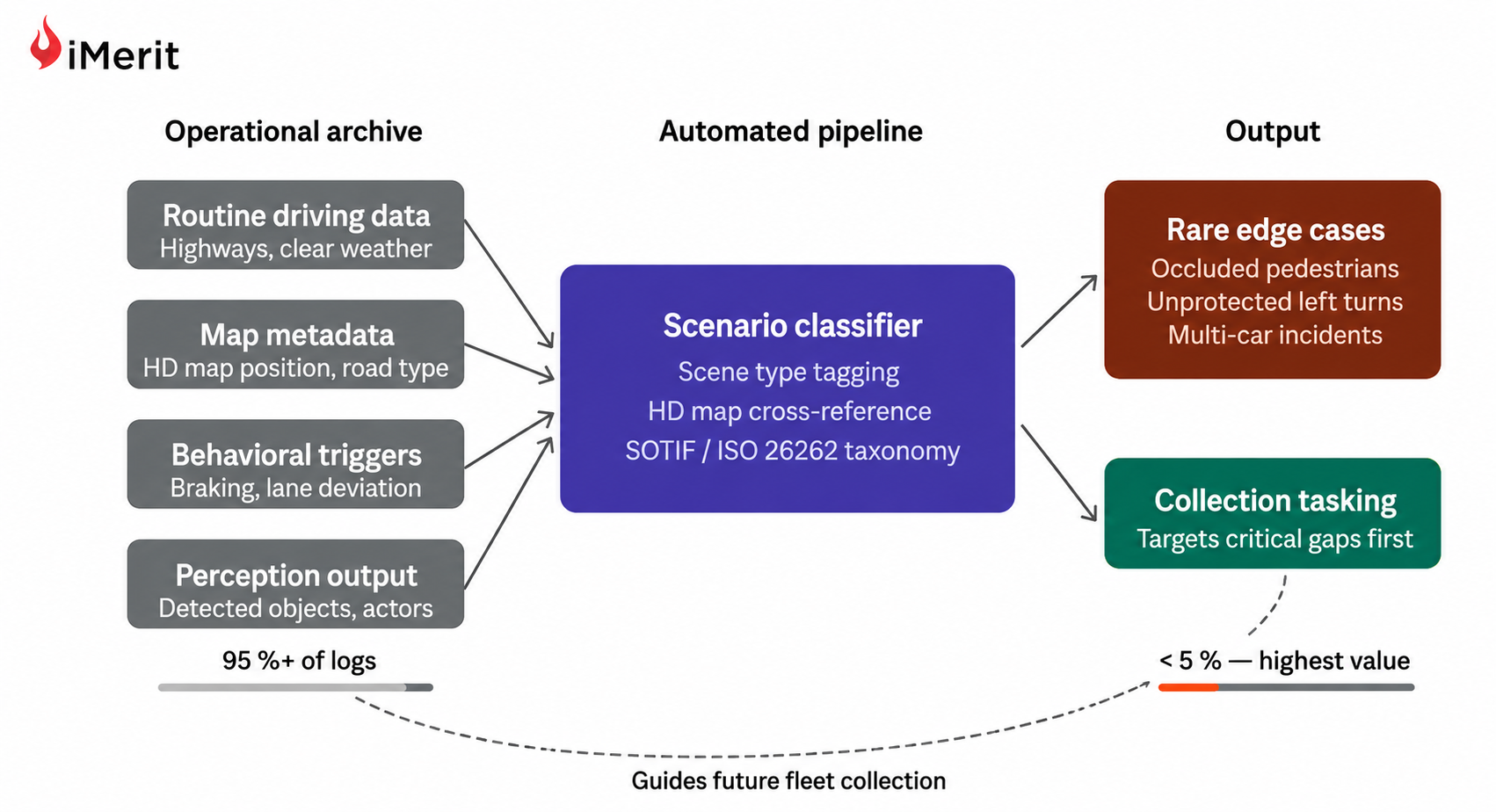
시나리오 분류기는 학교 버스나 보행자 등 희귀하고 중요한 이벤트를 우선순위에 배치하며, 엔트로피 점수는 모델이 가장 어려워하는 데이터를 식별하여 라벨링 효율을 높인다.
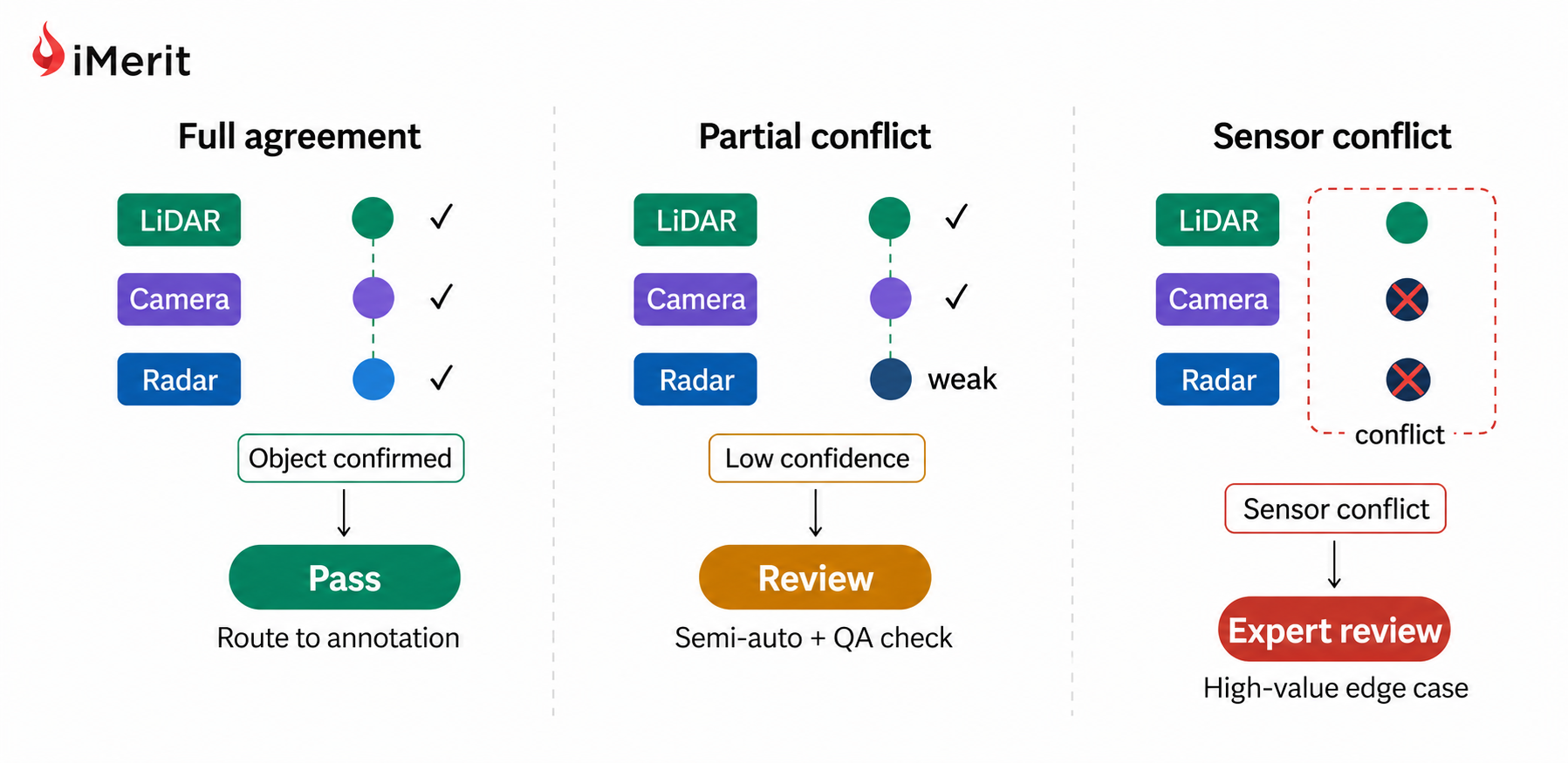
LiDAR, 카메라, 레이더 데이터의 시간 정렬을 보장하고 센서 간 충돌을 감지하는 다중 센서 퓨전 관리는 퓨전 알고리즘 개선에 필요한 고가치 데이터를 추출하는 핵심이다.
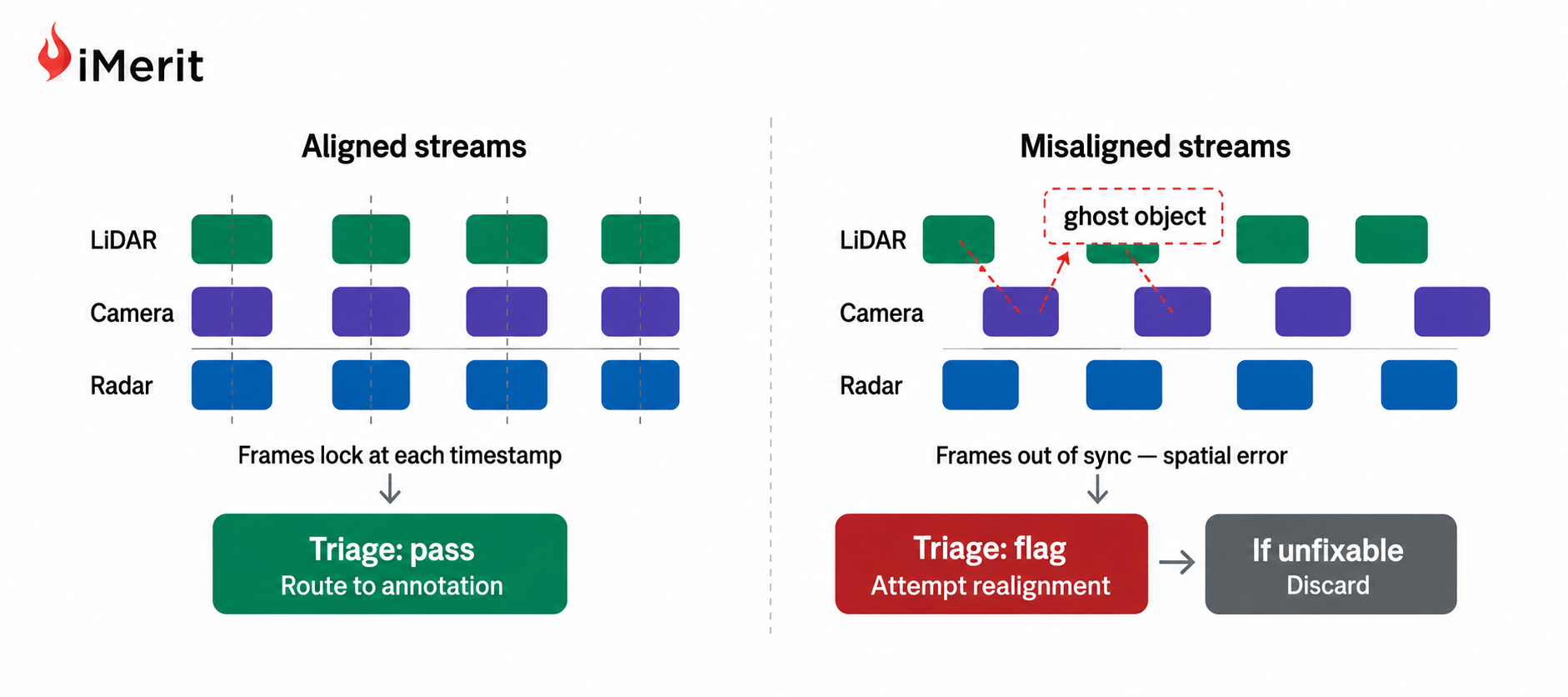
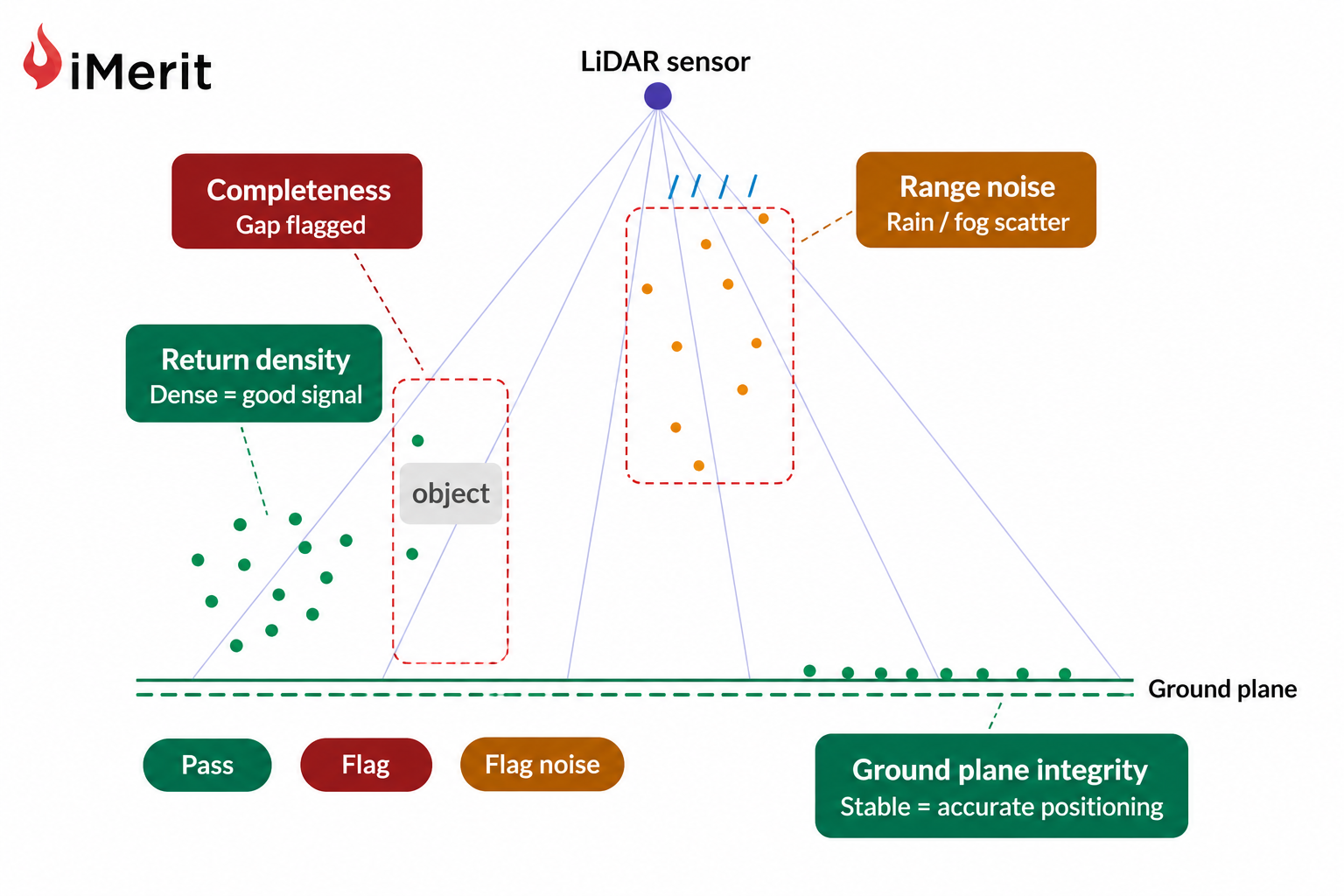
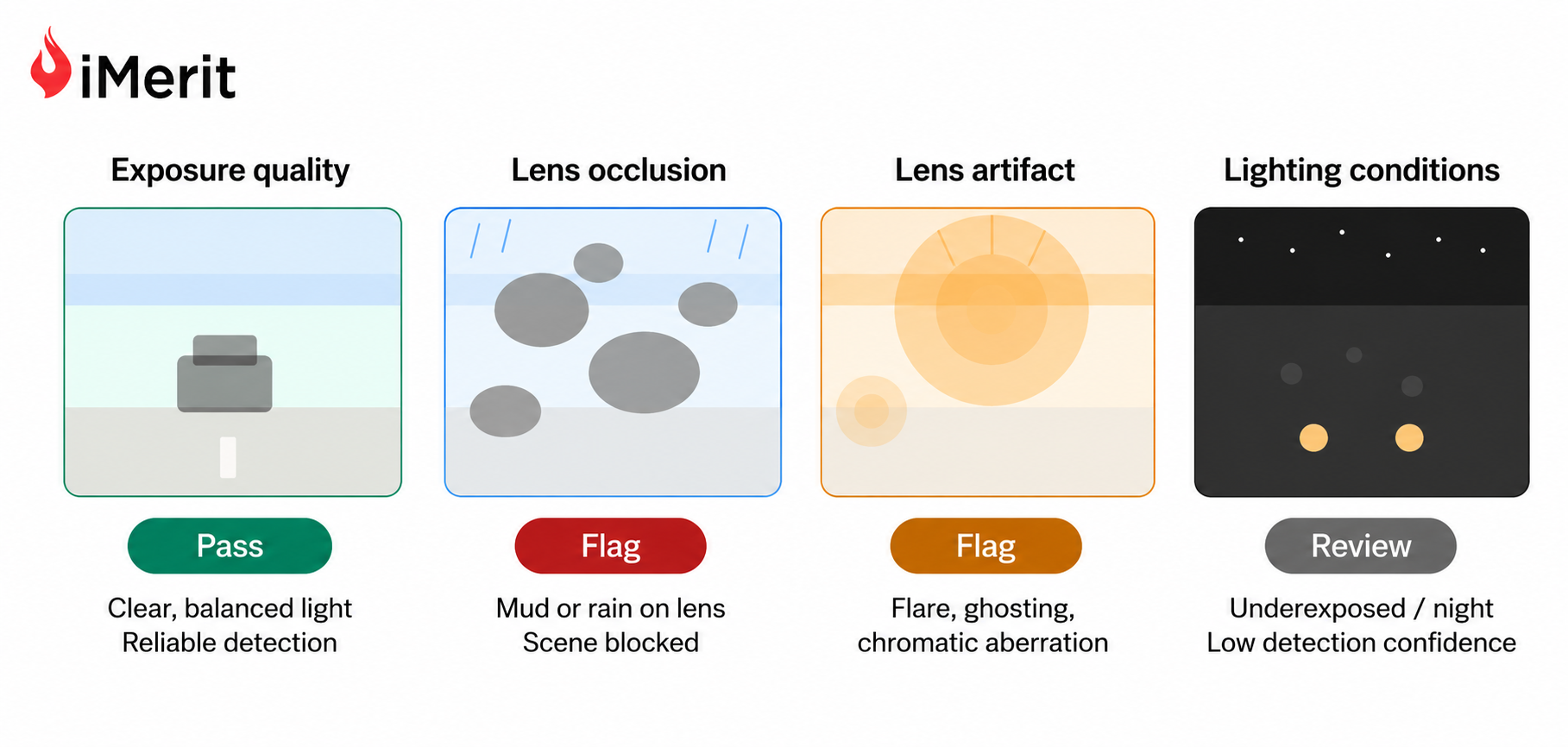
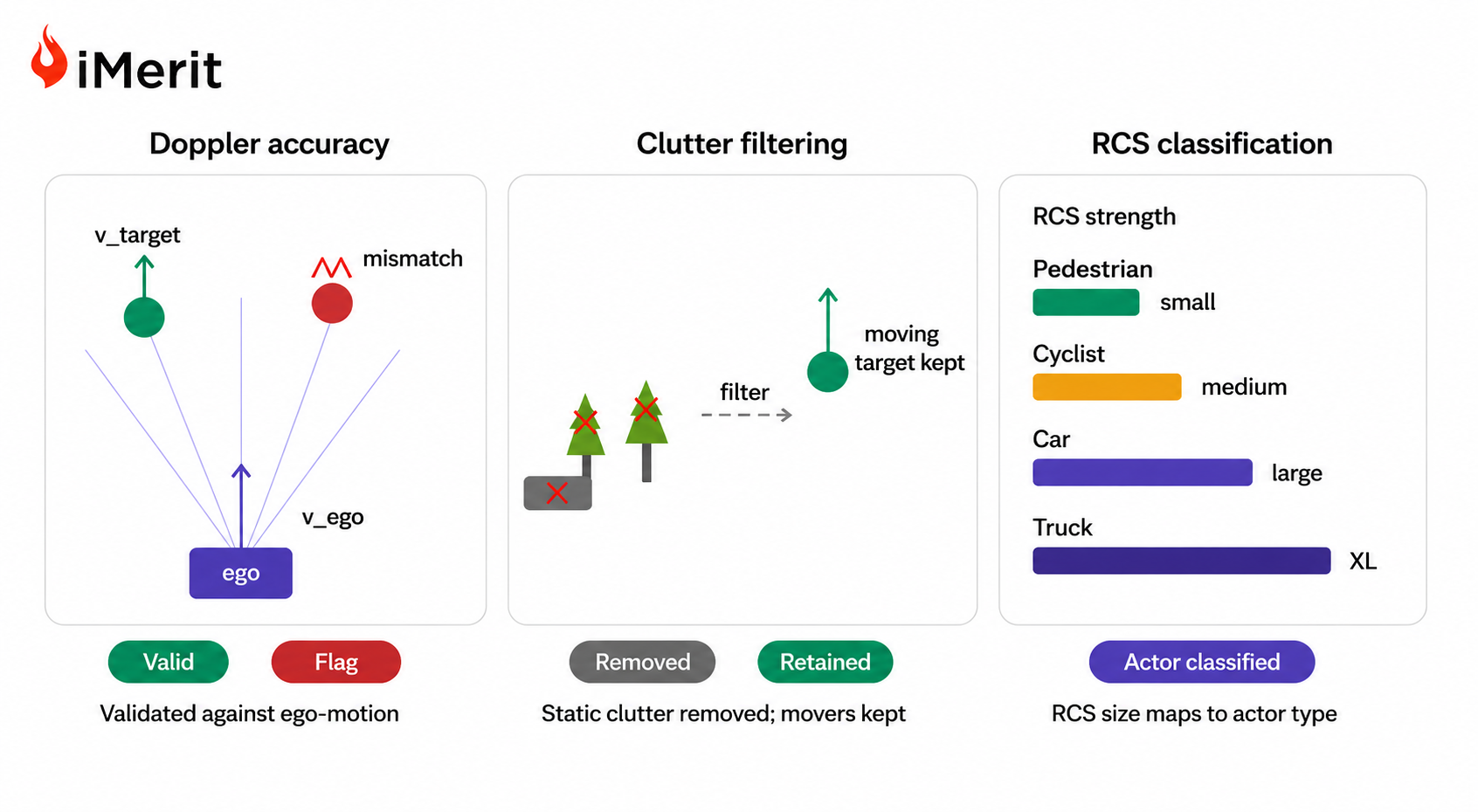
SOTIF 및 ISO 26262 표준을 활용한 시나리오 마이닝은 보호되지 않은 좌회전 등 희귀 시나리오를 자동 분류하고, 이를 향후 데이터 수집 계획에 반영하여 안전성을 강화한다.
용어 해설
- Sensor Data Triage
- — 자율주행차에서 수집된 방대한 센서 로그를 품질, 참신함, 학습 가치에 따라 평가하고 선별하는 과정입니다. 불필요한 데이터를 제거하고 모델 학습에 가장 효과적인 고가치 데이터를 우선적으로 라벨링하여 비용 효율성을 높입니다.
- Active Learning
- — 모델이 자신의 예측 불확실성을 기반으로 가장 학습이 필요한 데이터를 스스로 선택하는 기법입니다. 이 아티클에서는 모델의 불확실성 점수를 활용해 데이터 수집 및 트리아지 우선순위를 지속적으로 조정하는 데 사용됩니다.
- Sensor Fusion
- — LiDAR, 카메라, 레이더 등 서로 다른 센서에서 수집된 데이터를 통합하여 주변 환경을 정확하게 인식하는 기술입니다. 트리아지 과정에서 센서 간 시간 정렬과 일관성을 검증하는 것이 필수적입니다.
- SOTIF
- — Safety of the Intended Functionality의 약자로, ISO 21448 표준을 의미합니다. 자율주행 시스템에서 기능적 결함이 없더라도 발생할 수 있는 위험 상황을 관리하고 안전성을 확보하기 위한 기준입니다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 20.수집 2026. 05. 20.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.