이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
기존의 순차적 도구 호출 방식은 중간 결과가 컨텍스트 윈도우를 반복 통과하며 지연과 비용을 유발한다. PTC는 모델이 Python 코드를 작성하여 샌드박스 환경에서 도구를 병렬 실행하고 최종 결과만 반환받는 방식으로 이 문제를 해결한다. 테스트 결과 토큰 소비가 87-92% 감소하고 데이터 처리 정확도가 향상됨이 확인됐다. 이 글은 Amazon Bedrock에서 PTC를 구현하는 세 가지 방법인 ECS 기반 자가 호스팅, AgentCore 관리형 서비스, Anthropic SDK 프록시 방식을 설명한다.
배경
Amazon Bedrock 사용 경험, Python 프로그래밍, Docker 컨테이너 기초 지식
대상 독자
프로덕션 환경에서 LLM 도구 호출을 최적화하려는 개발자
의미 / 영향
PTC는 LLM의 도구 호출 효율성을 획기적으로 개선하여, 복잡한 데이터 처리나 대규모 RAG 시스템의 비용과 성능 문제를 해결하는 핵심 패턴이 될 것이다. 특히 모델의 추론 횟수를 최소화하여 대규모 프로덕션 서비스의 운영 비용을 크게 낮출 수 있다.
섹션별 상세
전통적인 도구 호출 방식은 각 단계마다 모델 추론이 필요하여 토큰 소비와 지연 시간이 누적되는 병목이 발생한다.
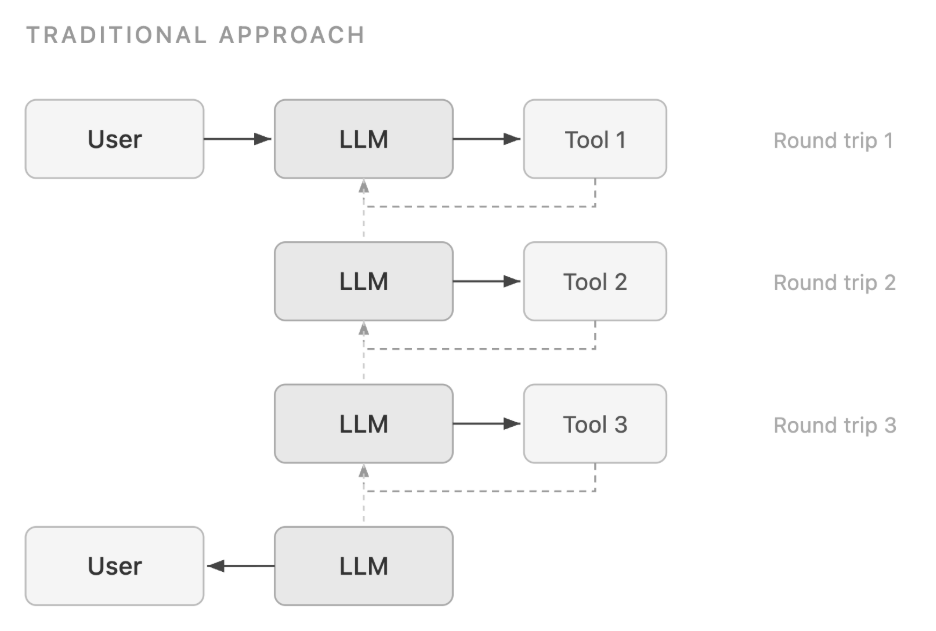
PTC는 모델이 Python 코드를 생성하고 샌드박스 환경에서 이를 실행하여, 중간 데이터를 컨텍스트에 포함하지 않고 최종 결과만 반환한다.
python
import asyncio
import json
# Step 1: Get team members
team_json = await get_team_members(department="engineering")
team = json.loads(team_json)
# Step 2: Fetch all expense records in parallel
expense_tasks = [ get_expenses(employee_id=m["id"], quarter="Q3") for m in team ]
expenses_results = await asyncio.gather(*expense_tasks)
# Step 3: Filter and check budgets
exceeded = []
for member, exp_json in zip(team, expenses_results):
expenses = json.loads(exp_json)
total_travel = sum( e["amount"] for e in expenses if e["category"] == "travel" and e["status"] == "approved" )
if total_travel > 5000:
budget_json = await get_custom_budget(user_id=member["id"])
budget = json.loads(budget_json)
limit = budget["budget_limit"]
if total_travel > limit:
exceeded.append({ "name": member["name"], "spent": total_travel, "limit": limit, "exceeded_by": total_travel - limit })
# Step 4: Only the summary enters the model's context
print(f"{len(exceeded)} members exceeded budget:")
print(json.dumps(exceeded, indent=2))PTC를 사용하여 도구 호출을 병렬로 처리하고 데이터를 필터링하는 Python 코드 예시
테스트 결과 PTC 적용 시 토큰 소비가 87-92% 감소했으며, 대규모 데이터 처리 시 자연어 기반 처리보다 정확도가 높게 나타났다.
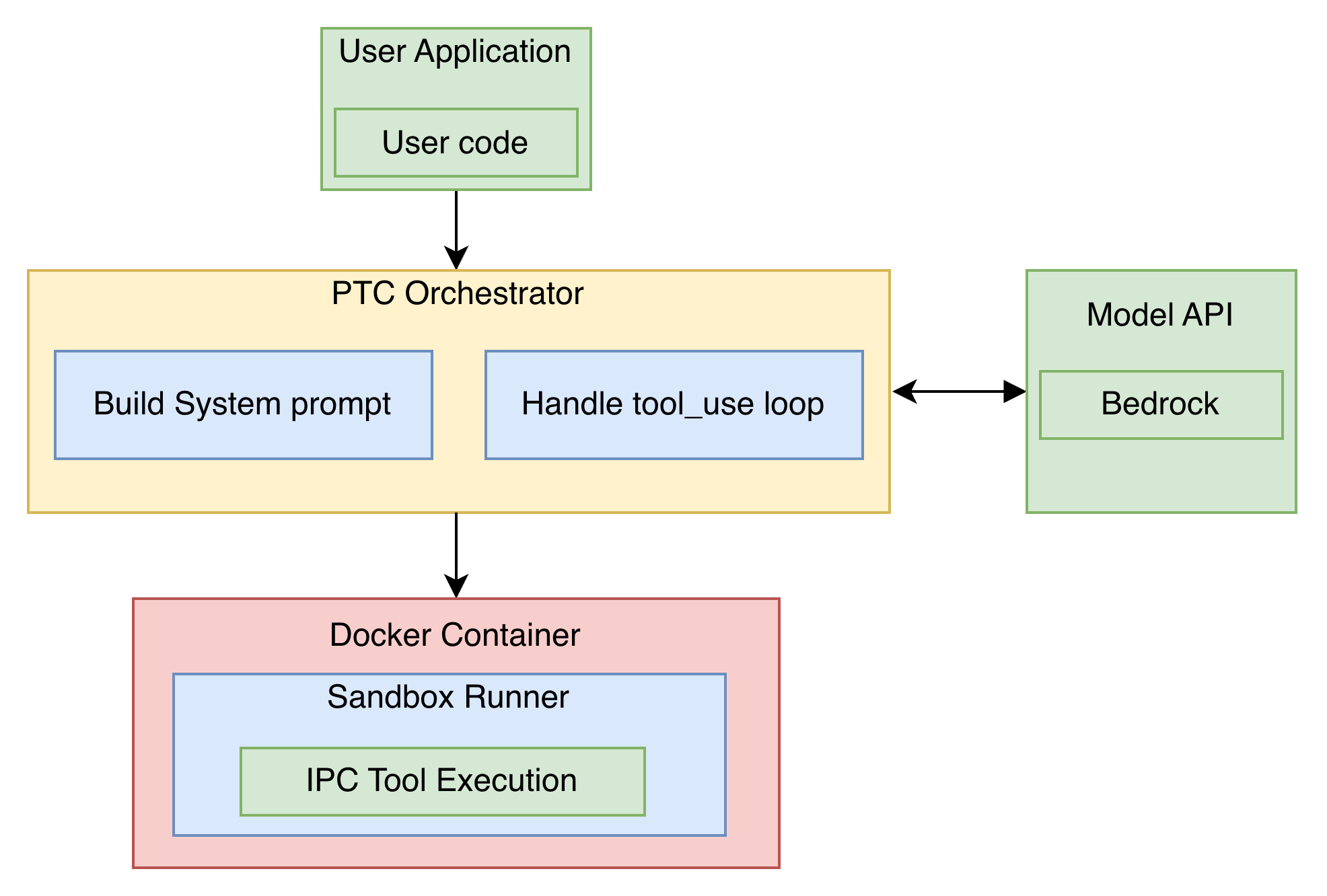
ECS 기반 자가 호스팅 방식은 Docker 샌드박스를 직접 제어하여 보안과 커스텀 패키지 설치에 유연성을 제공한다.
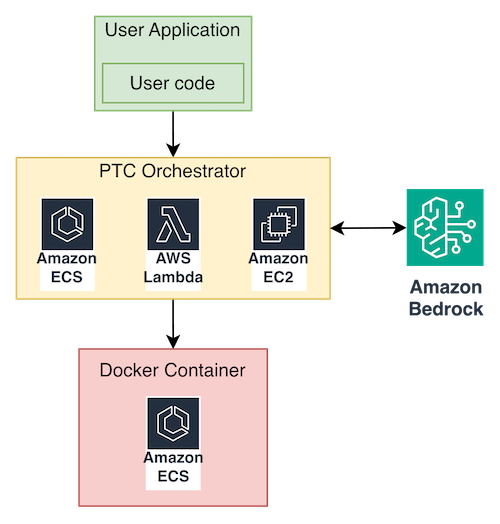
Amazon Bedrock AgentCore Code Interpreter는 인프라 관리 없이 PTC를 구현할 수 있는 관리형 환경을 제공한다.
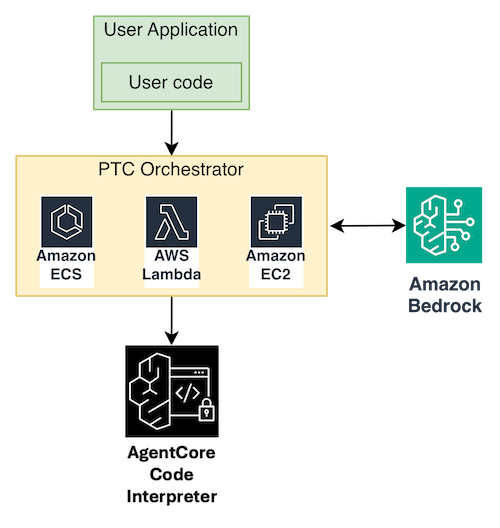
Anthropic SDK 호환 프록시를 사용하면 기존 SDK 경험을 유지하면서 Amazon Bedrock의 모델과 PTC 기능을 활용할 수 있다.
용어 해설
- PTC
- — LLM이 도구를 하나씩 호출하는 대신 Python 코드를 작성하여 샌드박스 환경에서 병렬로 실행하는 방식이다. 중간 결과를 컨텍스트에 포함하지 않고 최종 결과만 반환하여 토큰 소비와 지연 시간을 줄인다.
- Context Window
- — 모델이 한 번에 처리할 수 있는 입력 토큰의 최대 범위다. PTC는 불필요한 중간 데이터를 이 윈도우에서 제외하여 효율성을 높인다.
- Sandbox
- — 외부 코드나 프로세스를 안전하게 실행하기 위해 격리된 컴퓨팅 환경이다. 모델이 생성한 코드를 안전하게 실행하는 데 필수적이다.
- IPC
- — 서로 다른 프로세스 간에 데이터를 주고받는 메커니즘이다. PTC에서 오케스트레이터와 샌드박스 컨테이너가 통신하는 데 사용된다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 20.수집 2026. 05. 20.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.