이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
LLM 프로덕션 환경에서 프롬프트 캐싱은 비용 관리에 필수적이나, 최적의 TTL 설정은 워크로드마다 달라 수동 관리가 어렵다. Firetiger는 자체 AI 에이전트인 'Prompt Cache Advisor'를 도입하여 텔레메트리 데이터를 분석하고 배포별 최적 TTL을 제안하는 자동화 루프를 구축했다. 이 에이전트는 캐시 읽기/쓰기 비율을 계산해 비용 효율적인 설정을 도출하고, 코드 변경 사항을 제안하여 인간의 검토 후 적용한다. 이 방식을 통해 불필요한 캐시 쓰기 비용을 77% 절감했으며, 지속적인 최적화가 이루어지고 있다.
배경
LLM 프롬프트 캐싱에 대한 기본 이해, 텔레메트리 데이터 수집 환경
대상 독자
프로덕션 환경에서 LLM을 운영하며 비용 최적화가 필요한 개발자
의미 / 영향
AI 에이전트를 활용한 인프라 최적화는 사람이 수동으로 관리하기 어려운 복잡한 파라미터 튜닝을 자동화하여 운영 효율을 극대화할 수 있음을 보여준다. 특히 LLM 비용 구조가 복잡해짐에 따라 이러한 자동화된 비용 관리 도구의 중요성이 커지고 있다.
섹션별 상세
프롬프트 캐싱은 동일한 prefix를 재사용해 추론 비용을 낮추지만, TTL 설정이 부적절하면 오히려 캐시 쓰기 비용이 읽기 절감액을 초과하는 낭비가 발생한다.
Prompt Cache Advisor는 배포, 에이전트, 모델별로 토큰 사용량과 읽기/쓰기 비율을 분석하여 가장 경제적인 TTL을 산출한다.
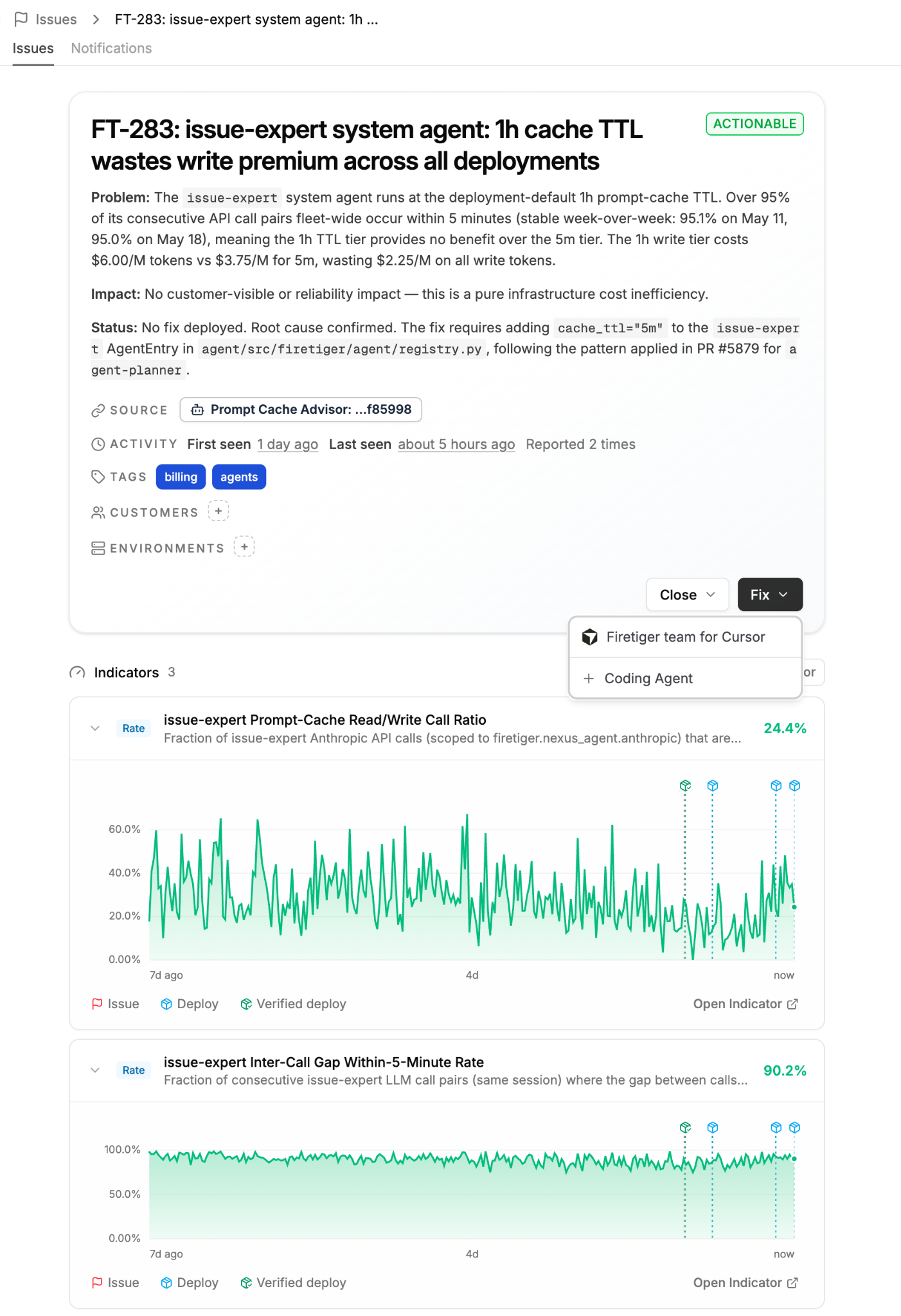

단순히 모든 설정을 1시간으로 고정하는 방식보다 에이전트가 제안하는 세밀한 설정이 비용 효율성 측면에서 우월하다.
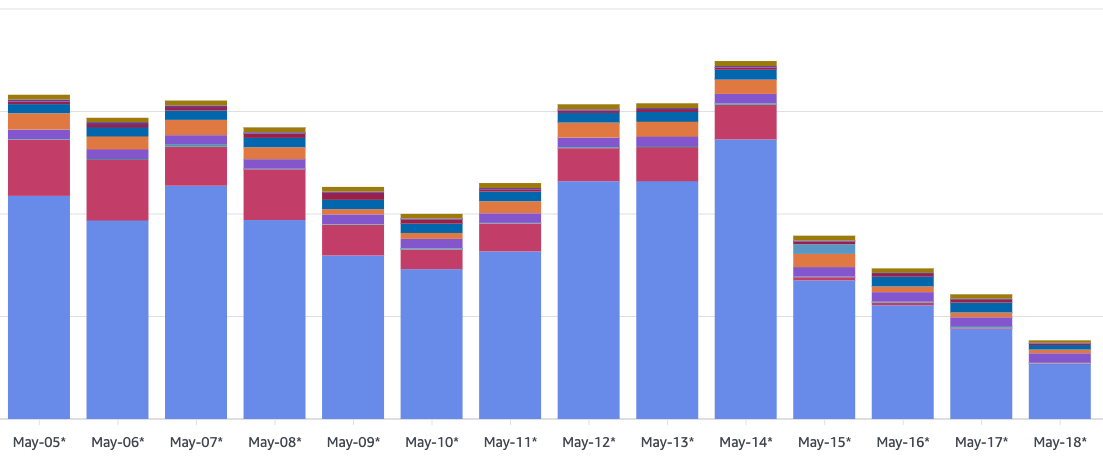
비결정적 시스템 프롬프트(Go 맵 순서 문제 등)와 같은 기술적 병목을 에이전트가 식별하여 수정함으로써 캐시 적중률을 실질적으로 개선했다.
go
for name, tool := range agentTools { fmt.Fprintf(&systemPrompt, “- %s: %s
”, name, tool.Description, ) }Go 맵 순서의 비결정성으로 인해 시스템 프롬프트가 매번 달라져 캐시 미스가 발생하는 코드 예시
용어 해설
- Prompt Caching
- — LLM 입력의 반복되는 prefix를 캐시에 저장하여 재사용함으로써 API 비용과 지연 시간을 줄이는 기술. 동일한 prefix를 가진 후속 요청은 전체 입력을 다시 처리하지 않고 캐시된 결과를 읽어 비용을 절감함.
- TTL
- — 캐시된 데이터가 유효한 시간. 이 시간이 지나면 캐시가 만료되어 원본 서버에서 데이터를 다시 가져와야 함. LLM 프롬프트 캐싱에서는 캐시된 prefix를 얼마나 오래 유지할지 결정하는 핵심 설정값임.
- Telemetry
- — 시스템의 성능, 비용, 사용량 데이터를 원격으로 수집하여 분석하는 기술. LLM 프로덕션 환경에서는 토큰 사용량, 캐시 적중률, 비용 등을 추적하여 최적화의 근거로 활용함.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 20.수집 2026. 05. 20.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.