이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
PopuLoRA는 LLM의 추론 능력을 강화하기 위해 교사(Teacher)와 학생(Student)으로 구성된 두 개의 LoRA 어댑터 집단을 공동 진화시키는 비대칭 자기 대결(Asymmetric Self-Play) 프레임워크이다. 기존 단일 에이전트 자기 대결이 쉬운 작업으로 수렴하는 커리큘럼 붕괴 문제를 해결하기 위해, 교사는 학생이 해결하기 어려운 검증 가능한 작업을 생성하고 학생은 이를 해결하며 보상을 얻는다. TrueSkill 기반의 매칭과 LoRA 가중치 공간에서의 진화 연산자를 통해 학습 과정 내내 난이도가 조절되는 자동 커리큘럼을 형성한다. 실험 결과, HumanEval+, MBPP+, AIME 등 코드 및 수학 벤치마크에서 기존 단일 에이전트 방식보다 우수한 성능을 입증했다.
배경
강화학습(RL) 기초 지식, LoRA 및 어댑터 기반 학습 이해, TrueSkill 등 순위 시스템 개념
대상 독자
LLM 파인튜닝 및 강화학습 연구자 및 엔지니어
의미 / 영향
이 연구는 자기 대결 학습에서 발생하는 커리큘럼 붕괴 문제를 해결하는 실용적인 프레임워크를 제시한다. 특히 LoRA 기반의 효율적인 다중 집단 학습 방식은 자원이 제한된 환경에서도 고성능 추론 모델을 학습시킬 수 있는 경로를 제공한다.
섹션별 상세
단일 에이전트 자기 대결의 한계는 모델이 스스로 작업을 생성하고 해결하는 과정에서 이미 해결 가능한 쉬운 작업에만 집중하게 되어 학습 정체(커리큘럼 붕괴)가 발생한다는 점이다.
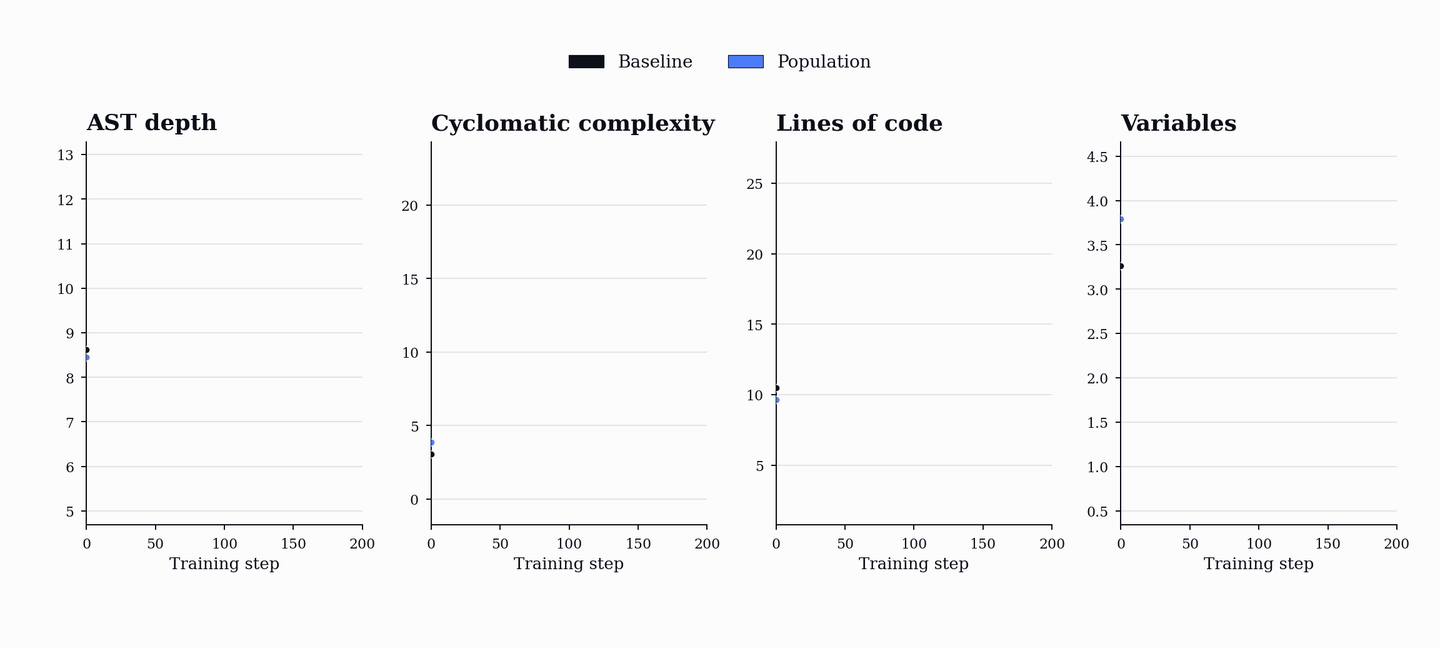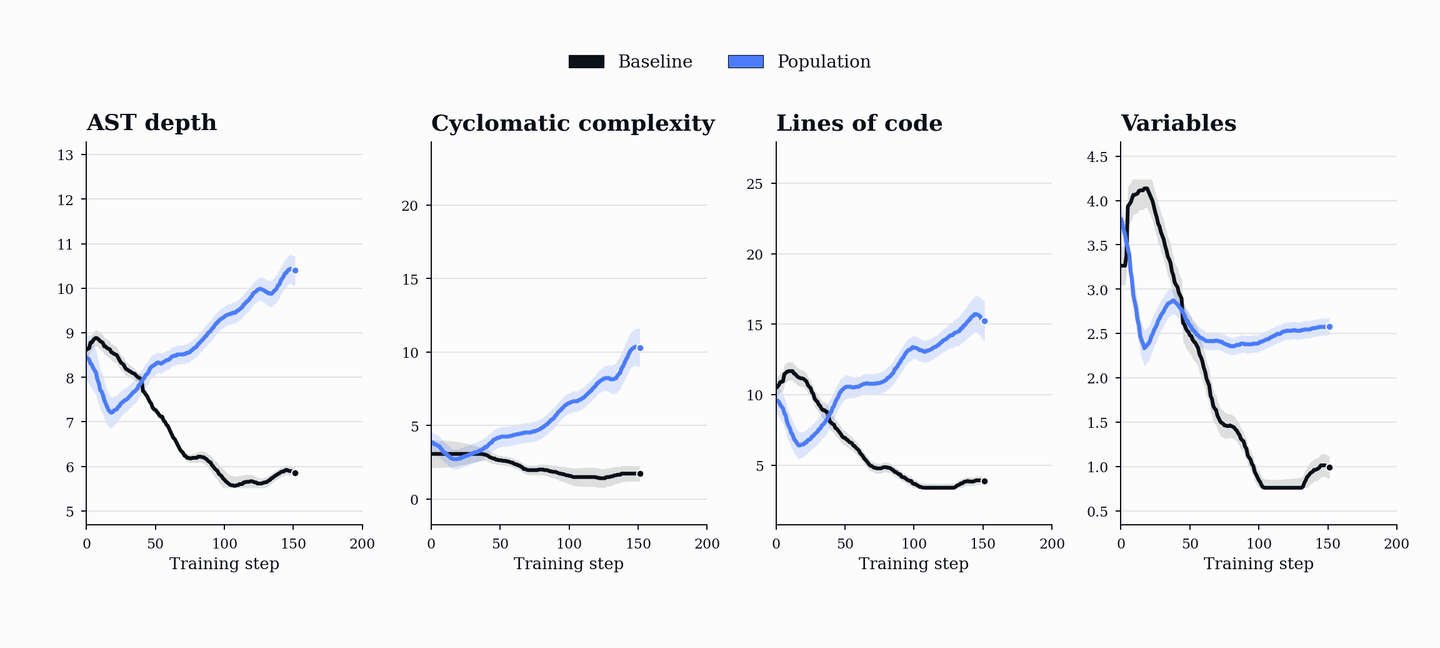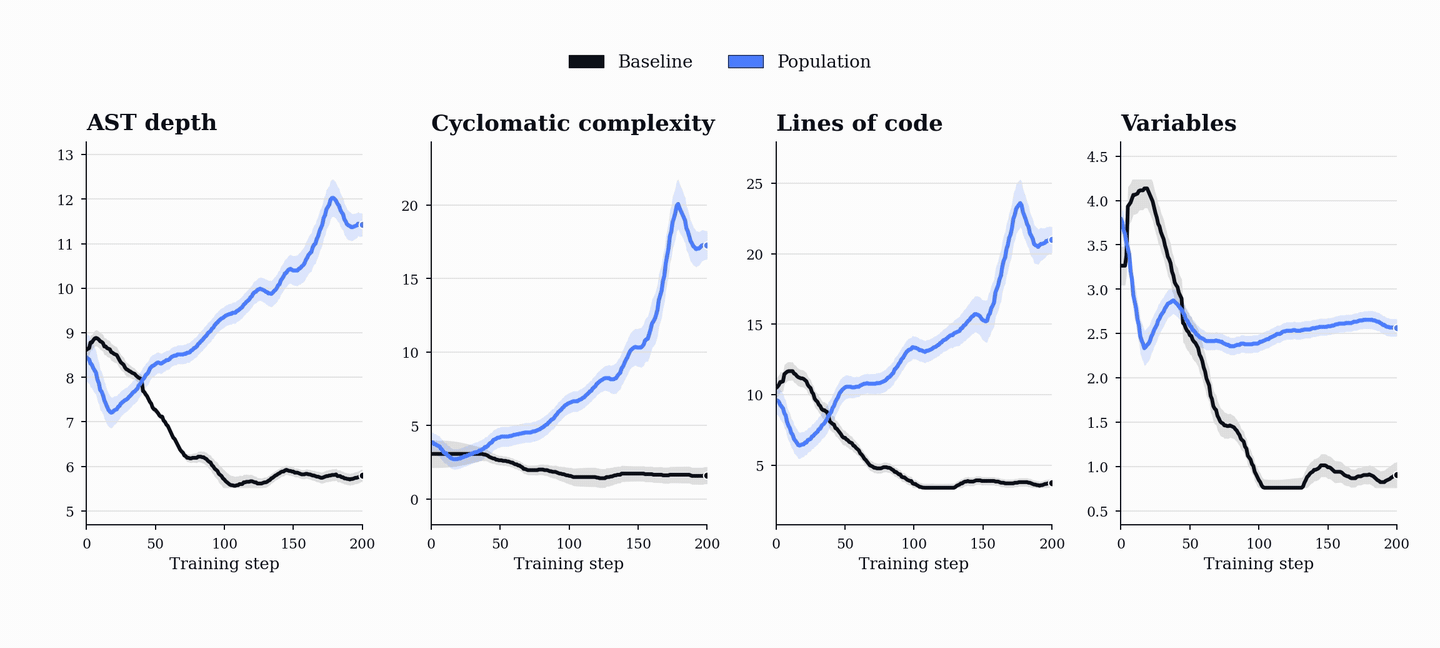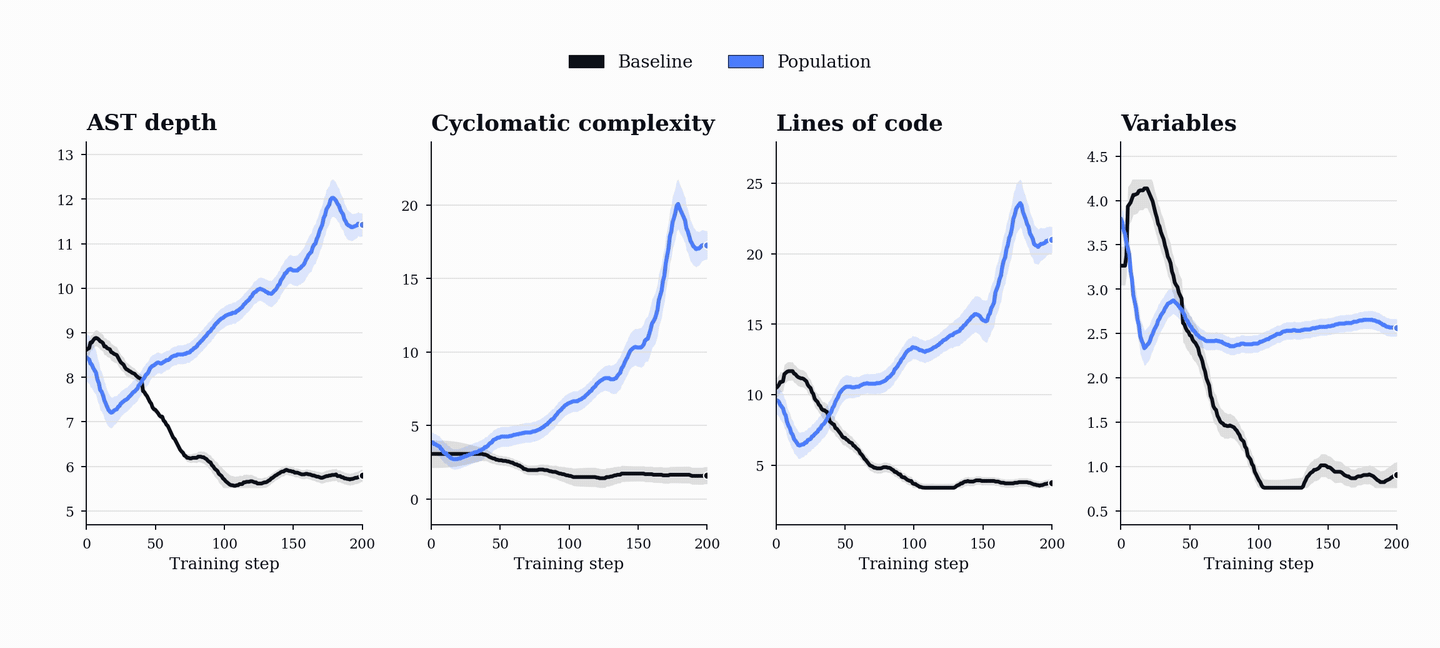
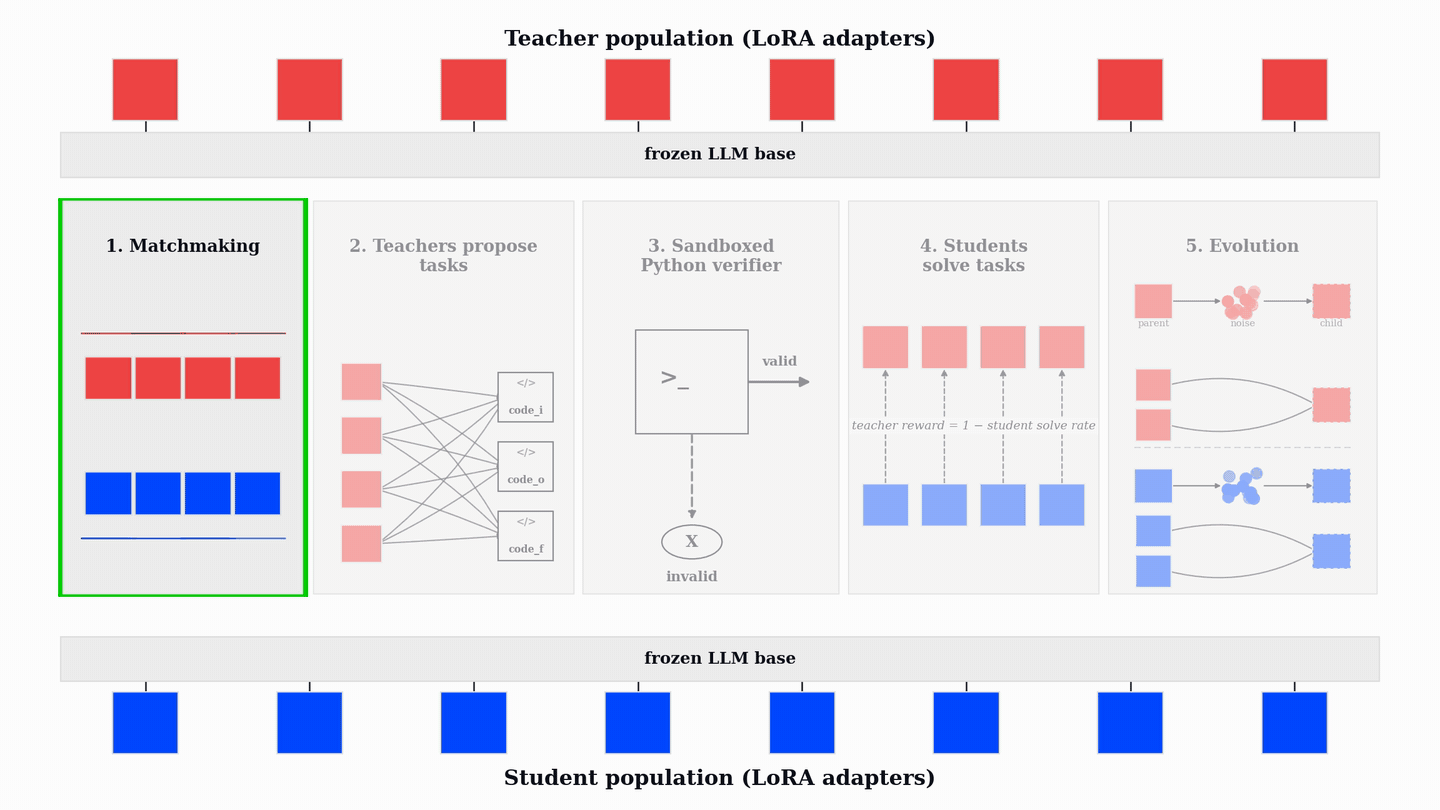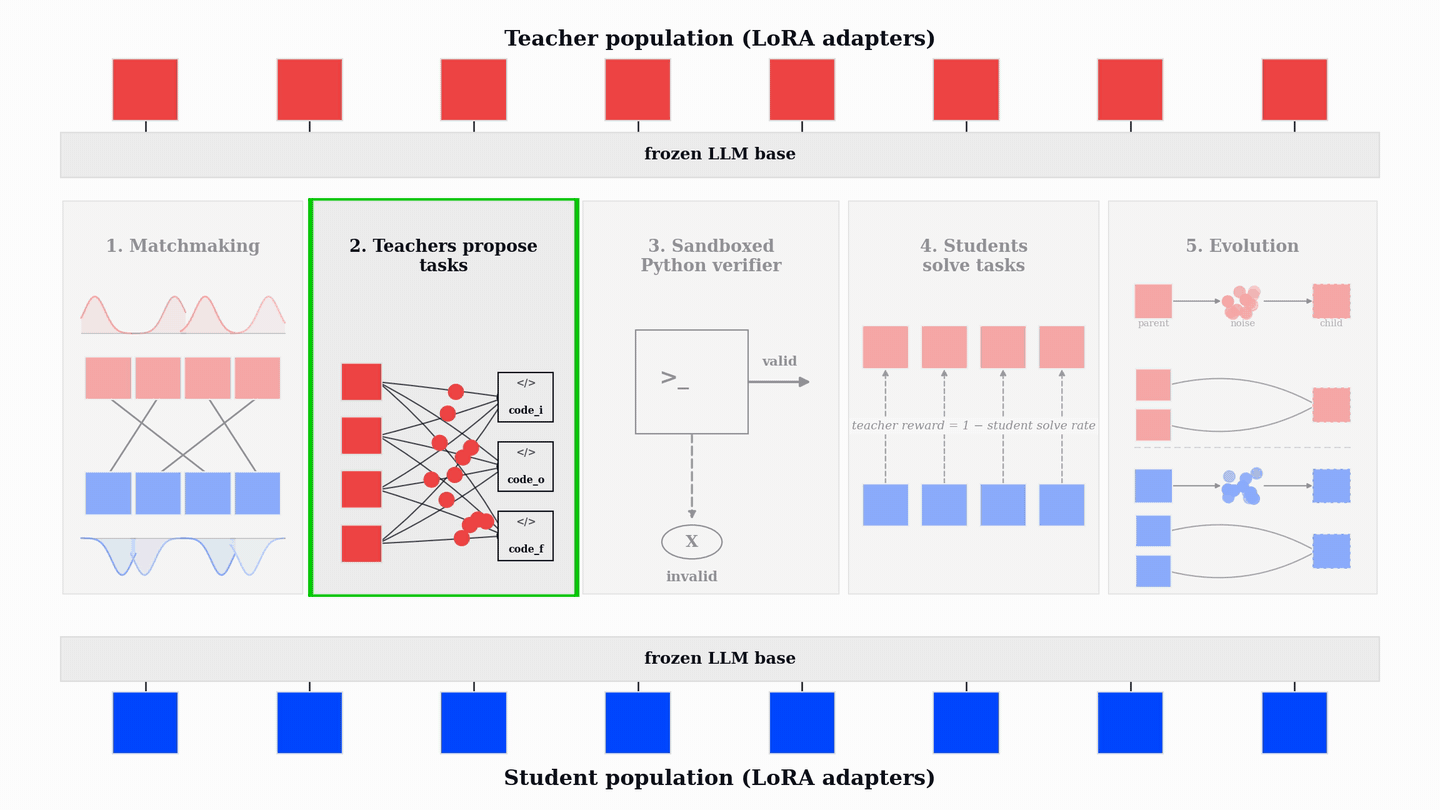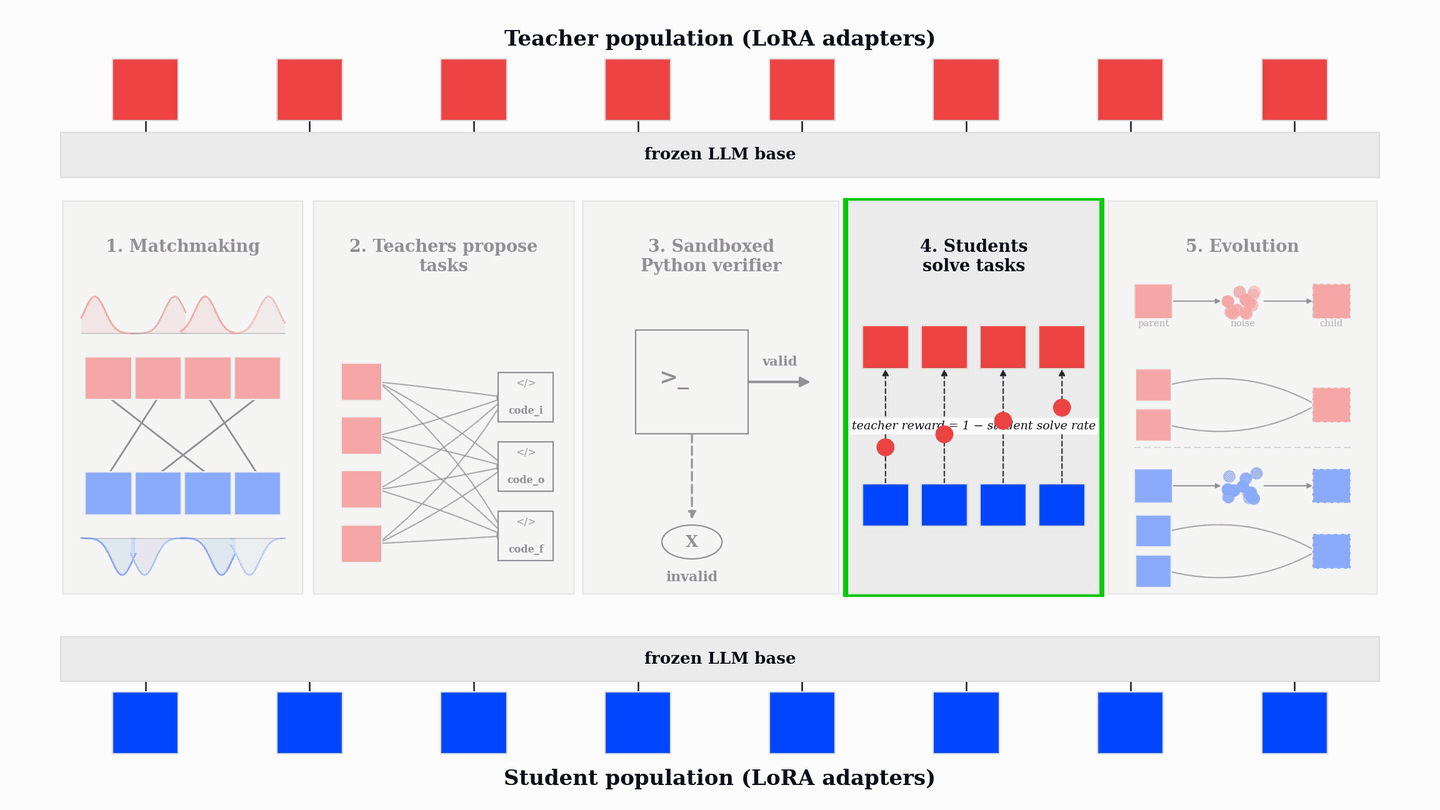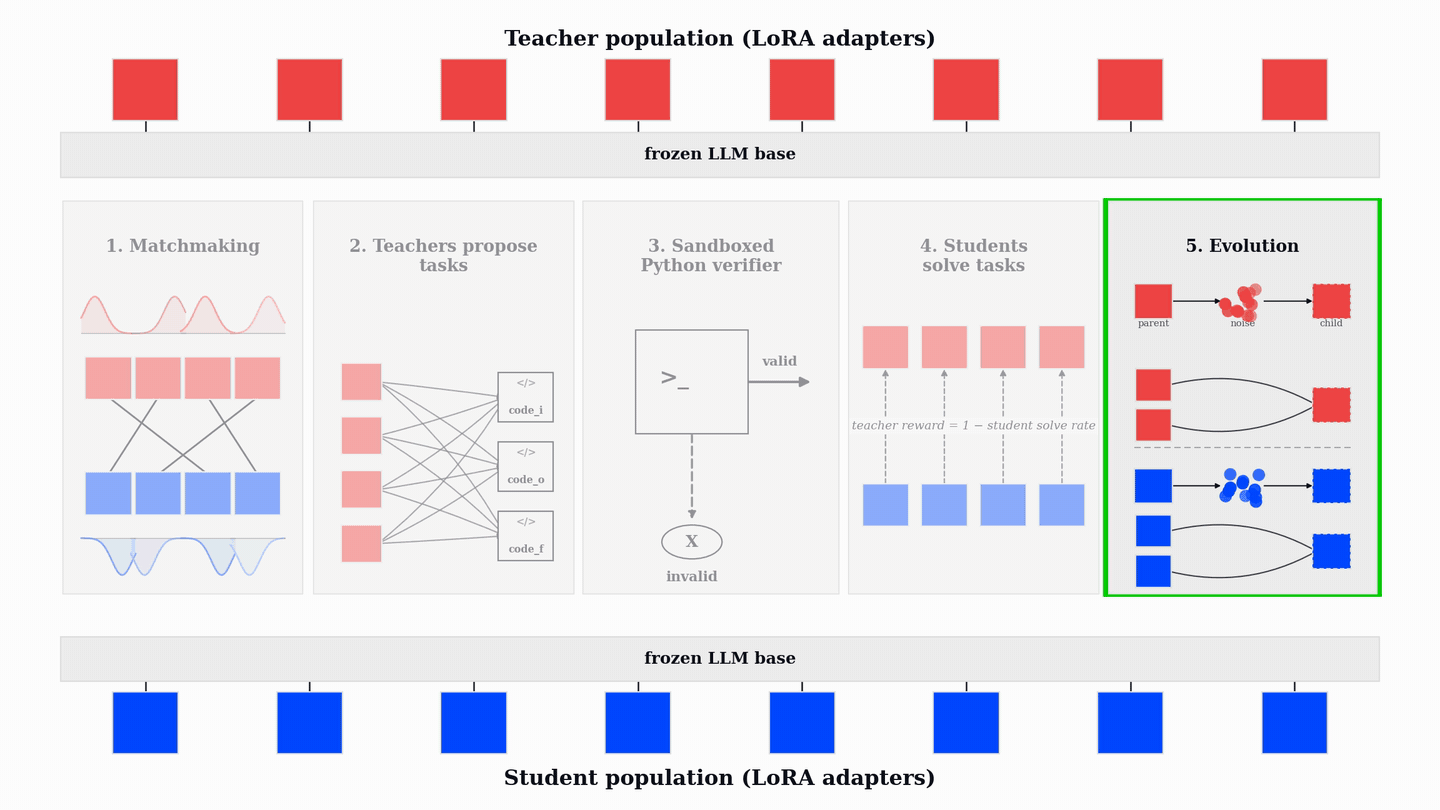
PopuLoRA의 비대칭 구조는 교사(Teacher)와 학생(Student) 어댑터를 분리하여 교사는 학생이 실패할 만한 난이도의 작업을 생성하고, 학생은 이를 해결하도록 유도하여 상호 경쟁적인 학습 환경을 조성한다.
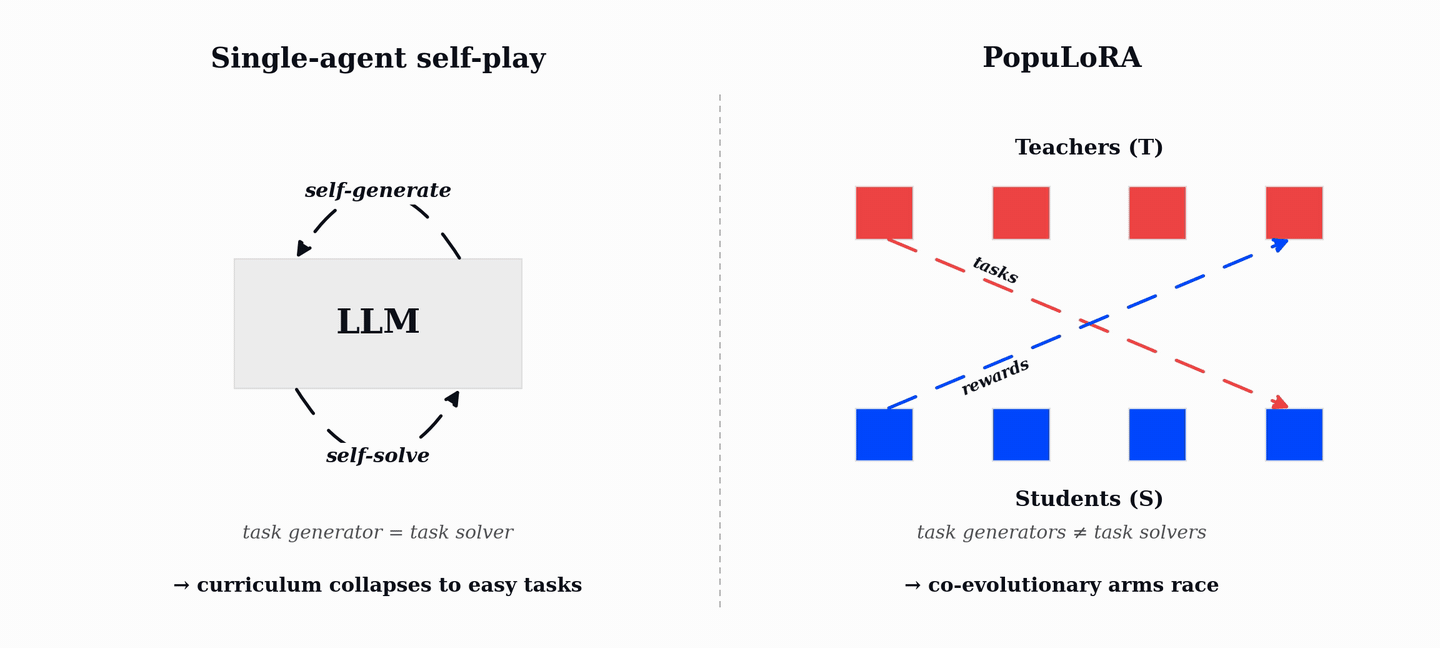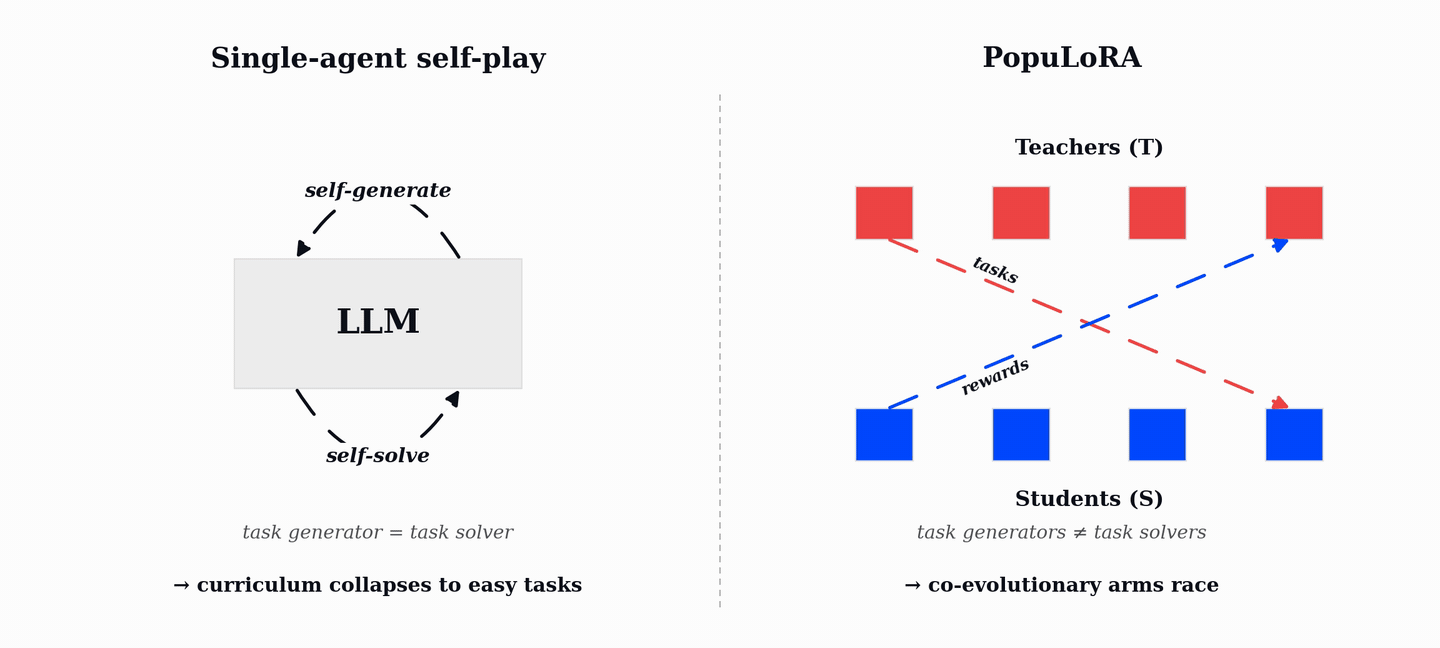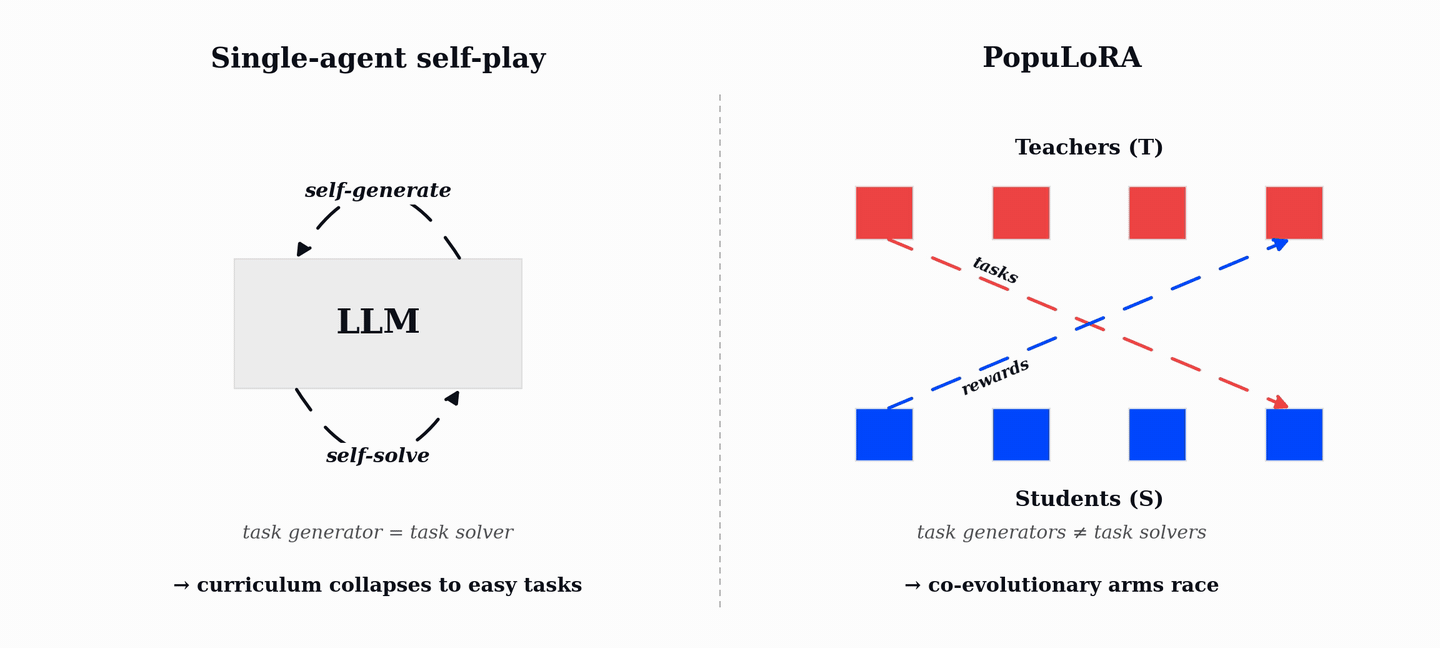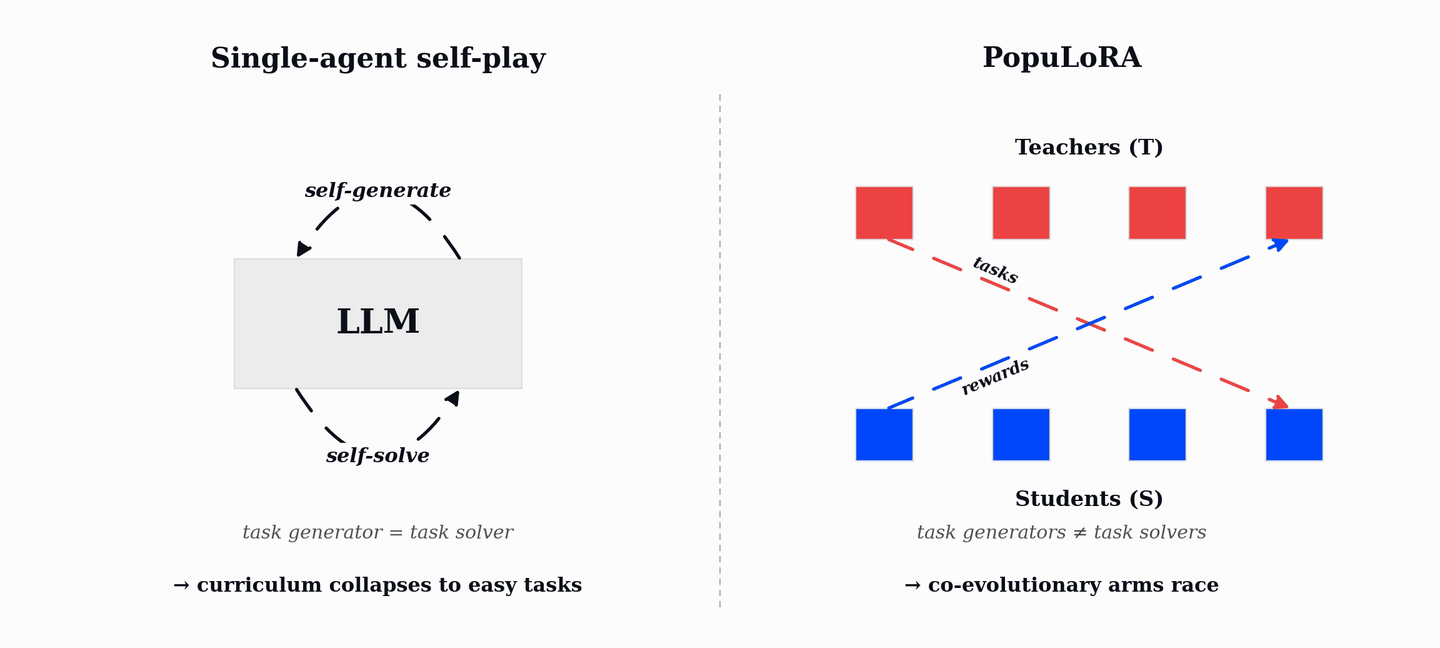
효율적인 구현은 전체 모델을 복제하지 않고 LoRA 어댑터만 여러 개 학습시켜 단일 머신에서도 다중 집단 학습이 가능하며, 4T+4S 설정 시 1.31배의 오버헤드만 발생한다.
근거
- 4T+4S 설정 시 8개의 어댑터를 학습하는 데 1.31배의 오버헤드만 발생한다. — The Training Loop 섹션
진화적 학습은 TrueSkill 점수를 기반으로 매칭하고, 성능이 낮은 어댑터를 가중치 공간에서 변이 및 교차 연산을 통해 새로운 어댑터로 대체하여 학습 효율을 유지한다.
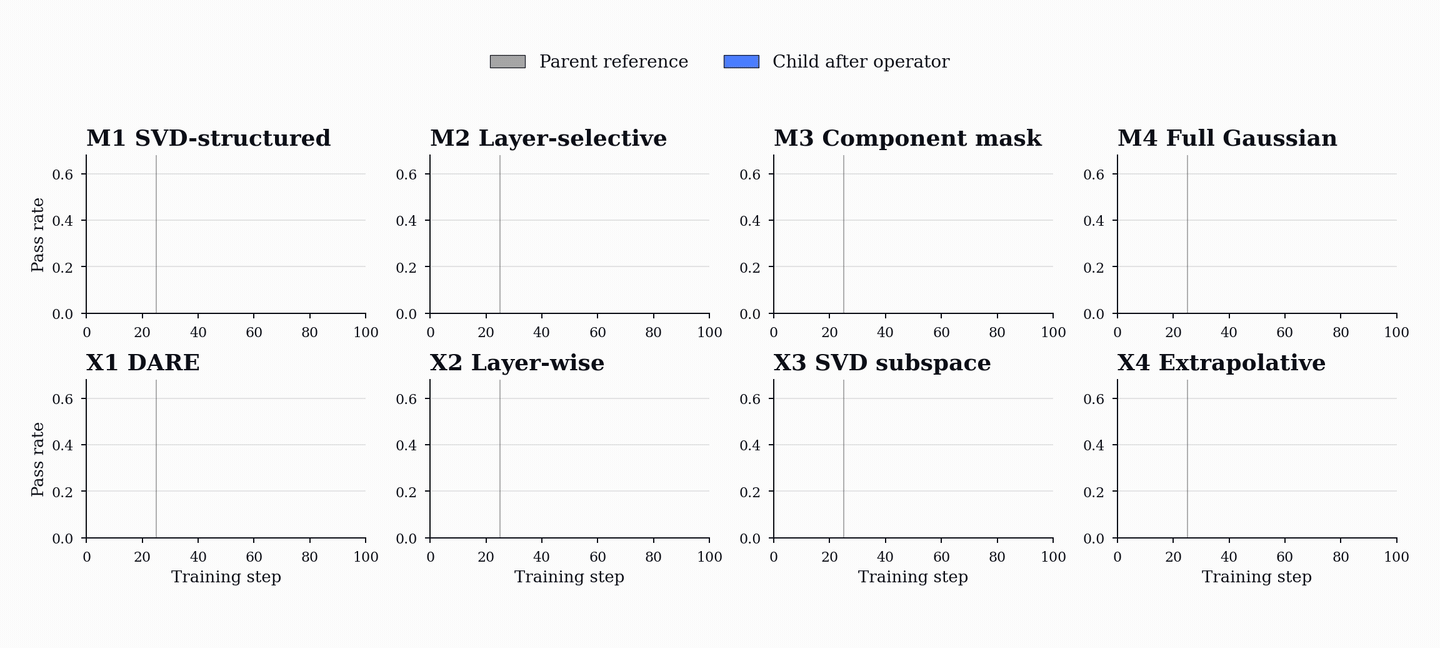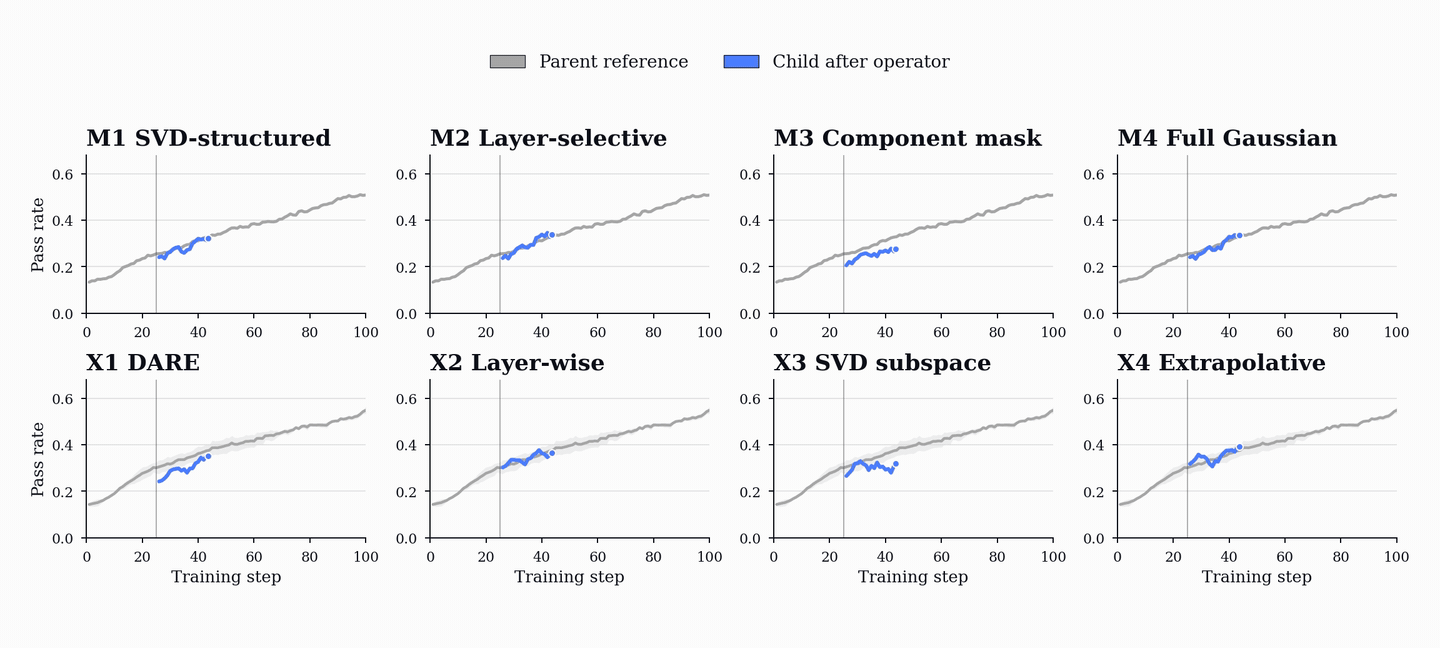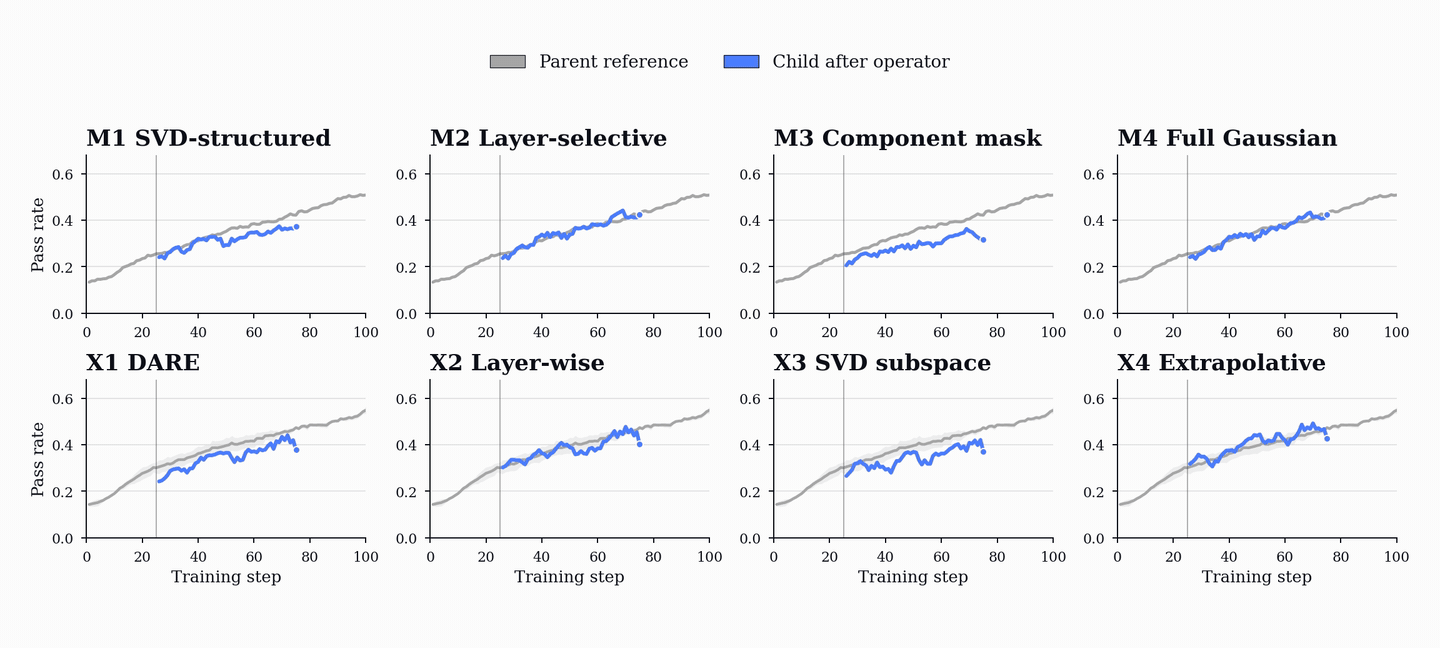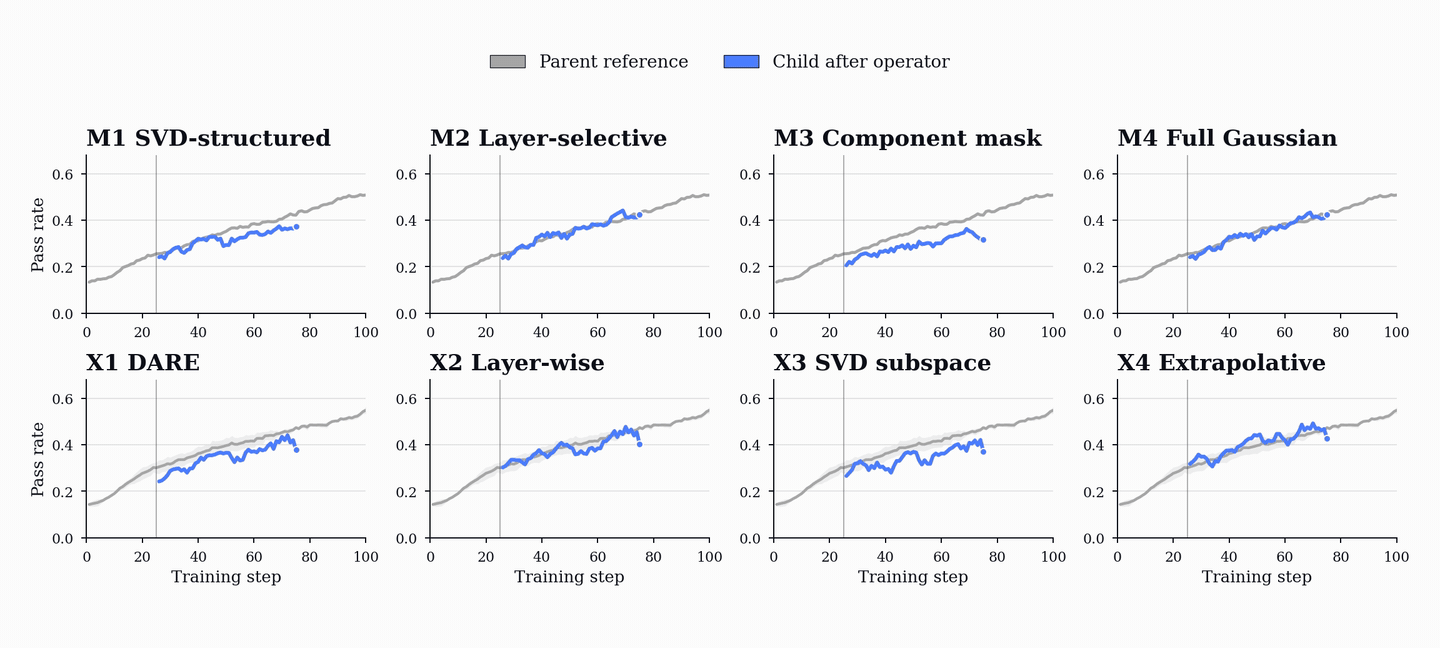
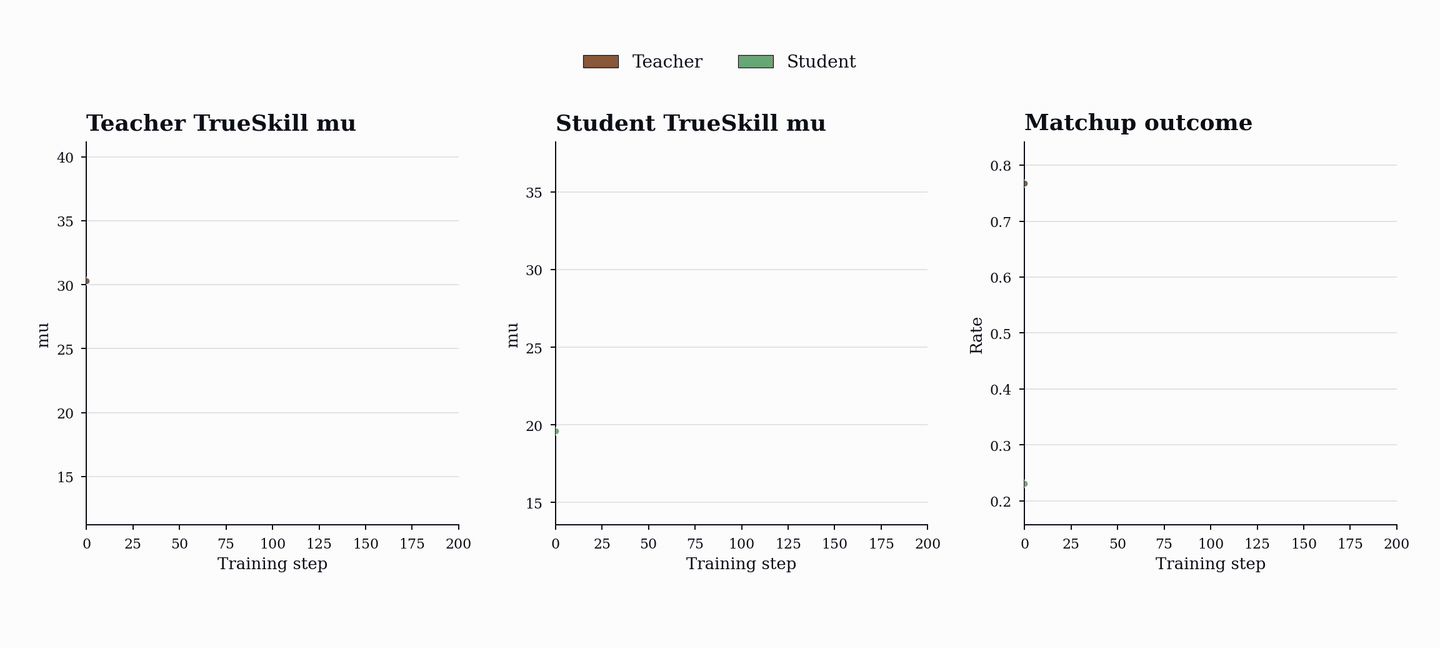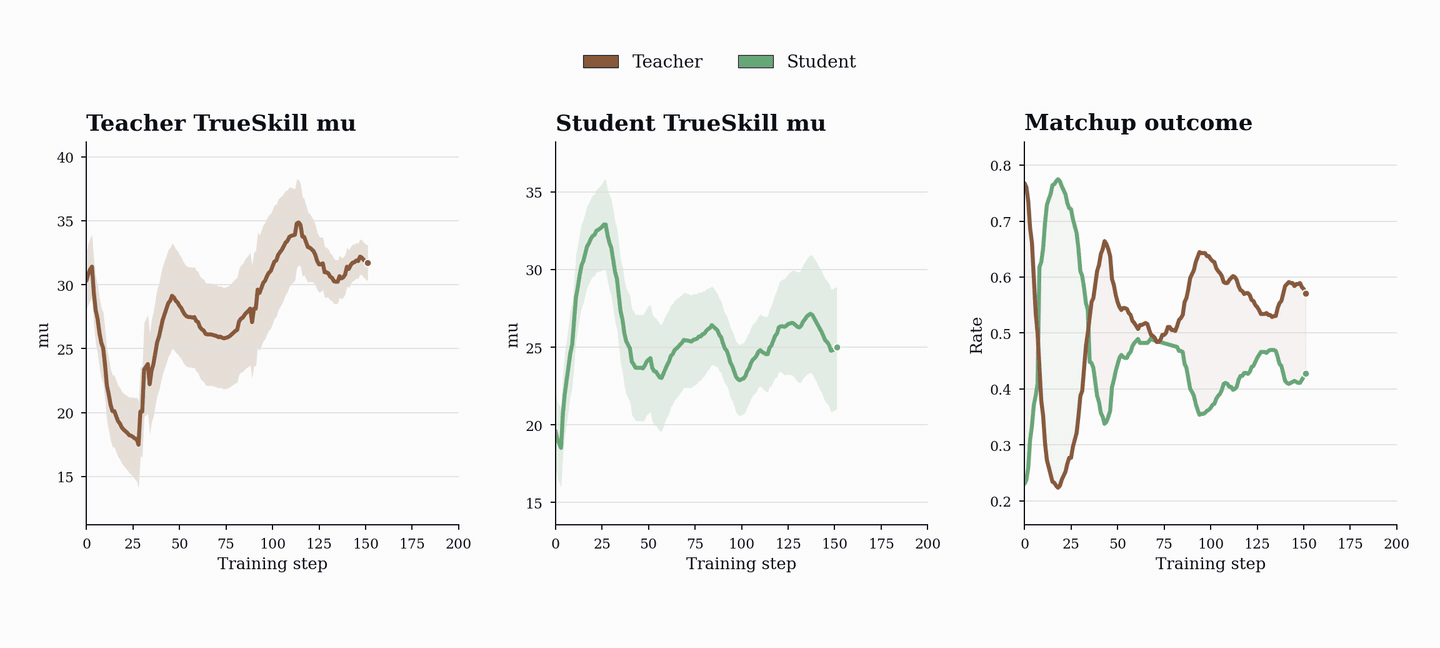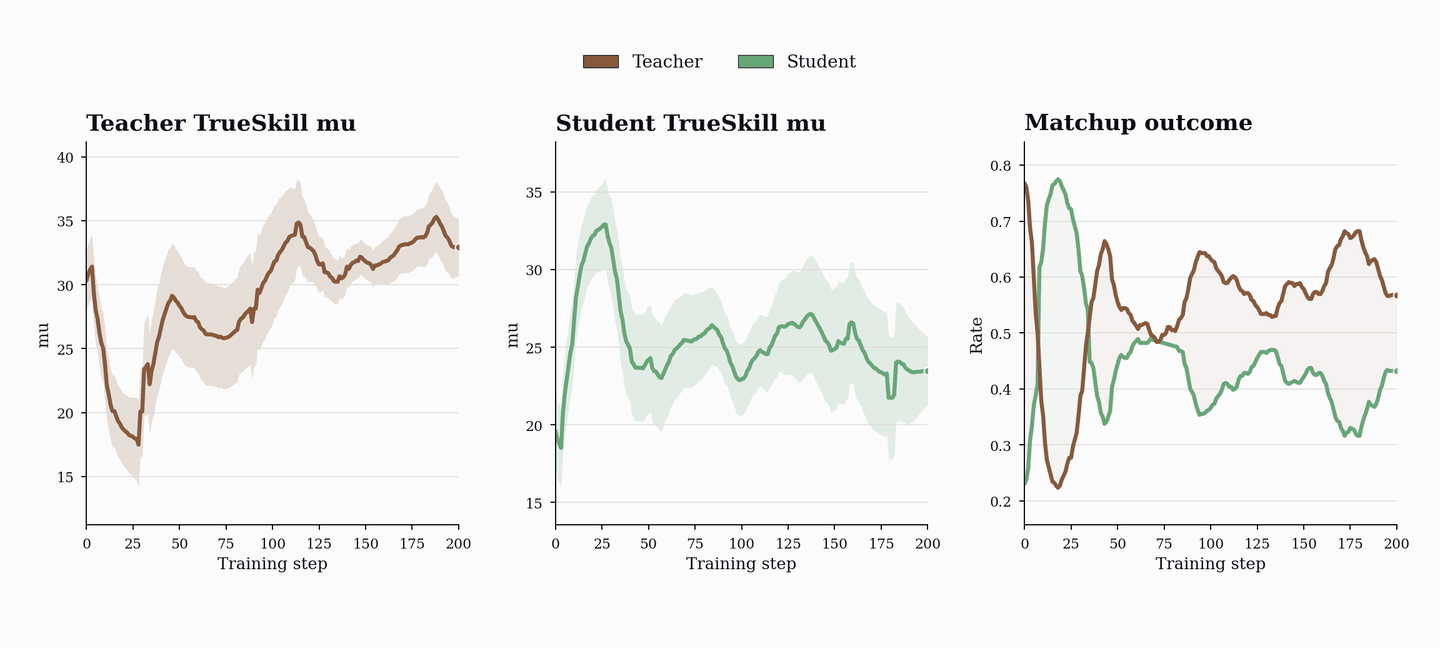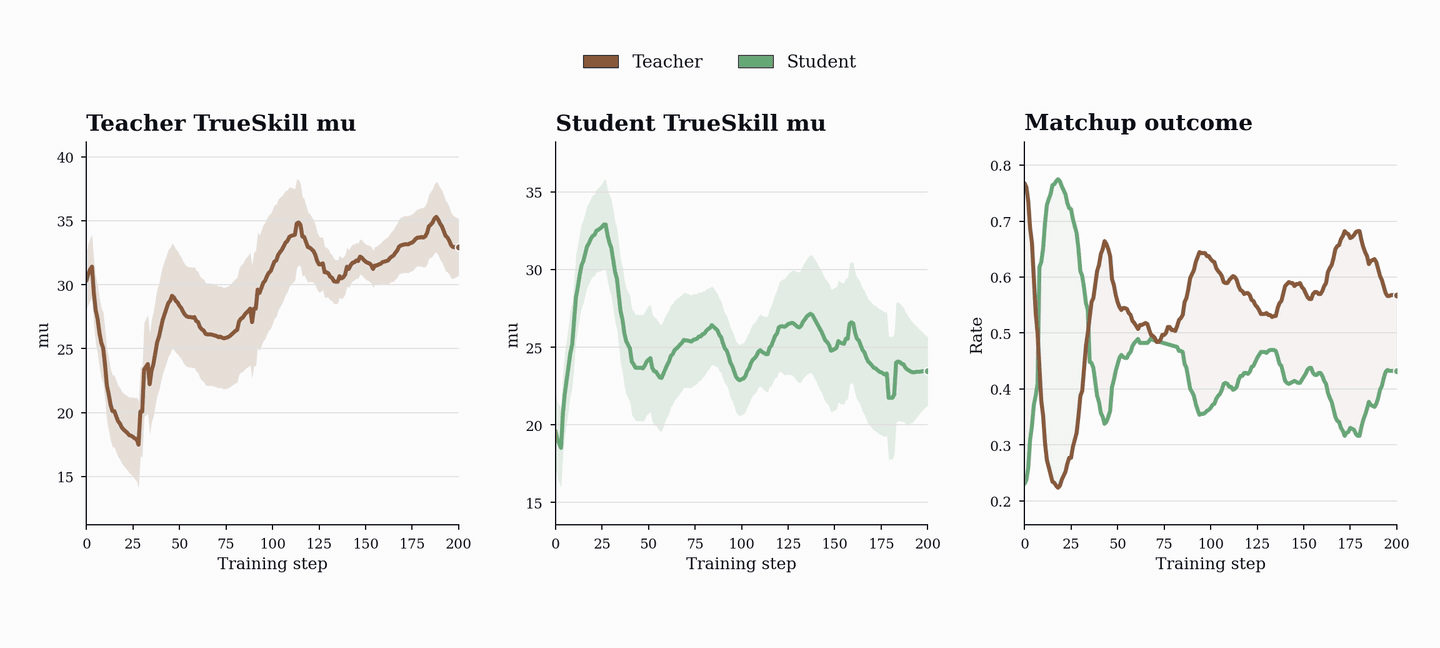
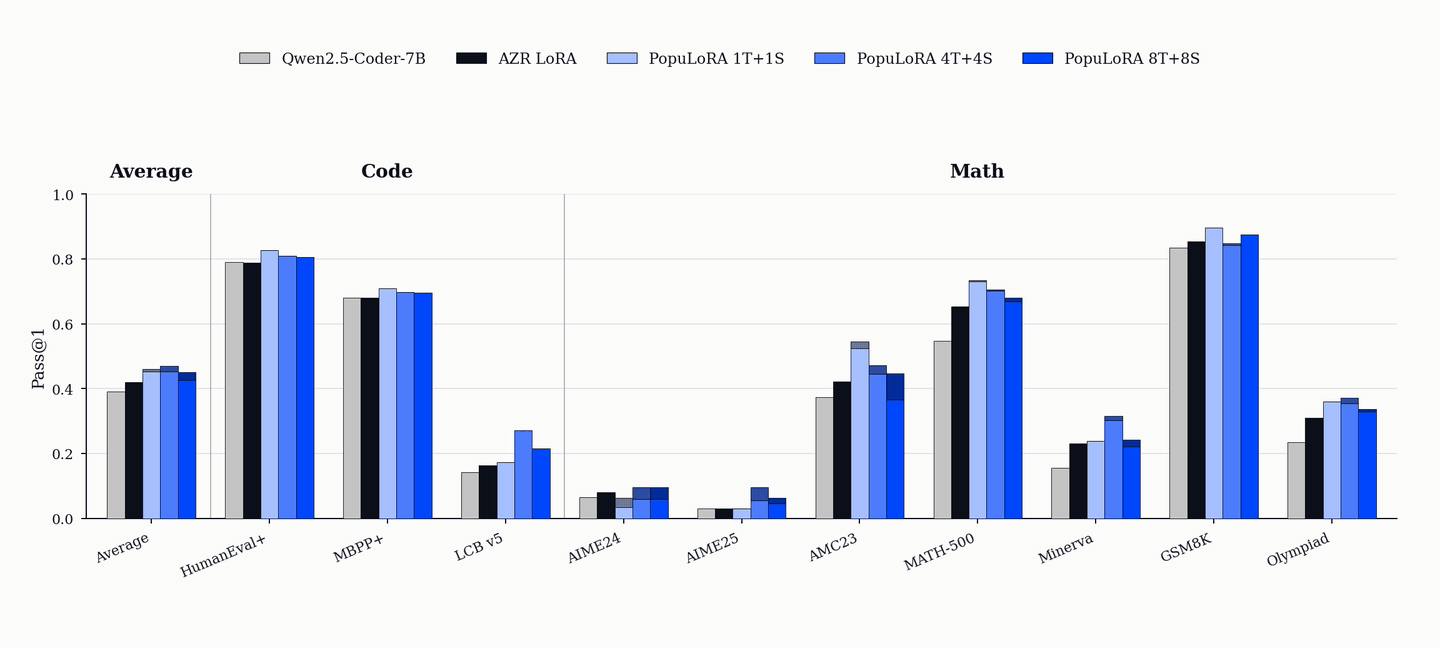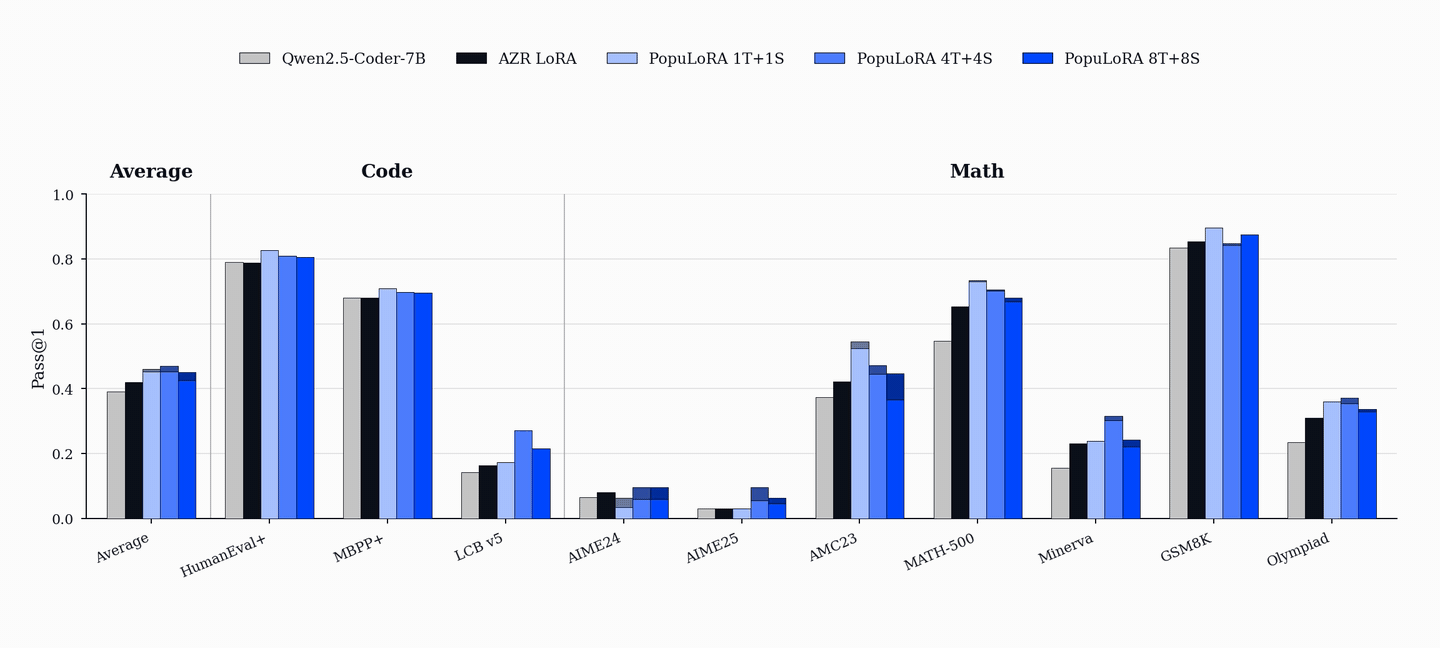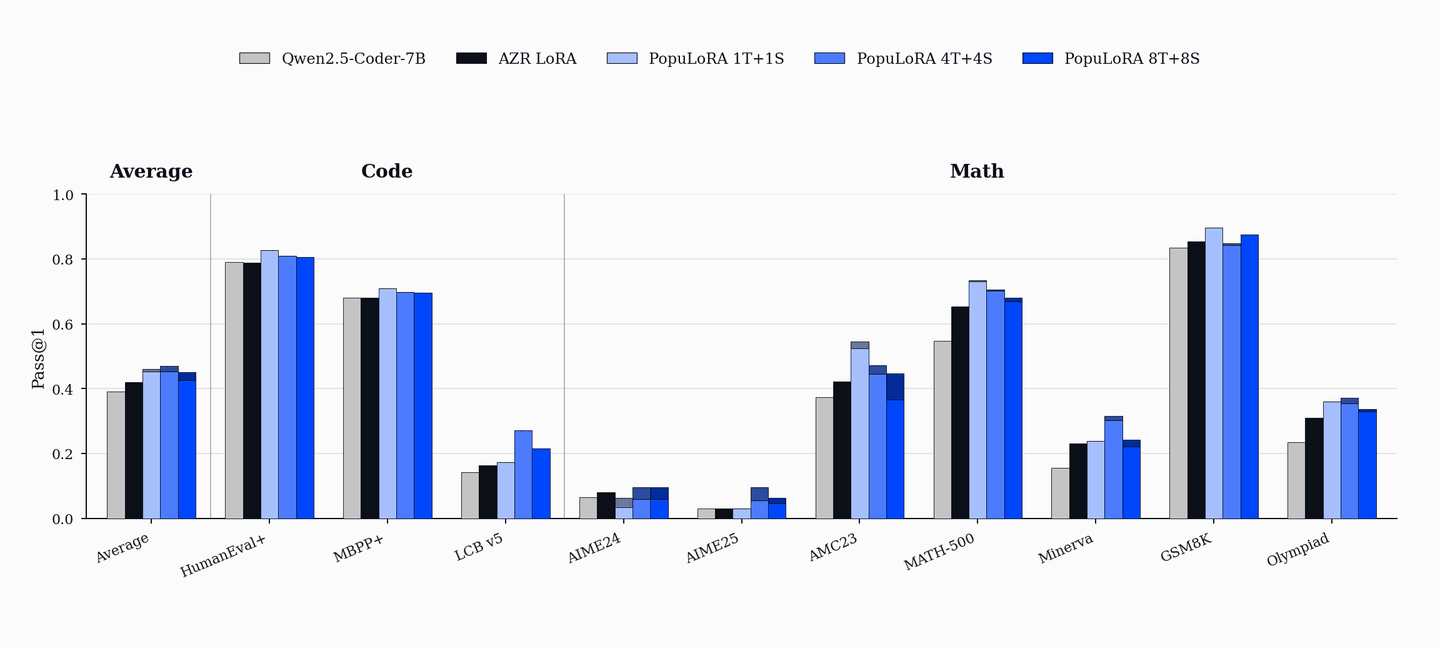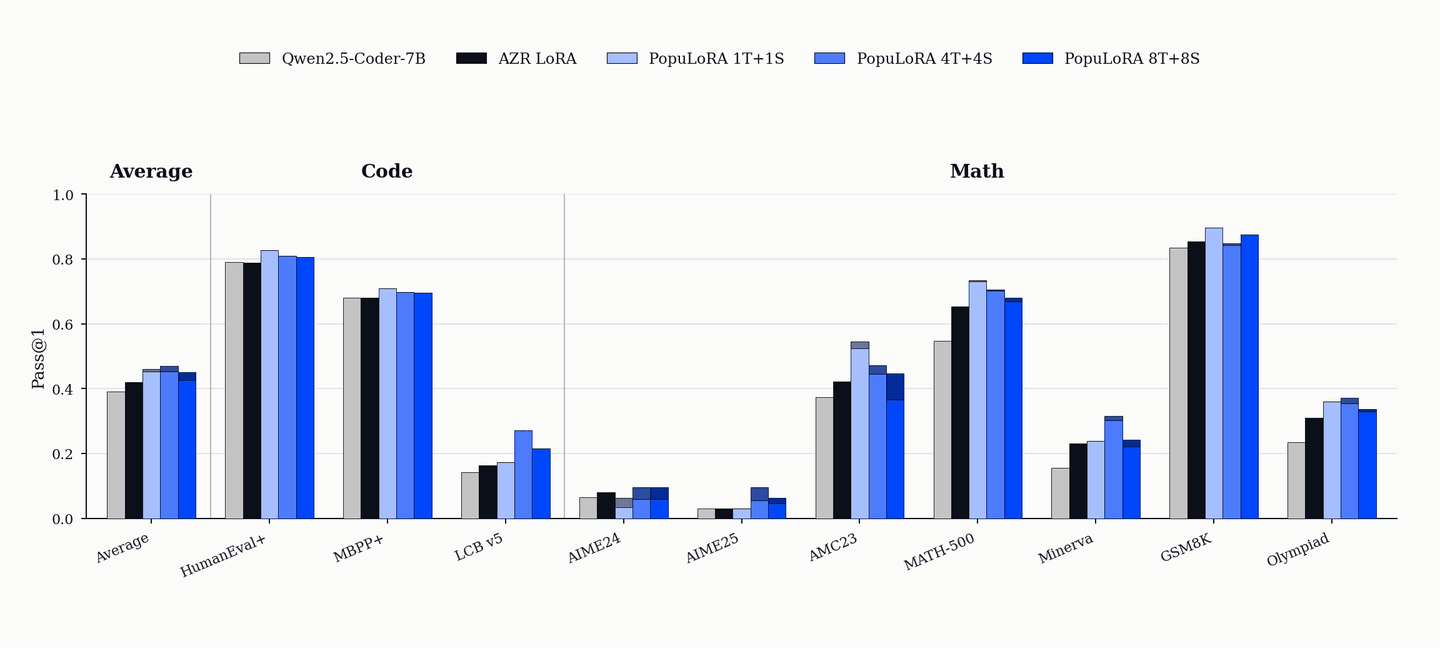
성능 향상은 코드 및 수학 벤치마크(HumanEval+, MBPP+, AIME, MATH-500 등)에서 기존 단일 에이전트 베이스라인을 상회하는 성능을 보이며, 이는 코드 학습이 수학적 추론 능력으로 전이될 수 있음을 시사한다.
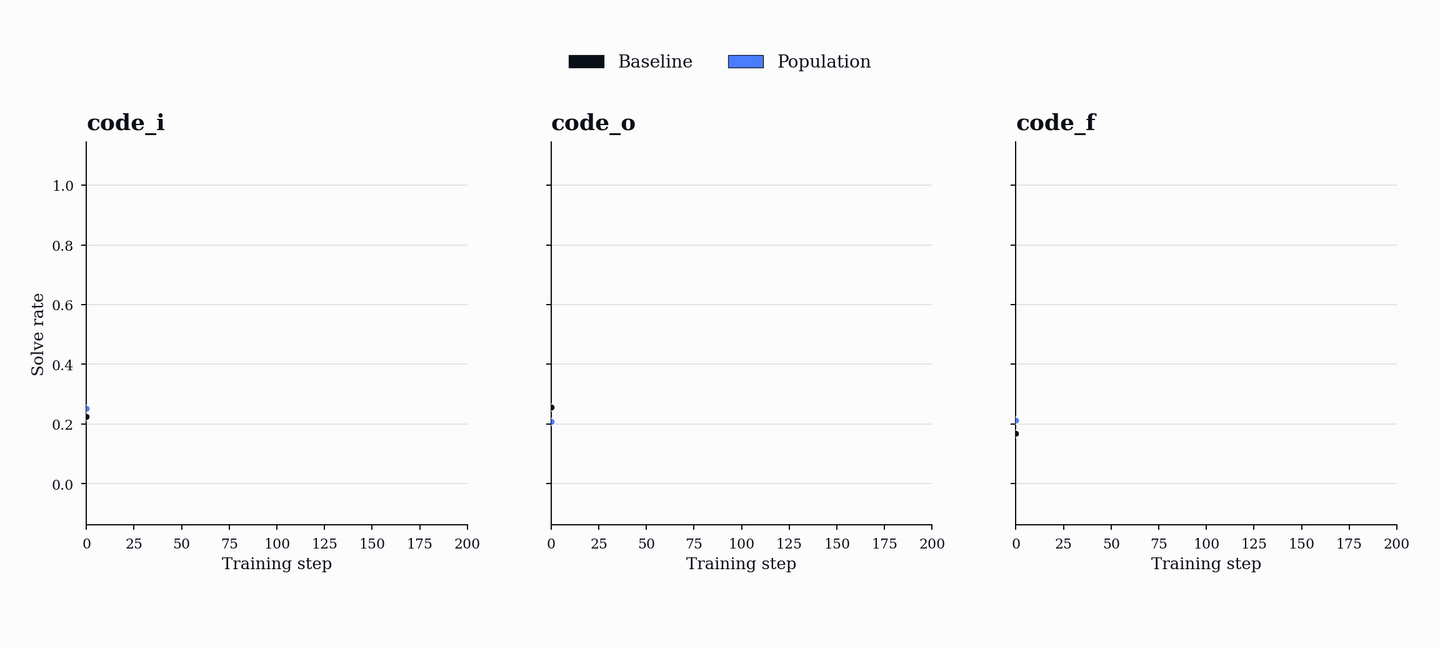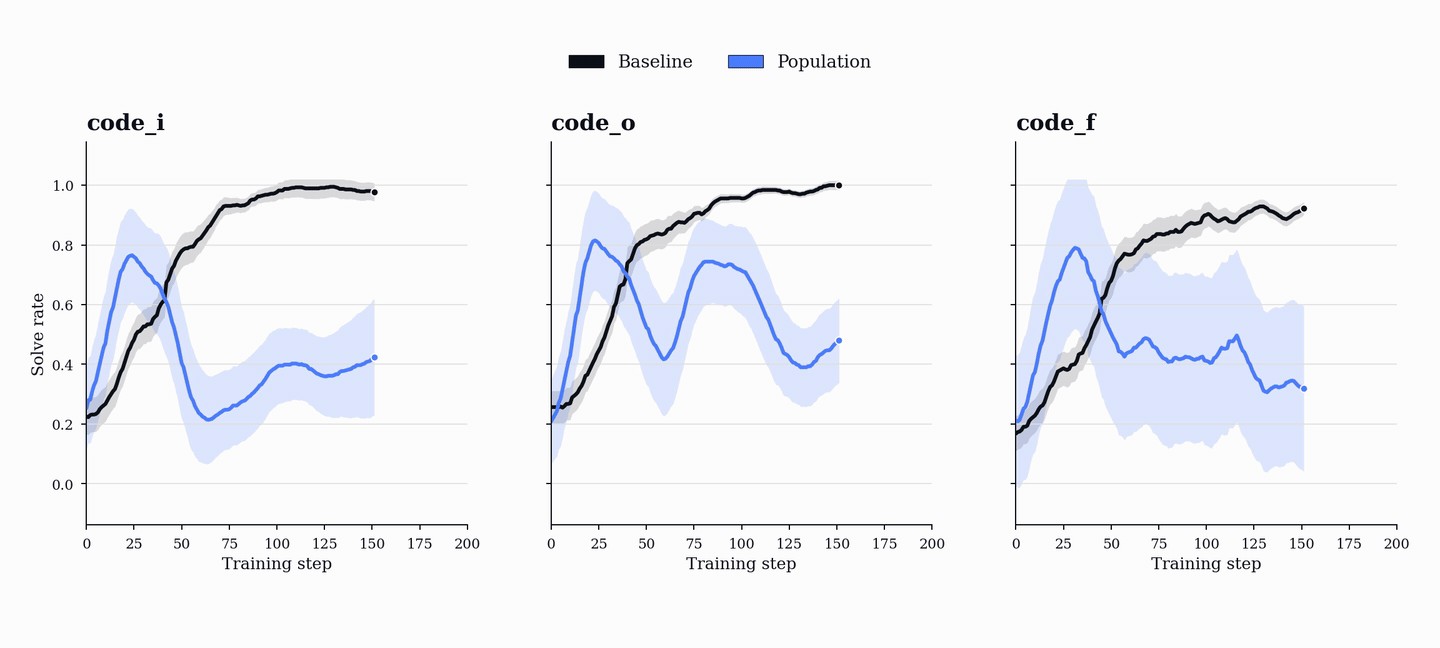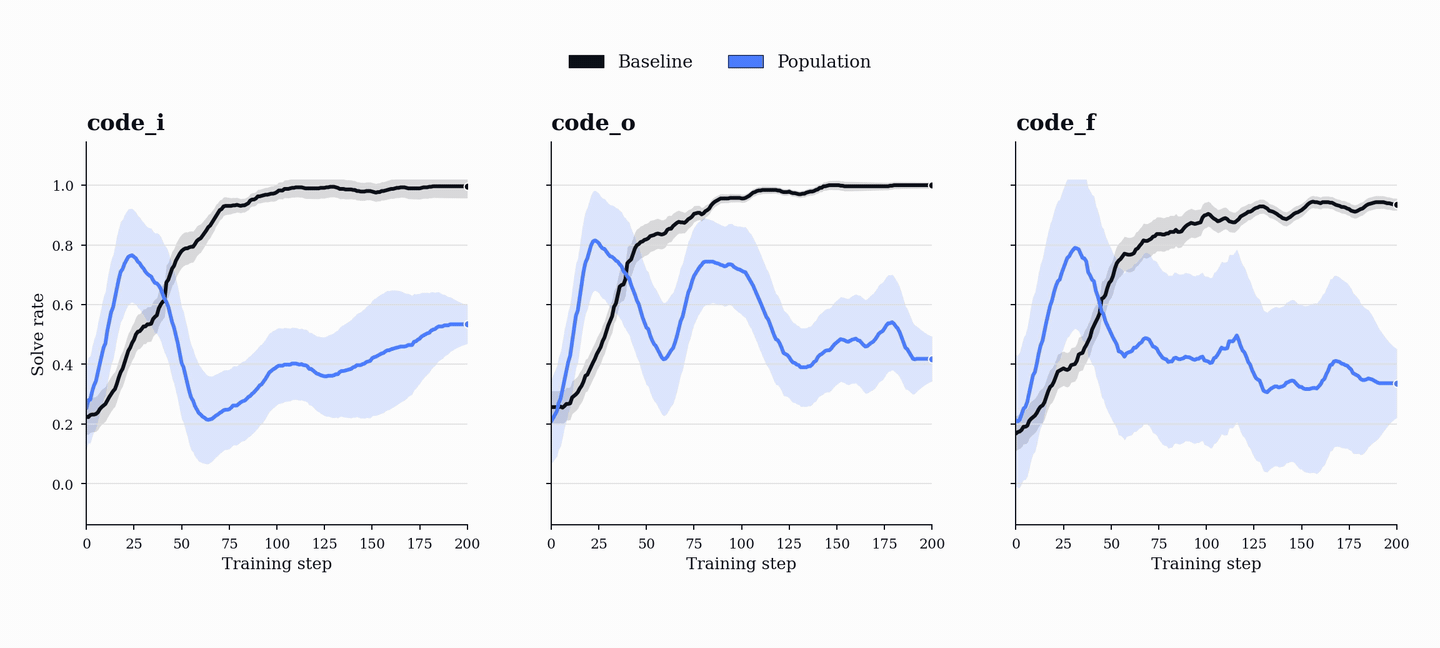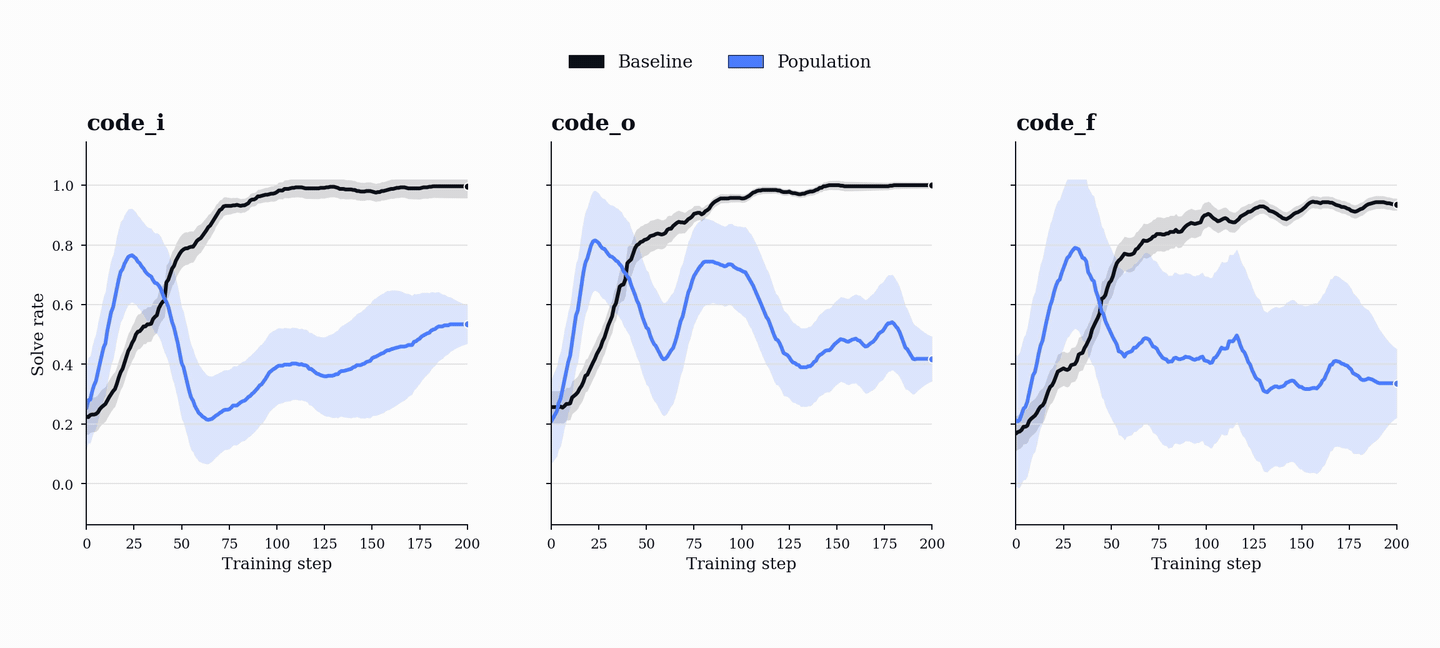
근거
- PopuLoRA는 HumanEval+, MBPP+, LiveCodeBench 등 코드 벤치마크에서 단일 에이전트 베이스라인을 상회한다. — Downstream Results 섹션
용어 해설
- RLVR
- — Reinforcement Learning with Verifiable Rewards의 약자로, 모델이 생성한 결과물의 정답 여부를 결정론적 검증기(예: 단위 테스트, 수학적 정답)를 통해 자동으로 확인하고 보상을 부여하는 학습 방식이다. 모델의 추론 능력을 정교하게 발달시키는 데 효과적이다.
- Self-Play
- — 모델이 스스로 작업을 생성하고 이를 해결하려 시도하며 학습하는 방식이다. 초기에는 모델의 성능 향상에 기여하지만, 작업 생성자와 해결자가 동일할 경우 모델이 이미 해결 가능한 쉬운 작업으로 수렴하는 커리큘럼 붕괴 현상이 발생할 수 있다.
- Curriculum Collapse
- — 자기 대결 학습 과정에서 모델이 자신의 능력 범위 내에 있는 쉬운 작업만을 반복적으로 생성하고 해결하여, 더 이상 학습이 진전되지 않고 성능이 정체되는 현상이다. 학습 분포가 모델의 현재 실력에 맞춰 고착화되는 것이 핵심 문제이다.
- TrueSkill
- — Microsoft에서 개발한 플레이어의 실력을 추정하는 순위 시스템이다. PopuLoRA에서는 교사와 학생 어댑터 간의 실력을 평가하고, 실력이 비슷한 상대끼리 매칭하여 학습 효율을 극대화하는 데 사용된다.
- LoRA
- — Low-Rank Adaptation의 약자로, 거대 모델의 전체 가중치를 수정하지 않고 저순위 행렬만을 학습시켜 파라미터 효율성을 극대화하는 파인튜닝 기법이다. PopuLoRA에서는 다수의 어댑터를 효율적으로 운용하는 기반 기술로 사용된다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 21.수집 2026. 05. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.