이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
기업 AI 도입 시 모델의 파라미터 규모보다 데이터 분포와 작업의 일치도가 성능을 결정하는 핵심 변수로 작용한다. DharmaOCR 연구는 30억 파라미터의 특화 모델이 상용 거대 언어 모델보다 OCR 작업에서 더 높은 정확도와 낮은 비용을 기록했음을 입증했다. 모델의 학습 이력이 배포 환경의 작업 분포와 가까울수록 성능이 향상되며, 이는 단계적 전문화 과정을 통해 누적된다. 이러한 결과는 기업이 범용 모델에만 의존하기보다 도메인에 최적화된 모델 생태계를 구축하는 것이 전략적으로 유리함을 시사한다.
배경
언어 모델의 파인튜닝 및 학습 과정에 대한 이해, OCR 및 도메인 특화 데이터셋의 개념, 모델 평가 지표(정확도, 비용, 텍스트 퇴화)에 대한 이해
대상 독자
기업용 AI 시스템을 설계하고 모델을 선정하는 엔지니어 및 의사결정자
의미 / 영향
이 결과는 기업이 범용 거대 모델에만 의존하는 전략에서 벗어나, 도메인 특화 모델을 단계적으로 구축하는 전략으로 전환할 필요성을 제시한다. 특히 비용 효율성과 생산 안정성이 중요한 엔터프라이즈 환경에서 전문화된 소형 모델이 강력한 대안이 될 수 있음을 보여준다.
섹션별 상세
기존 기업 AI 전략은 파라미터 규모가 클수록 성능이 우수하다는 가정에 의존해 왔다.
DharmaOCR 벤치마크 결과, 30억 파라미터의 특화 모델이 Claude Opus 4.6 등 상용 모델을 제치고 가장 높은 정확도를 기록했다.
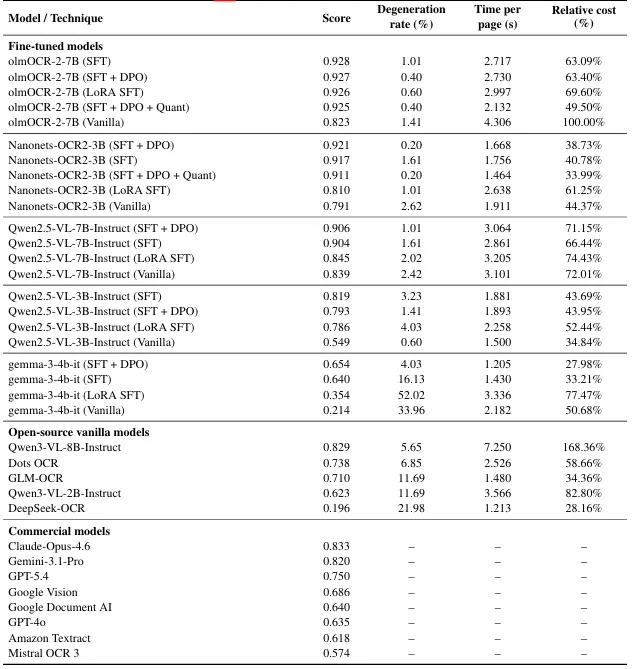
특화 모델은 범용 모델 대비 비용이 약 50배 저렴하며, 텍스트 생성 루프에 빠지는 텍스트 퇴화(degeneration) 비율도 가장 낮게 나타났다.
모델 성능을 결정하는 핵심은 파라미터 수가 아닌 학습 이력과 작업 분포의 일치도(distributional alignment)이다.
전문화는 단일 단계가 아닌 계층적 구조를 가지며, 범용 모델에서 도메인 특화 모델로 단계적 학습을 거칠수록 성능이 누적적으로 향상된다.
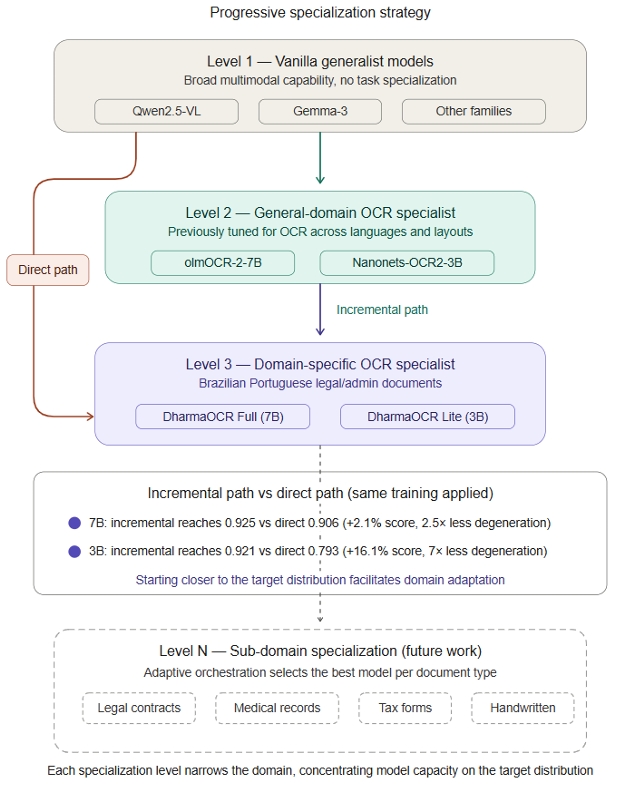
실무 Takeaway
- 특정 도메인 작업에는 범용 거대 모델보다 해당 작업 분포에 맞춰 학습된 소형 특화 모델이 비용과 성능 면에서 우월하다.
- 모델 선정 시 파라미터 규모뿐만 아니라, 모델의 학습 이력이 타겟 작업 분포와 얼마나 일치하는지를 핵심 평가 지표로 고려한다.
- 전문화 과정은 단계적으로 누적되므로, 범용 모델에서 시작해 점진적으로 도메인 특화 데이터를 학습시키는 파이프라인을 구축한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 23.수집 2026. 05. 23.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.