이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
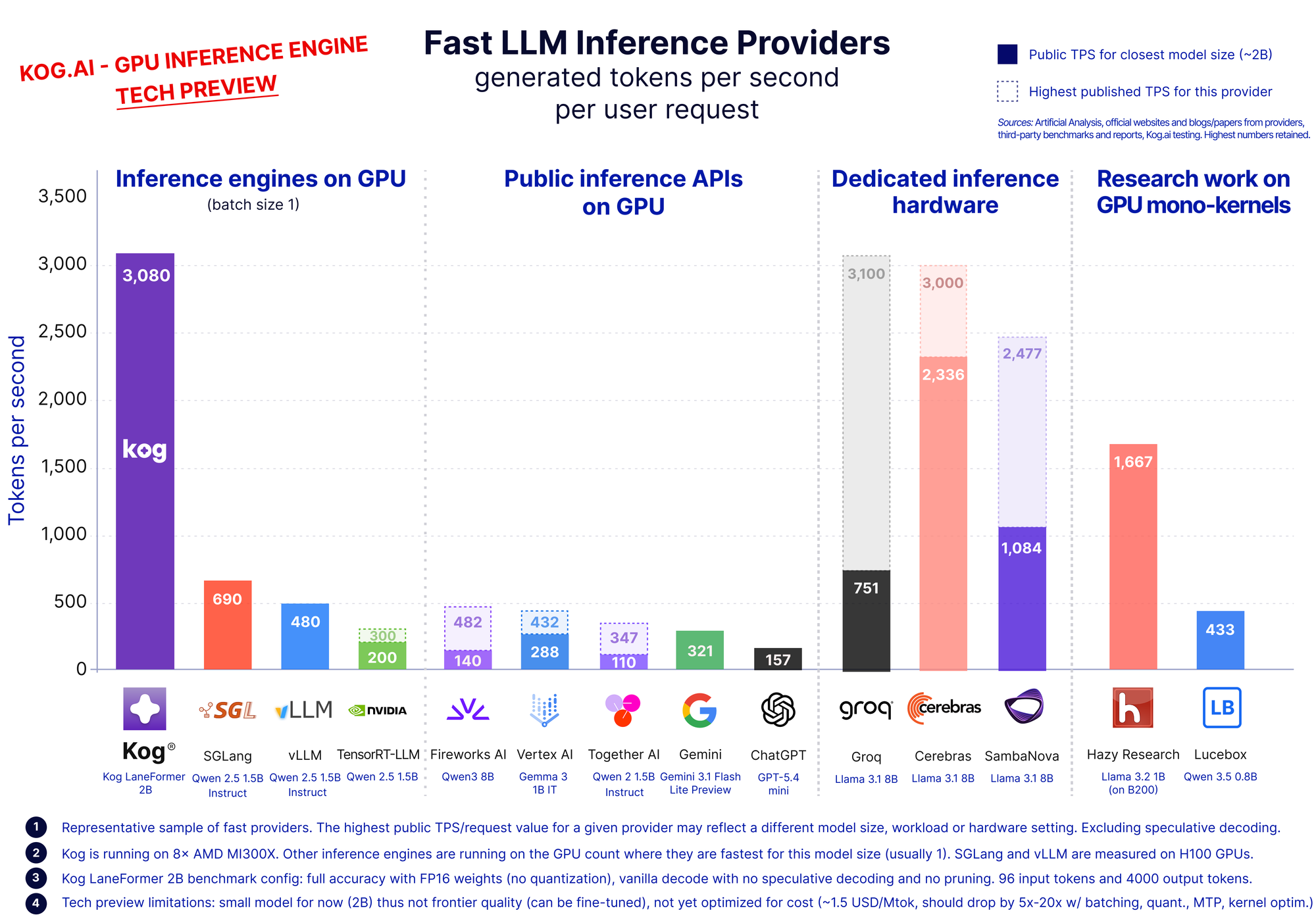
Kog.ai는 AI 에이전트의 반복적인 추론 속도를 높이기 위해 단일 요청 디코딩 성능을 최적화하는 추론 엔진을 개발했다. 기존 추론 스택은 커널 호출과 동기화 오버헤드로 인해 메모리 대역폭을 충분히 활용하지 못하는 한계가 있다. Kog는 모노커널 런타임과 하드웨어 토폴로지 최적화, 자체 모델 아키텍처를 결합해 GPU 메모리 대역폭을 극대화한다. 8x MI300X 노드에서 2B 모델 기준 초당 3,000 토큰의 생성 속도를 달성했다. 이는 에이전트 워크플로의 지연 시간을 획기적으로 줄여 생산성을 높이는 기반이 된다.
배경
GPU 아키텍처 및 메모리 계층 구조에 대한 이해, CUDA 또는 HIP 기반의 저수준 GPU 프로그래밍 지식, LLM 추론 파이프라인 및 병렬화 기법(Tensor Parallelism)에 대한 이해
대상 독자
프로덕션 환경에서 LLM 추론 성능 최적화가 필요한 AI 엔지니어 및 인프라 개발자
의미 / 영향
이 기술은 범용 데이터센터 GPU에서도 전용 하드웨어 수준의 추론 속도를 구현할 수 있음을 입증한다. 특히 에이전트 워크플로의 반복 지연 시간을 획기적으로 단축하여 자율형 AI 에이전트의 실용성을 크게 높일 것으로 전망된다.
섹션별 상세
AI 에이전트는 계획, 편집, 테스트 등 순차적 루프를 반복하므로 단일 요청 디코딩 속도가 전체 성능을 결정한다.
기존 추론 엔진은 고수준 추상화와 잦은 커널 호출로 인해 마이크로초 단위의 오버헤드가 발생하며, 이는 메모리 대역폭 활용을 저해한다.
Kog는 모노커널 런타임을 도입하여 MatMul, 어텐션, 샘플링 등 전체 디코딩 경로를 중단 없는 단일 GPU 프로그램으로 실행한다.
하드웨어 토폴로지를 고려한 메모리 버퍼 배치와 자체 통신 라이브러리(KCCL)를 통해 GPU 간 통신 지연을 최소화한다.
8x MI300X 노드에서 2B 모델을 구동하여 초당 3,000 토큰의 생성 속도를 기록하며, 이는 기존 범용 추론 스택 대비 압도적인 성능이다.
실무 Takeaway
- 단일 요청 디코딩 속도는 에이전트의 생산성을 결정하는 핵심 지표이며, 메모리 대역폭 활용률(MBU) 최적화가 필수적이다.
- 범용 추론 엔진의 커널 호출 오버헤드를 제거하고 모노커널 구조를 채택하면 GPU 하드웨어의 이론적 성능에 근접한 속도를 낼 수 있다.
- 대규모 모델 추론 시 하드웨어 토폴로지(칩렛 구조 등)를 고려한 데이터 배치와 통신 최적화가 성능 병목을 해결하는 열쇠다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 05. 29.수집 2026. 05. 29.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.