이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
기존 Hive 스타일 파티셔닝은 테이블 생성 시점의 물리적 구조에 종속되어 데이터 스큐와 작은 파일 문제를 유발한다. Liquid Clustering은 데이터 레이아웃을 엔진이 관리하는 세부 구현 사항으로 전환하여 유연한 클러스터링 키 변경과 자동 최적화를 지원한다. 실제 펫바이트 규모 워크로드에서 쿼리 속도가 최대 5.9배 향상되고 데이터 크기가 27% 감소하는 성과를 거두었다. 이 방식은 Delta 및 Iceberg와 같은 오픈 테이블 포맷에서 메타데이터 기반의 효율적인 데이터 스킵을 수행한다.
배경
데이터 레이크하우스 아키텍처 이해, Delta Lake 또는 Iceberg 테이블 포맷에 대한 지식
대상 독자
데이터 엔지니어 및 데이터 레이크하우스 운영자
의미 / 영향
Liquid Clustering은 데이터 레이아웃 관리의 복잡성을 제거하여 엔지니어가 물리적 구조 설계보다 비즈니스 로직에 집중하게 한다. 특히 대규모 데이터셋에서 쿼리 성능과 스토리지 효율을 동시에 확보할 수 있어 프로덕션 환경의 운영 비용을 절감한다.
섹션별 상세
파티셔닝은 고정된 컬럼 기반의 물리적 구조를 강제하여 데이터 스큐와 작은 파일 문제를 발생시키며, 75% 이상의 사례에서 비효율을 초래한다.

Liquid Clustering은 클러스터링 키를 유연하게 변경할 수 있고, 자동 최적화를 통해 데이터 레이아웃을 진화시켜 불필요한 테이블 재작성을 방지한다.
디렉터리 기반 프루닝은 현대적 오픈 테이블 포맷에서 존재하지 않으며, Liquid Clustering은 트랜잭션 로그와 통계 정보를 활용해 파일 단위로 정밀하게 데이터를 스킵한다.
저카디널리티 컬럼에 대한 최적화와 메타데이터 전용 연산(DELETE, COUNT, GROUP BY)을 지원하여 쿼리 성능을 최대 27배까지 개선한다.
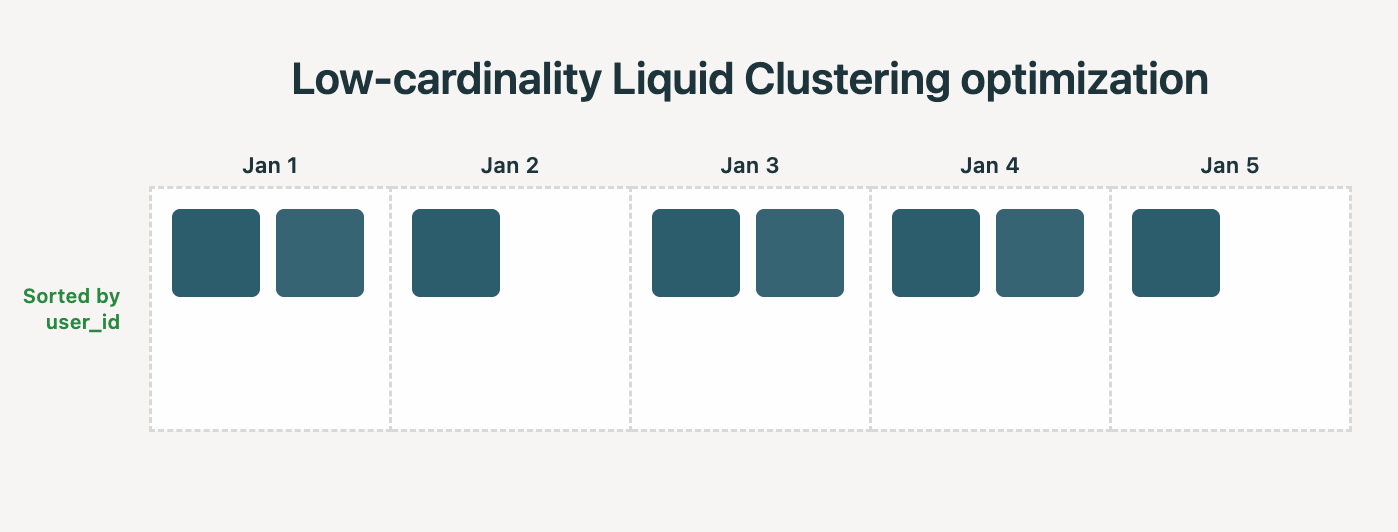
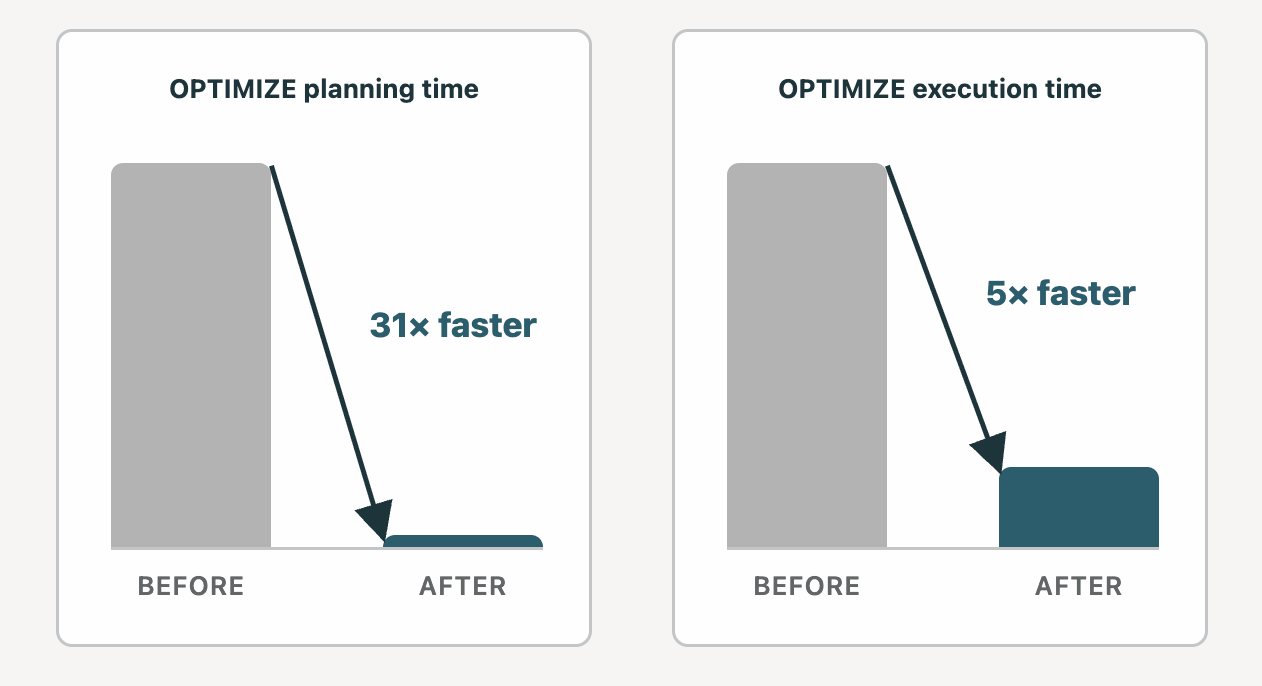
펫바이트 규모의 대규모 테이블에서도 OPTIMIZE 작업의 계획 시간을 12시간에서 23분으로 단축하고 실행 속도를 5배 향상시켰다.
파티셔닝이 파일 단위 동시성만 제공하는 것과 달리, Liquid Clustering은 행 단위 동시성을 지원하여 ETL 파이프라인의 병렬 처리를 원활하게 한다.
실무 Takeaway
- 파티셔닝 대신 Liquid Clustering을 도입하여 데이터 스큐 문제를 해결하고 쿼리 지연 시간을 획기적으로 단축할 수 있다.
- 자동 Liquid Clustering 기능을 활용하면 워크로드와 쿼리 패턴에 따라 최적의 클러스터링 키를 시스템이 지능적으로 선택한다.
- 기존 파티셔닝 테이블을 Liquid Clustering으로 변환하면 재작성 없이도 쿼리 성능 향상과 스토리지 비용 절감 효과를 즉시 얻을 수 있다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 02.수집 2026. 06. 02.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.