이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
Helion은 성능 이식성이 뛰어난 ML 커널 작성을 위한 PyTorch의 DSL이며, 최적의 설정을 찾기 위해 기존에는 LFBO(Likelihood-Free Bayesian Optimization)를 사용했다. LLM 기반 자동 튜너는 커널 구조와 워크로드를 분석하여 유망한 설정을 제안함으로써 벤치마크 횟수를 10배 줄이고 튜닝 시간을 6.7배 단축했다. LLM이 제안한 설정은 기존 LFBO와 대등한 성능을 보이며, 성능 격차가 발생하는 일부 커널은 LLM 초기화 후 LFBO로 정밀 튜닝하는 하이브리드 방식으로 해결 가능하다. 이 방식은 모델 종류와 무관하게 일관된 효율성을 제공하여 프로덕션 환경의 개발 속도를 높인다.
대상 독자
프로덕션 환경에서 고성능 GPU 커널을 개발하고 최적화하는 엔지니어
의미 / 영향
이 기술은 LLM을 활용해 복잡한 커널 튜닝 과정을 자동화함으로써 개발자의 생산성을 획기적으로 높인다. 특히 하이브리드 접근 방식은 LLM의 빠른 탐색 능력과 기존 최적화 알고리즘의 정밀함을 결합하여, 다양한 하드웨어 환경에서 최적의 성능을 빠르게 확보하는 표준적인 방법론이 될 것으로 기대된다.
섹션별 상세
기존 Helion 커널 튜닝은 LFBO를 사용하여 수백 번의 컴파일 및 벤치마크 과정을 거쳐야 하므로 시간이 많이 소요되는 문제가 있었다.
LLM 기반 자동 튜너는 커널 소스 코드와 워크로드 정보를 바탕으로 유망한 설정 후보를 생성하여 탐색 공간을 효율적으로 좁힌다.
json
{"block_sizes":[1],"load_eviction_policies":["last","last","last","last","last"],"reduction_loops":[null]}Helion 컴파일러가 커널 구조를 분석하여 도출한 초기 시드 설정 예시
json
{"configs":[ {"block_sizes":[1],"load_eviction_policies":["last", "..."],"num_warps":8}, {"block_sizes":[8],"load_eviction_policies":["last", "..."],"num_warps":8,"num_stages":2} ]}LLM이 제안한 커널 설정 후보군 예시
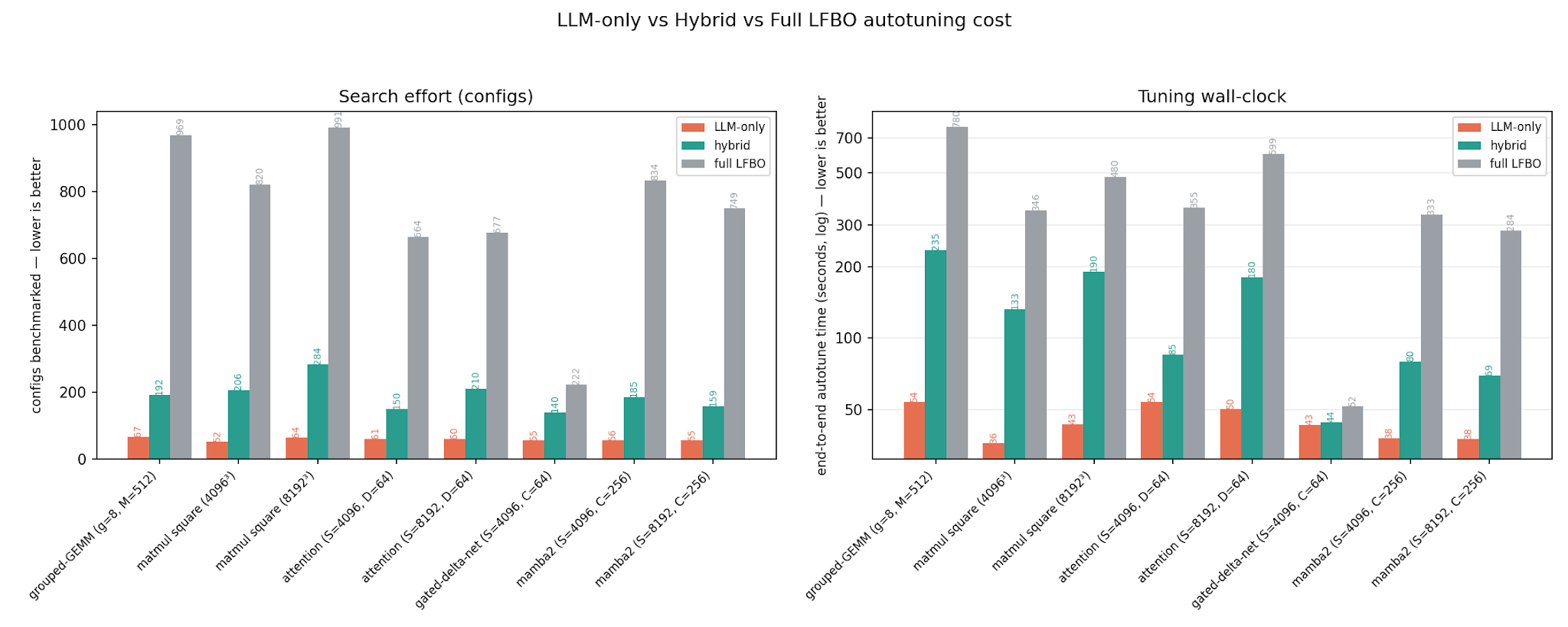
33개 커널 인스턴스 벤치마크 결과, LLM 튜너는 기존 LFBO 대비 10배 적은 설정으로 동등한 성능(1.009배 지연 시간)을 달성했다.
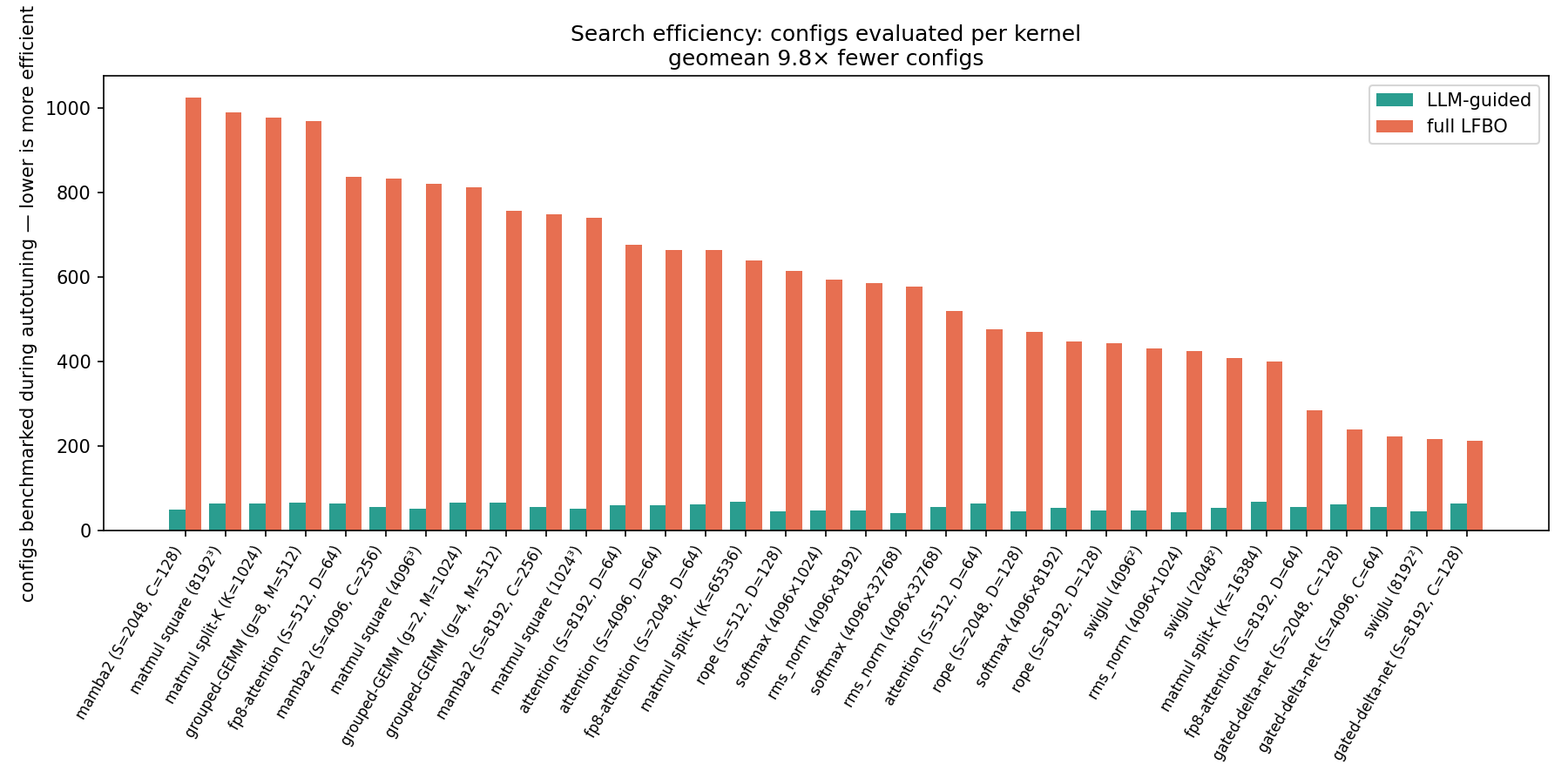
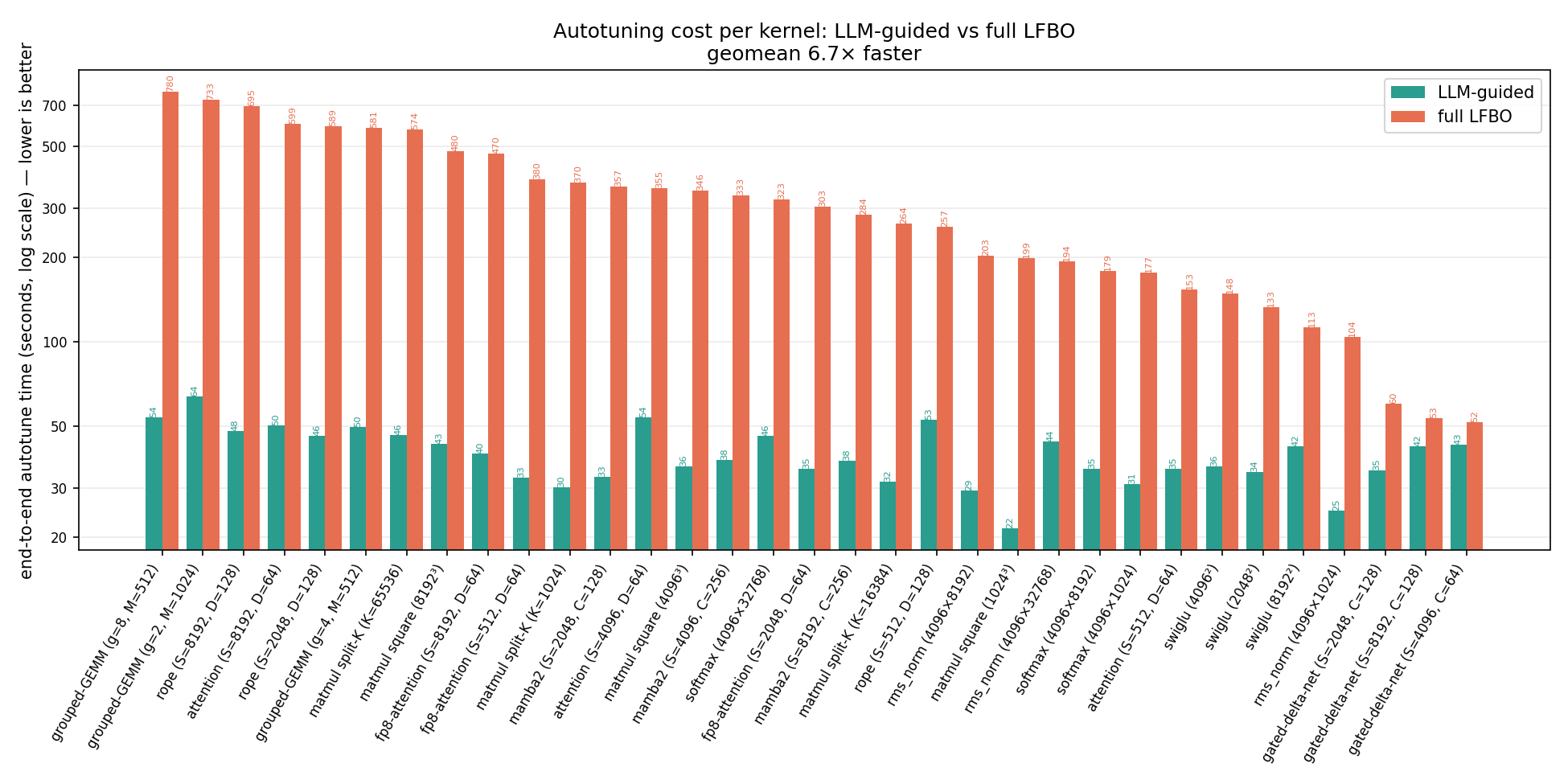
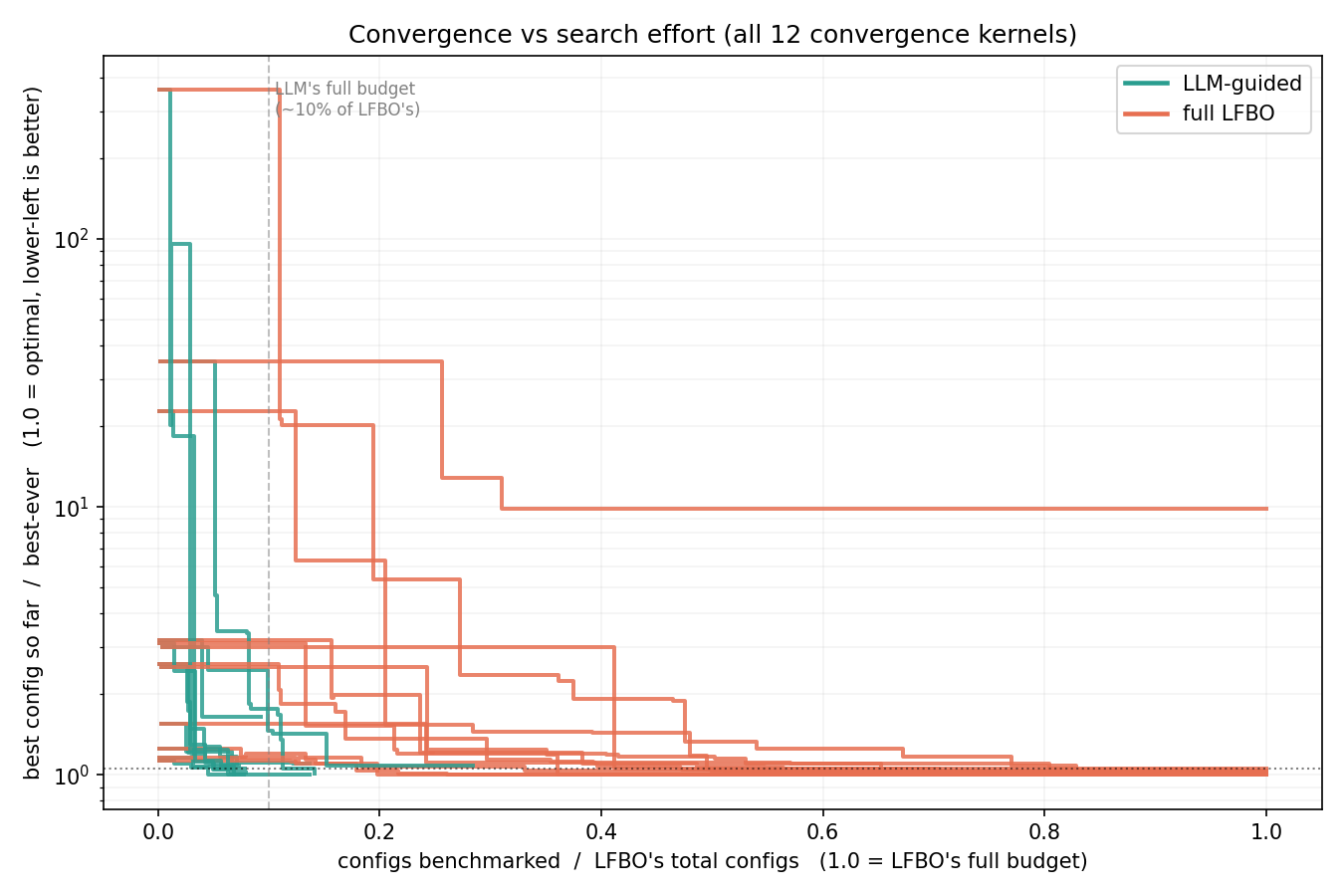
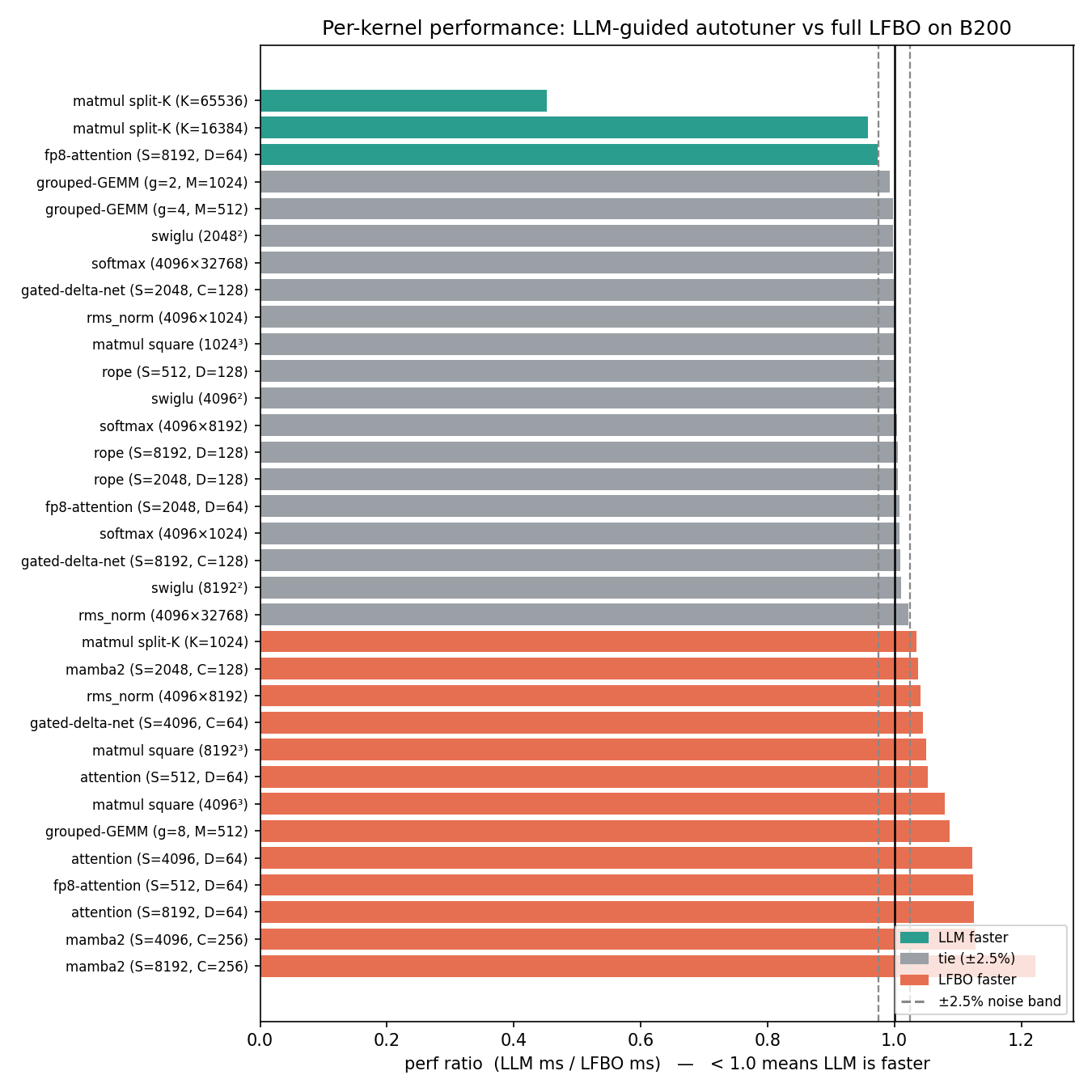
LLM이 미세 조정에 취약한 경우, LLM으로 초기 설정을 잡고 LFBO로 정밀 튜닝하는 하이브리드 전략을 통해 성능 격차를 해소하고 3배 빠른 튜닝 시간을 확보했다.
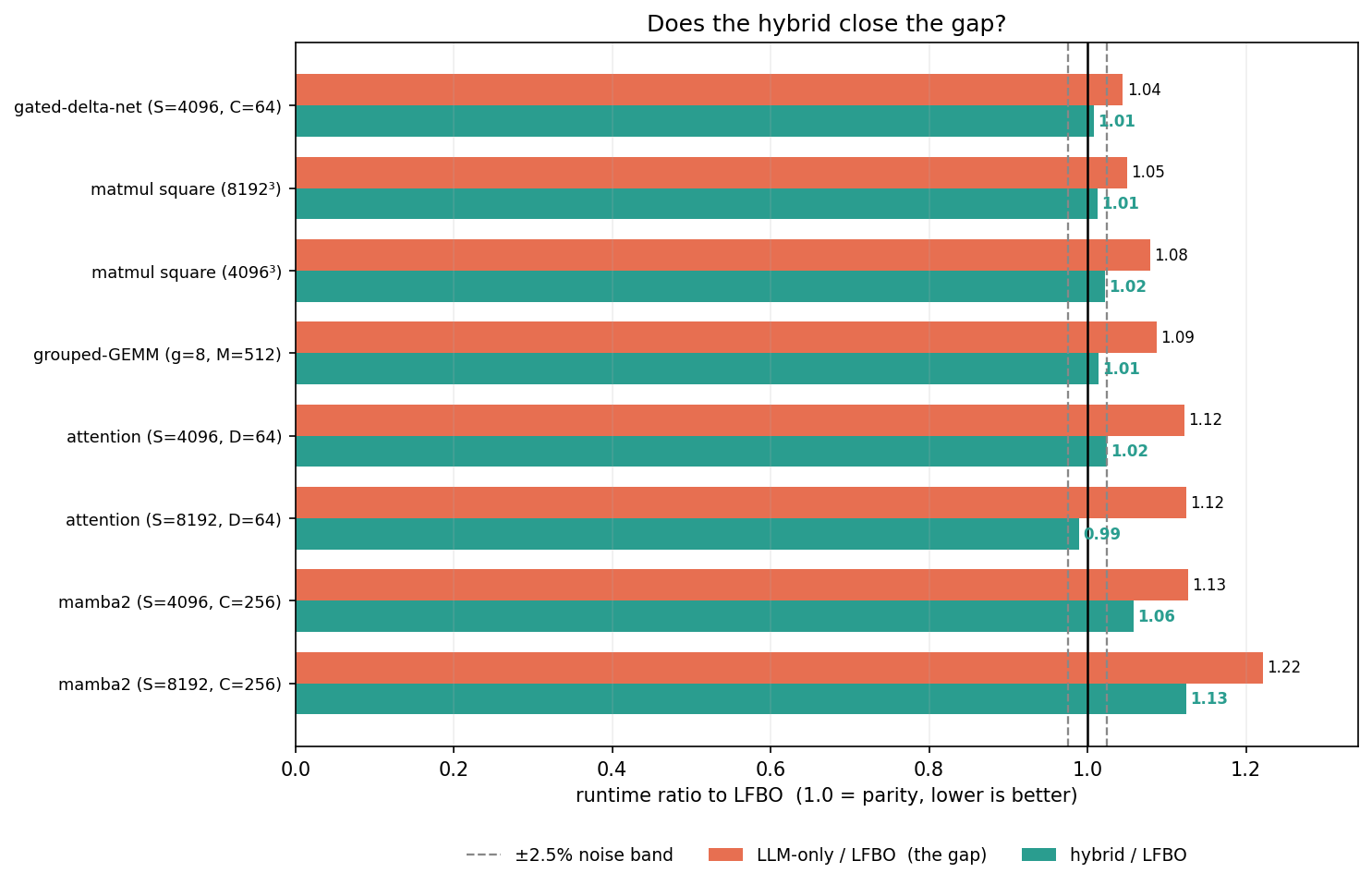
Opus-4.8, gpt-5.5, Sonnet-4.6 등 다양한 모델에서 유사한 성능을 보여 LLM 모델 종류에 의존하지 않는 실용적인 튜닝 방식임이 확인됐다.
실무 Takeaway
- LLM 기반 자동 튜닝을 도입하면 GPU 커널 튜닝 시간을 6.7배 단축하여 개발 생산성을 크게 높일 수 있다.
- 초기 튜닝은 LLM을 활용해 빠르게 최적 설정에 도달하고, 정밀한 미세 조정이 필요한 경우 LFBO를 결합한 하이브리드 방식을 적용한다.
- 모델 종류에 따른 성능 차이가 크지 않으므로, 특정 모델에 의존하지 않고 범용적인 LLM을 활용해 튜닝 파이프라인을 구축할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 19.수집 2026. 06. 19.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.