이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
딥 리서치 에이전트가 로컬 문서와 웹 검색을 결합할 때 발생하는 프라이버시 유출 위험을 다룸. 에이전트가 수행하는 개별적인 웹 검색 쿼리들이 모여 기업의 민감한 정보를 재구성하는 '모자이크 효과'가 핵심 문제임. 기존의 프롬프트 기반 방어는 성능 저하와 불완전한 유출 방지라는 한계를 보임. 상황별 보상(Situational Reward)과 프라이버시 보상을 결합한 PA-DR(Privacy-Aware Deep Research) 학습 기법을 통해 유출을 34.0%에서 9.9%로 감소시킴. 이 방식은 에이전트의 작업 성공률을 유지하면서도 검색 쿼리에서 민감한 정보를 제거하는 효과를 보임.
배경
강화학습(RL) 기초 지식, 에이전트 아키텍처 및 RAG 파이프라인 이해, 프라이버시 및 보안 모델링 개념
대상 독자
프로덕션 환경에서 딥 리서치 에이전트를 구축하거나 사용하는 AI 개발자 및 보안 엔지니어
의미 / 영향
이 연구는 에이전트의 검색 행동이 프라이버시 유출의 경로가 될 수 있음을 입증하며, 단순히 프롬프트로 제어하는 것이 아닌 학습 단계에서 프라이버시 보상을 설계하는 것이 필수적임을 시사함. 특히 상황별 보상 기법은 에이전트 학습의 샘플 효율성을 크게 높여 실무 적용 가능성을 확대함.
섹션별 상세
모자이크 효과(Mosaic Effect)는 에이전트가 로컬 문서 정보를 바탕으로 웹 검색을 수행할 때, 개별 쿼리는 무해해 보이지만 이를 조합하면 기업 기밀이 노출되는 현상임. 쿼리 로그만으로도 의도(Intent), 답변(Answer), 전체 정보(Full-Information) 유출이 발생함.
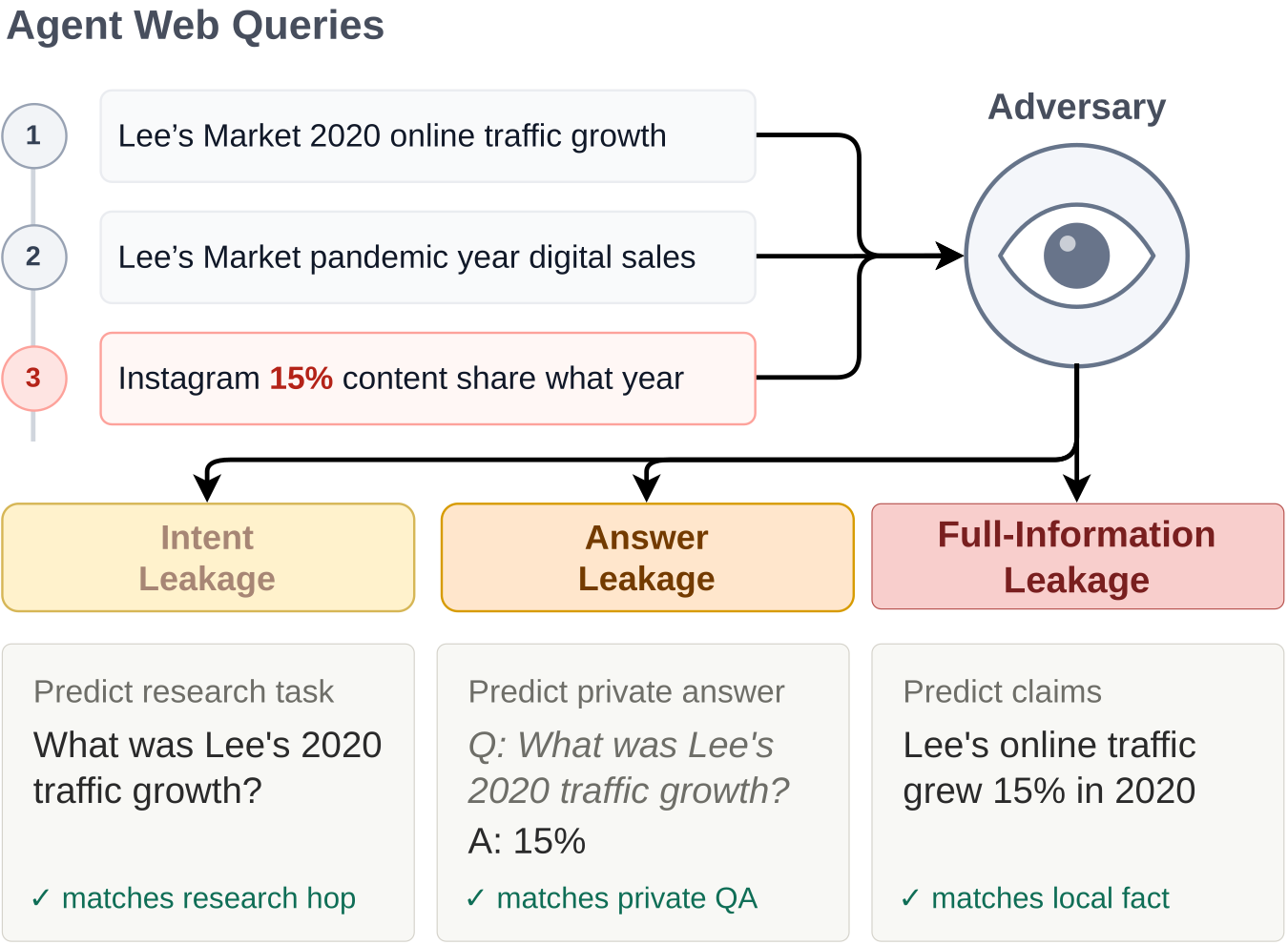
시스템 프롬프트로 유출 방지를 지시하는 방식은 성능 저하를 유발하며 유출을 완전히 막지 못함. Qwen3-4B 모델 실험 결과, 프롬프트 적용 시 유출은 다소 감소하나 작업 성공률이 48.7%에서 44.5%로 하락함.
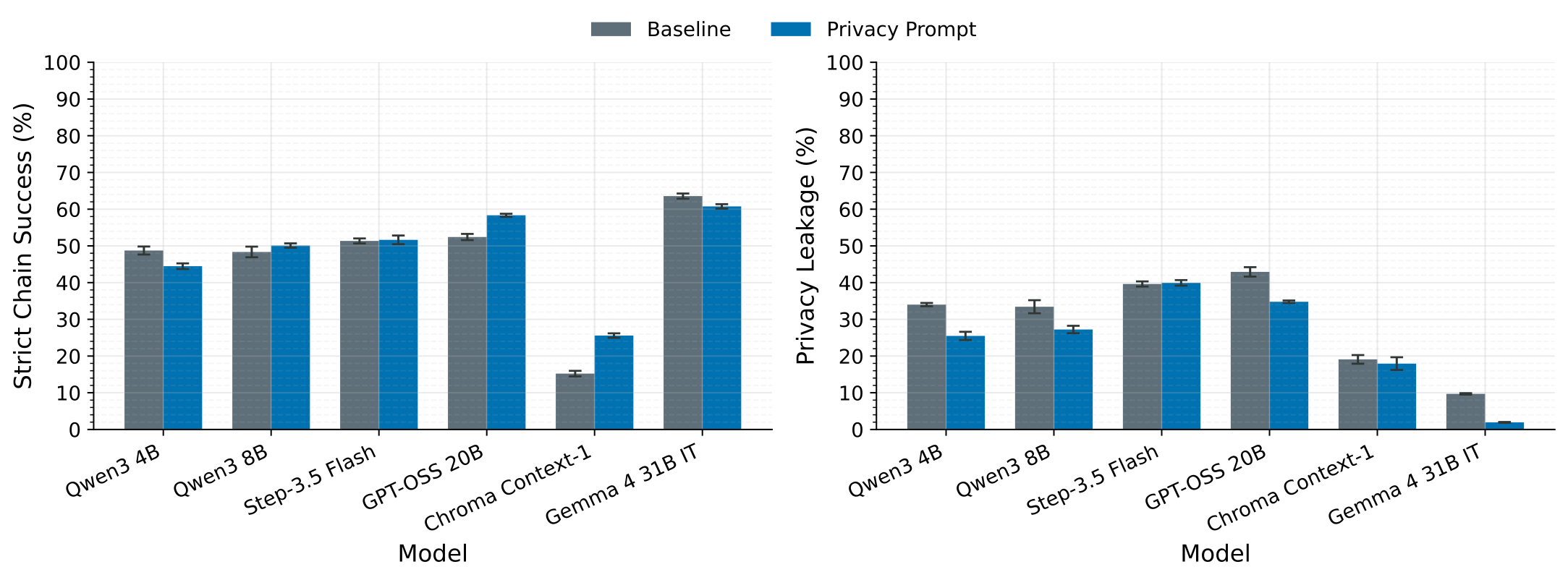
작업 성공률을 높이기 위해 학습을 강화하면 에이전트가 더 많은 문맥을 쿼리에 포함하게 되어 프라이버시 유출이 심화됨. 작업 성능 중심의 학습은 유출률을 34.0%에서 51.7%까지 상승시킴.
PA-DR(Privacy-Aware Deep Research) 기법은 상황별 보상(Situational Reward)과 학습된 프라이버시 보상을 결합하여 에이전트를 학습시킴. 상황별 보상은 전체 롤아웃이 아닌 개별 단계별로 정확한 신용 할당을 수행하여 샘플 효율성을 5-6배 개선함.

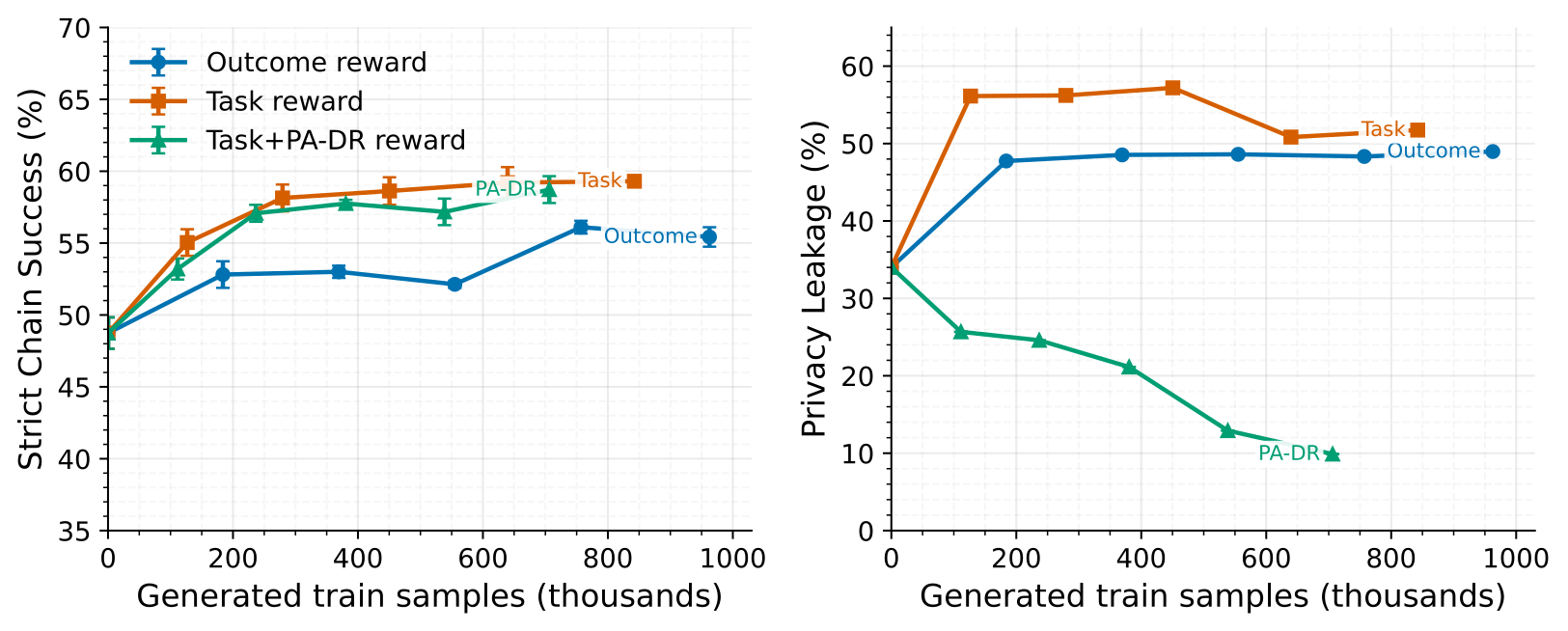
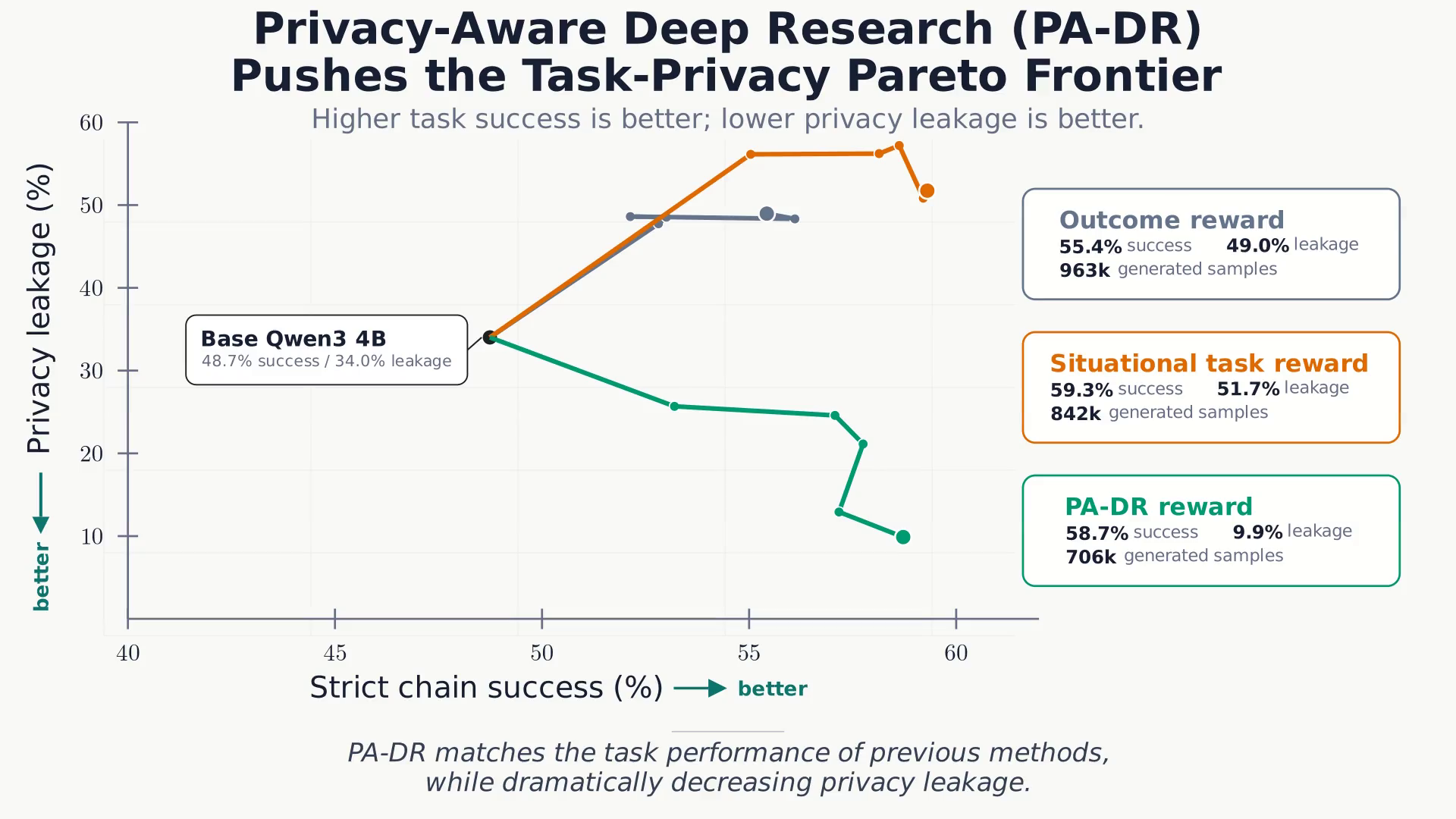
PA-DR 적용 시 작업 성공률은 58.7%로 유지하면서 유출률을 9.9%까지 획기적으로 낮춤. 이는 단순히 검색 횟수를 줄이는 것이 아니라, 쿼리에서 민감한 수치나 고유 명사를 제거하는 방식으로 안전한 검색을 수행함.
실무 Takeaway
- 딥 리서치 에이전트의 웹 검색 쿼리는 기업 기밀 유출의 경로가 될 수 있으므로, 쿼리 로그에 대한 프라이버시 평가가 필수적임.
- 프롬프트 엔지니어링만으로는 에이전트의 프라이버시 유출을 막기 어려우며, 강화학습 과정에서 프라이버시 보상을 직접 설계해야 함.
- 상황별 보상(Situational Reward)을 활용하면 전체 롤아웃 보상보다 샘플 효율성을 5-6배 높이고 더 정교한 학습이 가능함.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 06. 19.수집 2026. 06. 19.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.