이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
기존 Transformer 아키텍처의 연산 효율성 한계를 극복하기 위해 Attention과 RNN 모듈을 결합한 Olmo Hybrid 모델이 공개됐다. 이 모델은 Gated DeltaNet(GDN) 기술을 활용하여 기존 Olmo 3 대비 학습 효율을 약 2배 향상시켰으며, 이론적으로 Transformer나 순수 RNN이 해결하지 못하는 복잡한 문제를 풀 수 있는 높은 표현력을 갖췄다. 하지만 새로운 아키텍처 특성상 기존 오픈소스 추론 도구와의 호환성 및 Post-training 단계에서의 성능 최적화 등 해결해야 할 과제들이 남아있다.
배경
Transformer 아키텍처에 대한 이해, RNN 및 Mamba 등 상태 공간 모델(SSM)의 기본 개념, vLLM 등 LLM 추론 엔진 사용 경험
대상 독자
LLM 아키텍처 연구자 및 효율적인 모델 배포를 고민하는 MLOps 엔지니어
의미 / 영향
Transformer 중심의 LLM 시장에서 하이브리드 아키텍처가 실질적인 효율성 우위를 증명하며 주류로 부상할 가능성을 시사한다. 특히 오픈소스 생태계의 도구 지원이 성숙해짐에 따라 추론 비용 절감의 핵심 기술이 될 것이다.
섹션별 상세
Olmo Hybrid는 Attention 레이어와 Gated DeltaNet(GDN) 레이어를 3:1 비율로 혼합한 하이브리드 구조를 채택했다. 이는 순수 Transformer나 순수 RNN 모델보다 우수한 성능과 효율성의 균형을 제공한다.
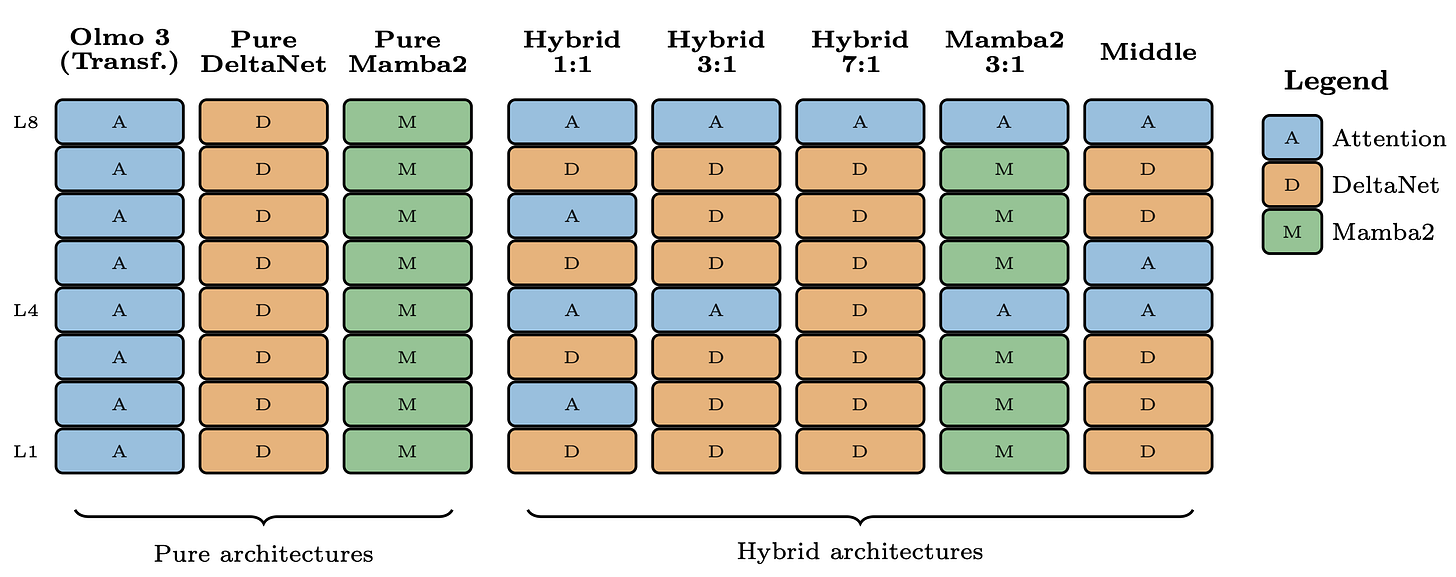
이론적 연구 결과, 하이브리드 모델은 Transformer나 GDN 단독으로는 표현할 수 없는 코드 평가 관련 문제들을 해결할 수 있는 더 높은 표현력을 보유한다. 이는 모델이 더 유연하게 다양한 함수를 학습할 수 있음을 의미한다.
사전 학습(Pre-training) 단계에서 Olmo 3 7B 모델 대비 동일 성능 도달에 필요한 토큰 수를 대폭 줄여 약 2배의 학습 효율 향상을 달성했다. 특히 긴 컨텍스트 확장 후의 성능 개선이 두드러졌다.

Post-training 과정에서 지식 관련 벤치마크는 상승했으나 추론 성능은 Dense 모델 대비 다소 하락하는 현상이 관찰됐다. 이는 기존 Transformer 기반 교사 모델로부터의 지식 전이 효율성이 아키텍처 차이로 인해 달라질 수 있음을 시사한다.
현재 vLLM 등 오픈소스 추론 도구에서 하이브리드 아키텍처를 위한 커널 최적화가 부족한 상태이다. 수치 안정성을 위해 특정 플래그를 사용할 경우 오히려 추론 처리량이 저하되는 문제가 있어 생태계 차원의 개선이 필요하다.
bash
python -m vllm.entrypoints.openai.api_server \
--model allenai/OLMo-Hybrid-7B-Instruct \
--disable-cascade-attn \
--enforce-eager \
--mamba_ssm_cache_dtype fp32vLLM에서 Olmo Hybrid 모델의 수치적 안정성을 확보하기 위해 권장되는 실행 플래그 예시

실무 Takeaway
- 긴 컨텍스트 처리가 중요한 RAG나 에이전트 시스템에서 메모리 효율을 극대화하기 위해 하이브리드 아키텍처 도입을 검토해야 한다.
- 새로운 아키텍처 모델을 도입할 때는 vLLM의 --disable-cascade-attn 및 --enforce-eager 플래그와 같은 수치 안정성 설정을 반드시 확인해야 한다.
- 하이브리드 모델의 성능을 극대화하기 위해서는 기존 Transformer 기반의 교사 모델에서 생성된 데이터가 아닌, 해당 아키텍처에 최적화된 Post-training 전략이 필요하다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 06.수집 2026. 03. 06.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.