핵심 요약
코딩 에이전트의 성능을 높이기 위해 특정 도메인 지식을 담은 '스킬(Skills)'을 동적으로 로드하는 방식이 주목받고 있다. 하지만 스킬 역시 프롬프트의 일종이므로 성능에 미치는 영향을 정밀하게 평가해야 한다. 본 아티클은 Docker 기반의 깨끗한 테스트 환경 구축, 제약 조건이 있는 태스크 정의, 그리고 LangSmith를 통한 추적 및 비교 분석 과정을 상세히 다룬다. 이를 통해 스킬 도입 시 에이전트의 태스크 성공률이 9%에서 82%까지 향상될 수 있음을 보여준다.
배경
LLM 에이전트 및 프롬프트 엔지니어링 기본 지식, Docker 및 컨테이너화 개념, LangChain/LangSmith 생태계에 대한 이해
대상 독자
코딩 에이전트를 개발하거나 프로덕션 환경에서 LLM 에이전트의 성능을 최적화하려는 개발자
의미 / 영향
에이전트에게 무조건 많은 도구를 주는 것보다, 정교하게 평가된 '스킬'을 동적으로 제공하는 것이 성능 향상의 핵심이다. 특히 LangSmith와 같은 관측 도구를 결합한 평가 파이프라인은 에이전트의 신뢰성을 확보하는 표준 모델이 될 것이다.
섹션별 상세
스킬은 에이전트가 필요할 때만 동적으로 로드하는 명령어, 스크립트, 리소스의 집합으로, 컨텍스트 과부하를 방지하면서 전문성을 높인다.
평가 환경의 일관성을 위해 Docker와 같은 샌드박스 환경에서 에이전트를 실행하여 디렉토리 탐색 등 초기 조건에 따른 변수를 통제해야 한다.
모호한 태스크 대신 '버그 수정'과 같이 결과 검증이 명확한 제약된 태스크를 설정하고, 스킬 호출 여부, 완료 시간, 턴 수 등의 지표를 측정한다.
스킬은 XML 태그를 사용해 모듈화하고, AGENTS.md나 CLAUDE.md 파일을 활용해 에이전트가 스킬을 언제 호출해야 하는지 가이드를 제공하여 호출 안정성을 높인다.
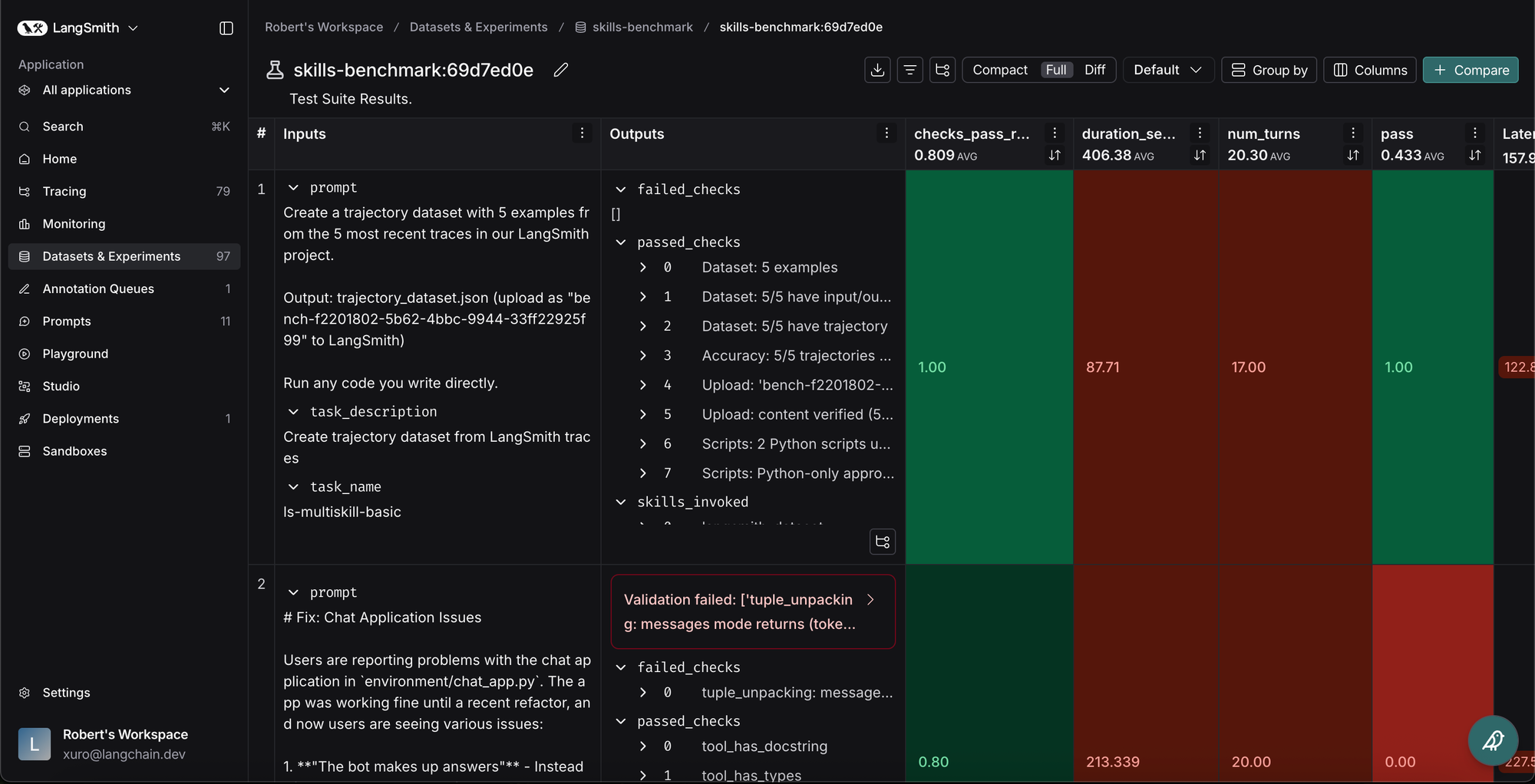
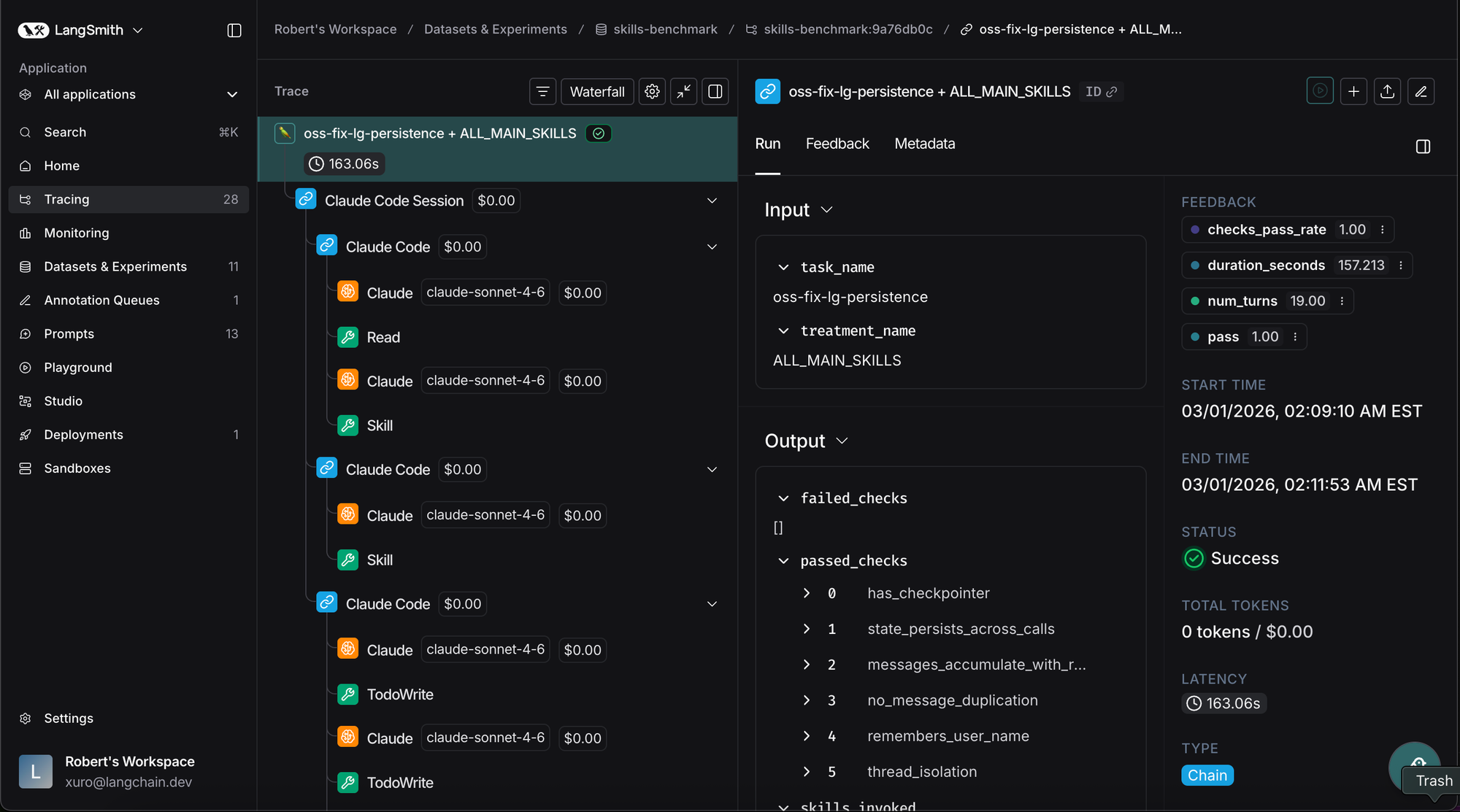
LangSmith를 활용해 에이전트의 전체 실행 궤적(Trajectory)을 기록하고, 에이전트 스스로 자신의 트레이스를 분석하게 하여 스킬 개선 속도를 높인다.
실무 Takeaway
- 스킬을 너무 잘게 쪼개면 호출 오류가 발생하고, 너무 크면 컨텍스트 낭비가 발생하므로 12~20개 사이의 적절한 균형점을 찾아야 한다.
- 단순 성공 여부뿐만 아니라 '스킬이 적절히 호출되었는가'와 '작업 완료까지의 효율성(턴 수)'을 함께 측정하여 스킬의 실질적 가치를 판단한다.
- 에이전트가 자신의 실행 로그를 직접 요약하게 함으로써 인간 개발자가 문제를 파악하고 스킬을 수정하는 반복 주기를 단축한다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료