핵심 요약
OpenAI가 코딩 전용 모델과 일반 추론 모델을 통합한 GPT-5.4를 출시하며 기술적 우위를 다시 한번 입증했다. 이번 모델은 네이티브 컴퓨터 사용 능력(CUA)과 100만 토큰 컨텍스트 창을 특징으로 하며, 업계 전반에서 에이전트 워크플로우의 효율성을 극대화하는 방향으로 진화하고 있다. 동시에 FlashAttention-4의 공개로 Blackwell GPU 환경에서의 추론 속도가 비약적으로 향상되었고, Allen AI의 OLMo Hybrid와 같은 새로운 하이브리드 아키텍처가 오픈 소스 생태계에 등장했다. 결과적으로 AI 산업은 단순한 채팅 인터페이스를 넘어 자율적으로 동작하는 에이전트 자동화와 로컬 실행 단계로 빠르게 진입하는 추세이다.
배경
LLM 아키텍처 기초, 에이전트 워크플로우 개념, GPU 가속 및 어텐션 메커니즘 이해
대상 독자
LLM 기반 에이전트를 구축하는 개발자 및 AI 인프라 엔지니어
의미 / 영향
OpenAI의 통합 모델 출시와 FA4 같은 하드웨어 최적화 기술의 결합은 AI 에이전트의 실용성을 극대화할 것이다. 특히 로컬 실행과 자동화된 워크플로우가 강조되면서 엔터프라이즈 환경에서의 AI 도입 속도가 더욱 빨라질 것으로 예상된다.
섹션별 상세
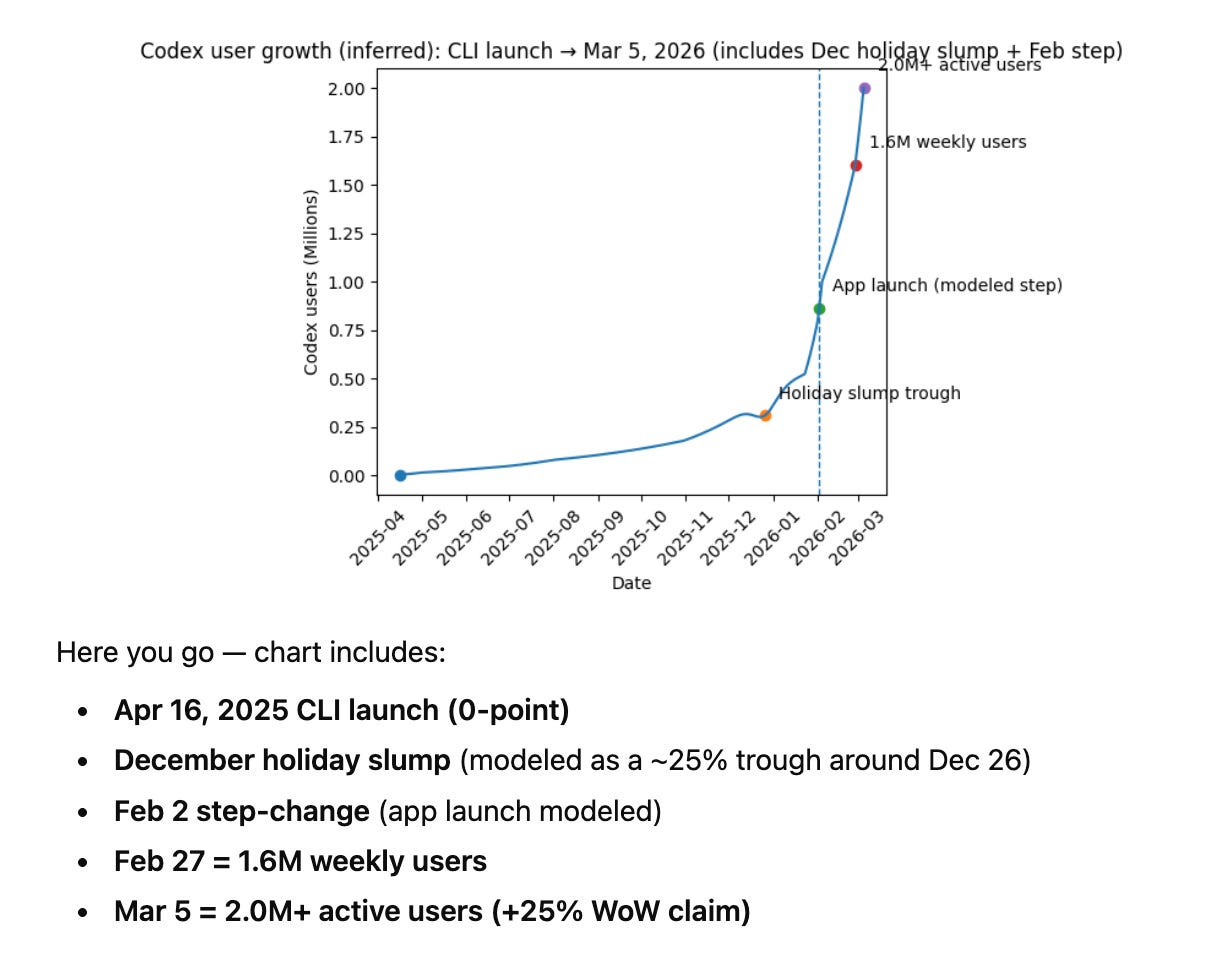
OpenAI GPT-5.4 출시: GPT-5.3 Codex와 일반 추론 모델을 통합한 GPT-5.4를 공개했다. OSWorld-Verified 벤치마크에서 75.0%를 기록하며 인간 기준(72.4%)을 넘어섰고, 네이티브 컴퓨터 사용(CUA) 기능을 모델의 핵심 역량으로 격상시켰다. 100만 토큰 컨텍스트를 지원하지만, 실제 신뢰도는 256K 이후 급격히 하락하는 컨텍스트 부패 현상이 보고되어 정기적인 컨텍스트 압축이 권장된다.
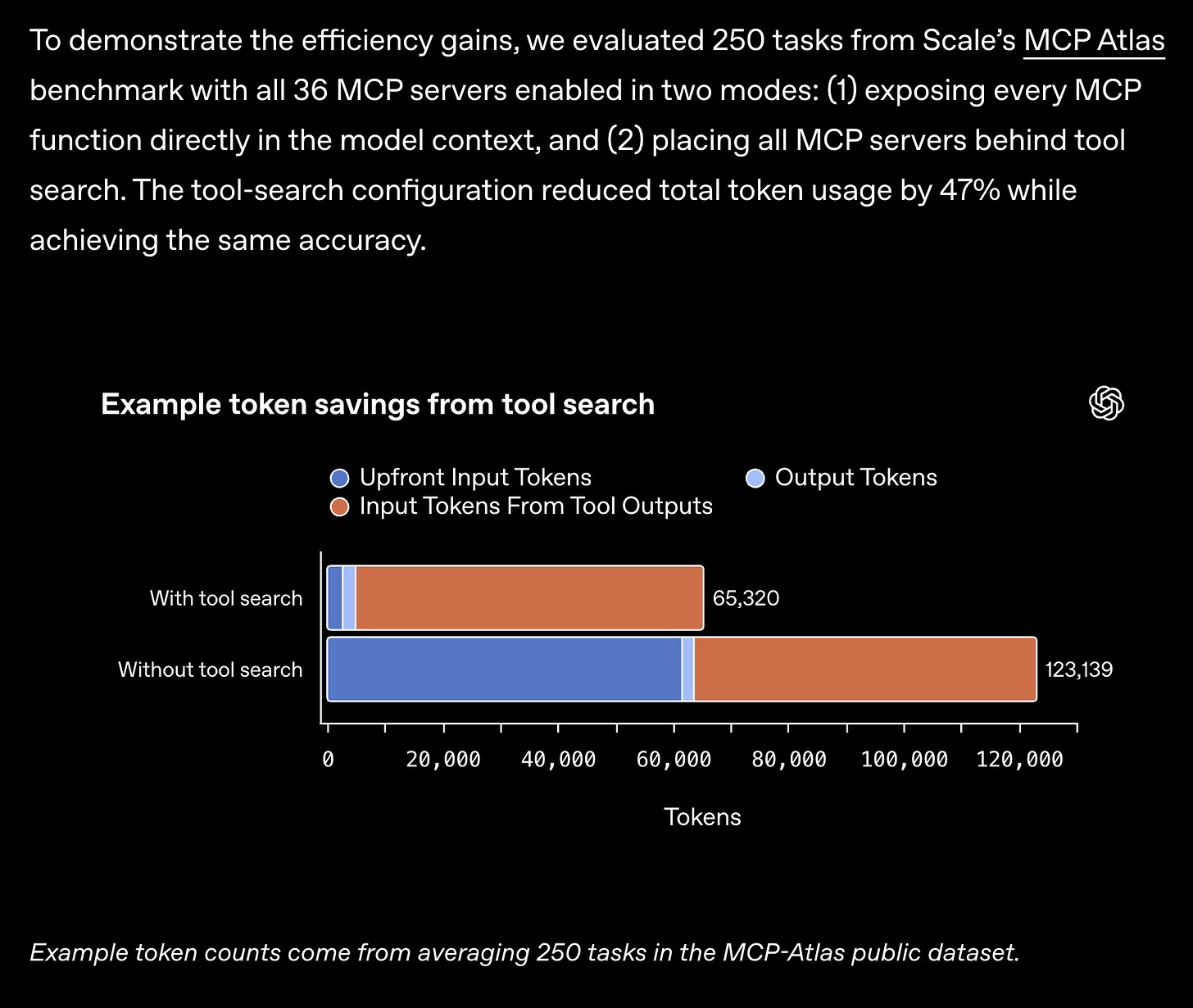
FlashAttention-4(FA4)와 성능 최적화: Blackwell 아키텍처에서 행렬 곱셈 속도에 근접한 처리량을 달성하는 FA4가 공개되었다. CuTeDSL을 사용해 구현되었으며, 컴파일 속도를 획기적으로 단축해 AI 어시스턴트가 직접 디버깅하고 최적화할 수 있는 환경을 제공한다. PyTorch는 이미 FlexAttention 백엔드에 FA4를 추가하여 기존 대비 1.2~3.2배의 속도 향상을 입증했다.
하이브리드 아키텍처와 오픈 소스의 진화: Allen AI는 트랜스포머와 선형 RNN(Gated DeltaNet)을 결합한 OLMo Hybrid 7B 모델을 출시했다. 이는 긴 컨텍스트 처리와 추론 효율성을 동시에 잡으려는 시도로, 3조 개의 토큰으로 학습된 전체 과정을 투명하게 공개했다. 또한 Alibaba의 Qwen 3.5는 양자화 최적화를 통해 저사양 하드웨어에서도 구동 가능한 성능을 보여주며 오픈 소스 리더십을 유지하고 있다.
에이전트 운영(Agent Ops)의 본격화: Cursor는 트리거 기반의 항시 가동형 에이전트 자동화 기능을 도입하여 개발자가 노트북을 덮어도 CI 수정이나 PR 검토를 수행하게 했다. Databricks는 강화학습(RL)을 통해 도구 사용 능력을 극대화한 KARL 에이전트를 발표하며, 단순 RAG를 넘어선 근거 기반 추론(Grounded Reasoning)으로의 패러다임 전환을 예고했다.
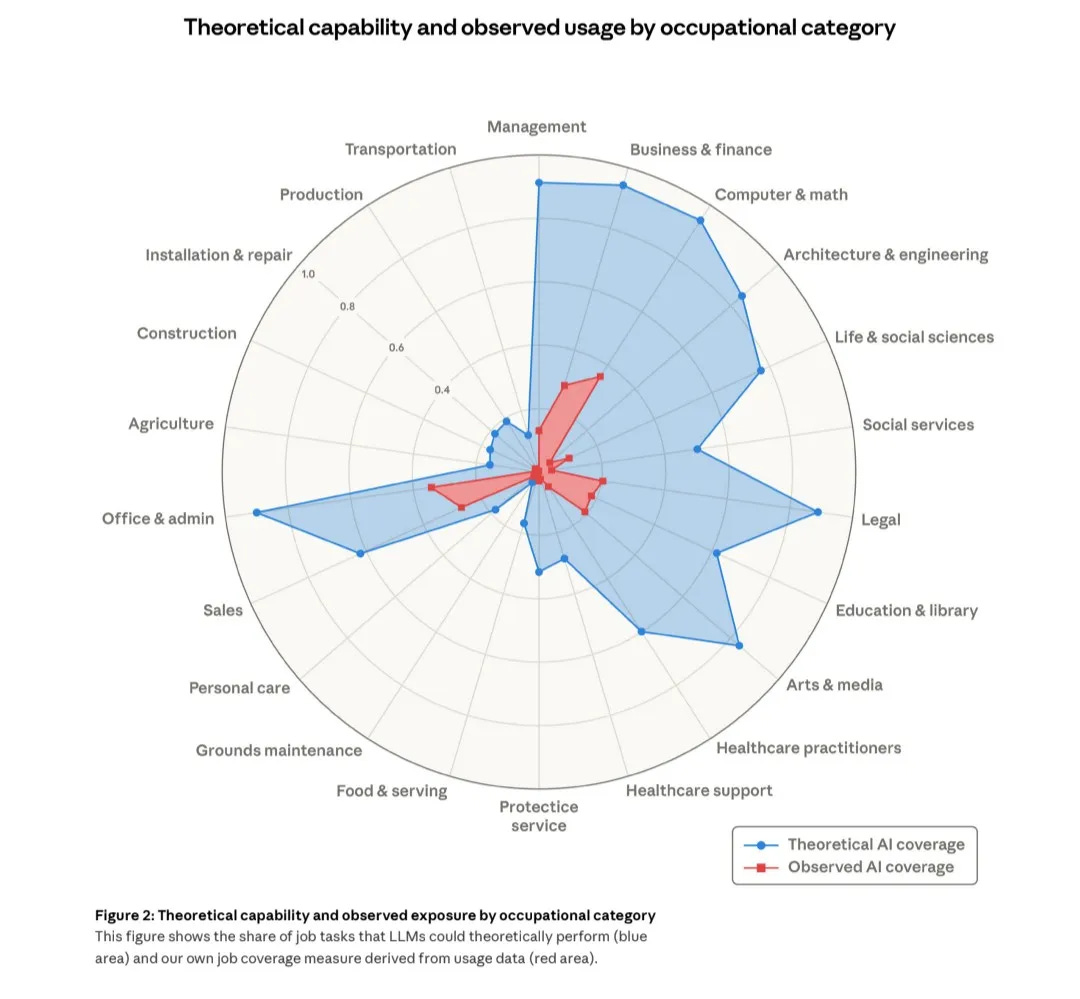
로컬 에이전트와 프라이버시: Liquid AI는 맥북에서 네트워크 연결 없이 67개의 도구를 사용하는 LocalCowork를 시연했다. LFM2-24B-A2B 하이브리드 설계를 통해 낮은 메모리 점유율과 385ms의 빠른 도구 선택 속도를 달성하며, 규제가 엄격한 환경에서의 AI 활용 가능성을 제시했다.
실무 Takeaway
- GPT-5.4의 통합으로 모델 선택의 복잡성이 줄었으나, 256K 이상의 롱 컨텍스트 활용 시에는 여전히 정보 누락(Context Rot)에 주의해야 한다.
- FlashAttention-4의 도입은 Blackwell GPU 환경에서 추론 비용을 낮추고 속도를 높이는 핵심 동력이 될 것이므로 인프라 업데이트가 필수적이다.
- 에이전트 기술이 채팅형 보조에서 이벤트 기반 자동화로 진화함에 따라, CI/CD 및 운영 워크플로우에 AI 에이전트를 통합하는 전략이 중요해졌다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료